李里:在安装TensorFlow后,先来查看一下你的TensorFlow的版本号看看是否安装的TensorFlow开发环境可用。
| #输出版本号 import tensorflow as tf print("TensorFlow Version is "+tf.__version__) #输出 >>>TensorFlow Version is 1.4.0 |
李里:下面设置TensorFlow Log用于程序分析Code,没有任何日志的输出,模型训练感觉就像发生在一个黑盒子中,无法知道发生了什么事情,比如程序现在参数的状态,训练过程损失值是否是收敛的,当前的模型预测评估值等等。幸运的是,tf.contrib.learn提供了一个解决方法Monitor API,该API被设计用来帮助程序在运行中间过程里记录信息和验证模型。接下来你将学习到TensorFlow上如何如何有效记录日志,设置ValidationMonitor来做流验证,并且使用TensorBoard来可视化你的信息。TensorFlow对于日志信息有五个不同的级别,分别是DEBUG,INFO,WARN,ERROR和FATAL,名称表明了它们的输出级别。程序的输出根据你日志设定级别进行过滤,TensorFlow只会输出与这个级别相关的、以及更高级别的所有日志文件。例如,你设置了一个ERROR级别的日志,那么你得到的输出日志信息将包括ERROR和FATAL,如果设置的级别是DEBUG,你将会得到所有5个级别的日志信息。默认情况下,TensorFlow设置成WARN级别的日志,但是当跟踪模型训练时,建议可以调整级别到INFO。设置日志的代码只需一行即可,放在程序的初始化部分即可:
| #设置Tensoflow日志级别 tf.logging.set_verbosity(tf.logging.INFO) |
李里:接下来了解一下Tensor又名张量,从TensorFlow的名称就能看出Tensor概念的重要性了。一个Tensor是一些带有shape的数据集合,shape是指类似于矩阵的维数,一个Tensor的rank就是这个Tensor的维度,现在将Tensor打印出来看看其在系统中的存在形式。
| #打印Tensor内容 import tensorflow as tf print("TensorFlow Version is "+tf.__version__) tf.logging.set_verbosity(tf.logging.INFO) """ 创建一个Rank为1,常量为3,类型为float的tensor """ tensor1 = tf.constant(3.0,dtype=tf.float32) """ 输出:Tensor("Const:0", shape=(), dtype=float32) """ print("Tensor is :"+ str(tensor1)) |
高维:奇怪啊,我运行代码后没有预期的输出Const:3,而是输出的是Const:0,是不是那里赋值异常了?
李里:不要疑惑这里就将引出TensorFlow的第二个概念:计算图。TensorFlow 模型框架由两部分构成:1.构建计算图,这里主要定义图中的节点,计算方式,流程串接等。2.运行计算图,运行计算图需要先定义一个Session,这个session封装了TensorFlow的所有控制与状态,只有运行Session时才是真正去运行计算图并得到结果。
定义Session与运行:
| #使用Session运行 """ 输出:Tensor is 3 """ sess = tf.Session() print("Tensor is :"+ str(sess.run(tensor1))) |
李里:Tensor既然是有值的,那么是否可以对Tensor进行计算呢,我们尝试一下加法。
| #对Tensor进行加法运算 tensor_add = tf.add(tensor1,tensor1) print("Tensor op:",tensor_add) print("Tensor op(session):",sess.run(tensor_add)) |
高维:我终于得到运行结果了,通过结果看到加法在TensorFlow里面被定义为Add:0的操作,运行后得到了6这个结果。
![]()
图3.5.2.1 加法运算输出
李里:上面主要使用的Constant这个常量来定义初始值并进行计算,但在实际应用中会以用户交互式变量为主,那么如何定义交互式变量呢?示例:输入值x分别是1,2,3,4,公式为 y = 3*x +(-3),计算结果。
| #定义交互式变量 #定义W=0.3,b=-0.3,线性模型为y=w*x+b,其中x为输入变量 W = tf.Variable([.3],dtype=tf.float32) b = tf.Variable([-.3],dtype=tf.float32) x = tf.placeholder(tf.float32) linear_model = W*x + b #tf.global_variables_initializer()是讲TensorFlow sub-graph初始化 #所有全局变量,在允许sess.run之前,所有编码都是没有初始化的 sess.run(tf.global_variables_initializer()) print("linear_model: ",sess.run(linear_model,{x:[1,2,3,4]}))
#输出: linear_model:[ 0. 0.30000001 0.60000002 0.90000004] |
李里:这时已经建立起了一个线性模型,但并不知道这个模型是否足够好,所以在用训练数据建立模型时,先要用已知结果和模型计算出的结果进行比较,并得到一个损失值,这个损失值就是正确结果与计算结果的误差,要通过算法等手段来尽量减少这个误差,使模型的结果更加贴近真实值。
| #损失值计算 #真实值输入 y= tf.placeholder(tf.float32) #使用方差来计算真实值与计算值的损失值 squared_deltas = tf.square(linear_model - y) #将所有的方差值求和,得到总体的损失值 loss = tf.reduce_sum(squared_deltas) print("loss1 : ",sess.run(loss,{x:[1,2,3,4],y:[0,-1,-2,-3]})) print("loss2 : ",sess.run(loss,{x:[1,2,3,4],y:[0,.3,.6,.9]})) #损失值计算输出: loss1 :23.66 loss2 :3.55271e-15 |
李里:可以看到loss2明显小于loss1,因为第二组的y的输入和模型计算结果更接近,在之前的学习中我们知道需要在训练中不断的自动降低损失值来达到模型的最大优化,这时需要增加损失函数优化算法来不断调整参数以达到自动最小化损失值。下面例子中采用了梯度下降算法来实现损失值最小化,TensorFlow作为机器学习的神器自然在这方面封装的非常简单。
| #使用梯度下降方法优化损失值 #定义梯度下降优化器,参数0.01为学习率 optimizer = tf.train.GradientDescentOptimizer(0.01) #算法操作为最小化损失值 train = optimizer.minimize(loss) #进行1000轮优化 for i in range(1000): sess.run(train,{x:[1,2,3,4],y:[0,-1,-2,-3]}) #经过1000轮优化后,查看变量W,b的变化值 print(sess.run([W,b])) #输出,W= -1,b=1为模型损失最小化参数: [array([-1.], dtype=float32), array([1.], dtype=float32)] |
|
|
李里:在学习了基本TensorFlow语法和开发步骤后,请大家都手敲一遍MNIST的示例代码,了解TensorFlow的开发规范:
| #通过TensorFlow下载MNIST数据库 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) #读取MNIST数据集,运行代码将数据读取进入内存 from TensorFlow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/mnist/", one_hot=True) #基于公式:Y = softmax(Wx+b)建立模型并评估 from TensorFlow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/mnist/", one_hot=True) """ 训练 """ import TensorFlow as tf x = tf.placeholder(tf.float32,[None,784]) y_ = tf.placeholder(tf.float32,[None,10])
W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,W)+b) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) train_op = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.InteractiveSession() tf.global_variables_initializer().run()
for _ in range(1000): batch_xs,batch_ys = mnist.train.next_batch(100) sess.run(train_op,feed_dict={x:batch_xs,y_:batch_ys}) """ 评估 """ correct_pred = tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) print('Accuracy : ',sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
#输出: Accuracy : 0.919
|
3.5.3 TensorFlow实现神经网络
李里:使用线性模型的MNIST预测准确率已经达到了接近92%,在该领域中还算个不错的结果,下面将尝试机器学习中的卷积神经网络来测试是否能将准确率更加提高一些,卷积神经网络是深度学习技术中应用最广泛的网络结构之一,其在图像处理领域取得了巨大的领先优势,在ImageNet数据集竞赛上,基于CNN的多个模型都取得了不错的成绩。CNN相较于传统的图像处理算法的优点之一在于避免了对图像复杂的前期预处理过程(提取人工特征等),可以直接输入原始图像,另外卷积神经网络也常被用于自然语言处理。 CNN的模型被证明可以有效的处理各种自然语言处理的问题,如语义分析、搜索结果提取、句子建模、分类、预测和其他传统的NLP任务等,请大家先阅读培训资料。
卷积神经网络培训资料:
卷积神经网络(Convolutional Neural Network, CNN)是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。 K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。[1]
CNN一般包含两种类型层,分别是卷积层和池化层,卷积层的作用是提取图像的各种特征;池化层的作用是对原始特征信号进行抽象,从而大幅度减少训练参数,另外还可以减轻模型过拟合的程度。
卷积层:卷积神经网络中每个卷积层都是由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法损失最小得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
池化层:通过卷积层获得了特征之后,理论上可以直接使用这些特征训练分类器(如softmax),但是这样做将面临巨大的计算量的挑战,而且容易产生过拟合的现象。为了进一步降低网络训练参数及模型的过拟合程度,对卷积层进行池化处理,本质是降采样。池化的方式通常有以下两种:
- Max-Pooling: 选择Pooling窗口中的最大值作为采样值
- Mean-Pooling: 将Pooling窗口中的所有值相加取平均,以平均值作为采样值
下面为根据表3.5.3.1的卷积神经网络的设计流程图完成MNIST的分类设计。
|
|
Conv1 : 第一个卷积层 Pool1 : 第一个池化层 Conv2 : 第二个卷积层 Pool2 : 第二个池化层 Fc1 : 全连接层 Dropout:数据概率丢失,用于防止在数据量过小的情况下,结果过拟合 Fc2 : 全连接 Loss : 损失值
|
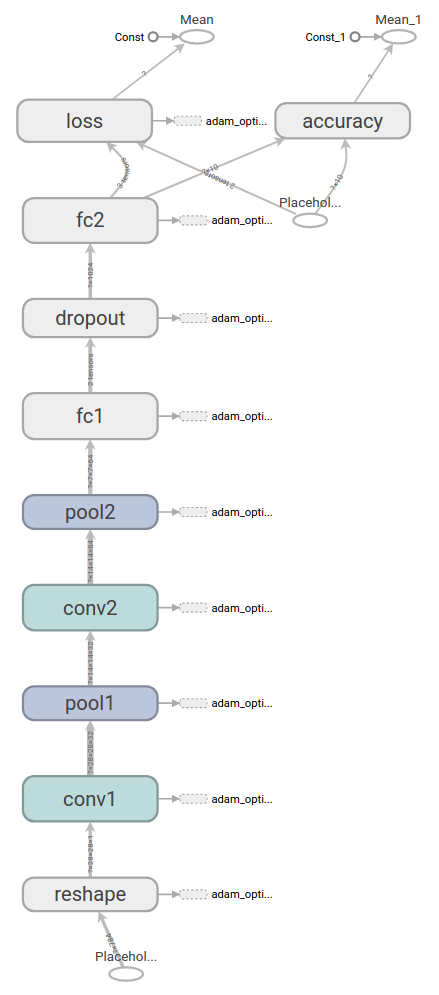
表3.5.3.1的卷积神经网络的设计流程图
建立CNN模型先要创建分类算分函数softmax用到的权值W和偏置b等参数,这些参数初始化时最好不要都设为0,容易发生数据拟合,设为很小的正值即可。
#定义softmax用到的权值和偏置值 def weight_variable(shape):
def bias_variable(shape):
|
利用TensorFlow提供的API封装卷积和池化操作。
#封装卷积与池化函数 def conv2d(x, W):
def max_pool_2x2(x):
|
TensorFlow卷积函数说明:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
- 参数input:指需要做卷积的输入数据,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,其含义是[batch的数据数量,数据高度,数据宽度, 数据通道数],要求类型为float32和float64其中之一
- 参数filter:CNN中的卷积核,类型为Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,数据通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
- 参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
- 参数padding是string类型的变量,只能是"SAME","VALID"其中之一,这个值决定了对于卷积部分的填充方式。
- 参数use_cudnn_on_gpu:是否使用cudnn加速,布尔类型,默认为true
- 结果返回一个Tensor,这个输出,就是常说的feature map
TensorFlow池化函数说明:
tf.nn.max_pool(value, ksize, strides, padding, name=None)
- 参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
- 参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为一般不在batch和channels上做池化,所以这两个维度通常是1
- 参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
- 参数padding:和卷积类似,可以取'VALID' 或者'SAME'
- 结果返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
这里的卷积和池化函数都有用到padding这个参数,该参数取值为VALID时,若剩余需要填充的窗口小于滑动窗口时直接忽略不再填充,而取值为SAME时则将小于滑动窗口的部分全部填充0。
卷积与池化层操作,为了使得图片与计算层匹配,首先reshape输入图像为4维的tensor,第2、3维对应图片的宽和高,最后一维对应颜色通道的数目,卷积层根据LeCun模型设定为32个特征映射(feature map),对每个5 * 5的滑动窗口。它的权值tensor的大小为[5, 5, 1, 32]。 前两维是滑动窗口的大小,第三维是输入通道的数目,最后一维是输出通道的数目。对每个输出通道加上了偏置(bias),最后使用weight tensor与x_image进行卷积计算,加上bias,再使用ReLU激励函数和最大池化,每层卷积神经网络都是这样的卷积与池化的操作。
| #卷积与池化层操作
W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) |
在输出层为了减少过拟合模型采用Dropout来随机丢弃一些神经元的输出,这个比例可以自行设定,最终的经过Dropout的结果经由softmax算法进行0~9类别的概率输出。
Softmax算法说明:
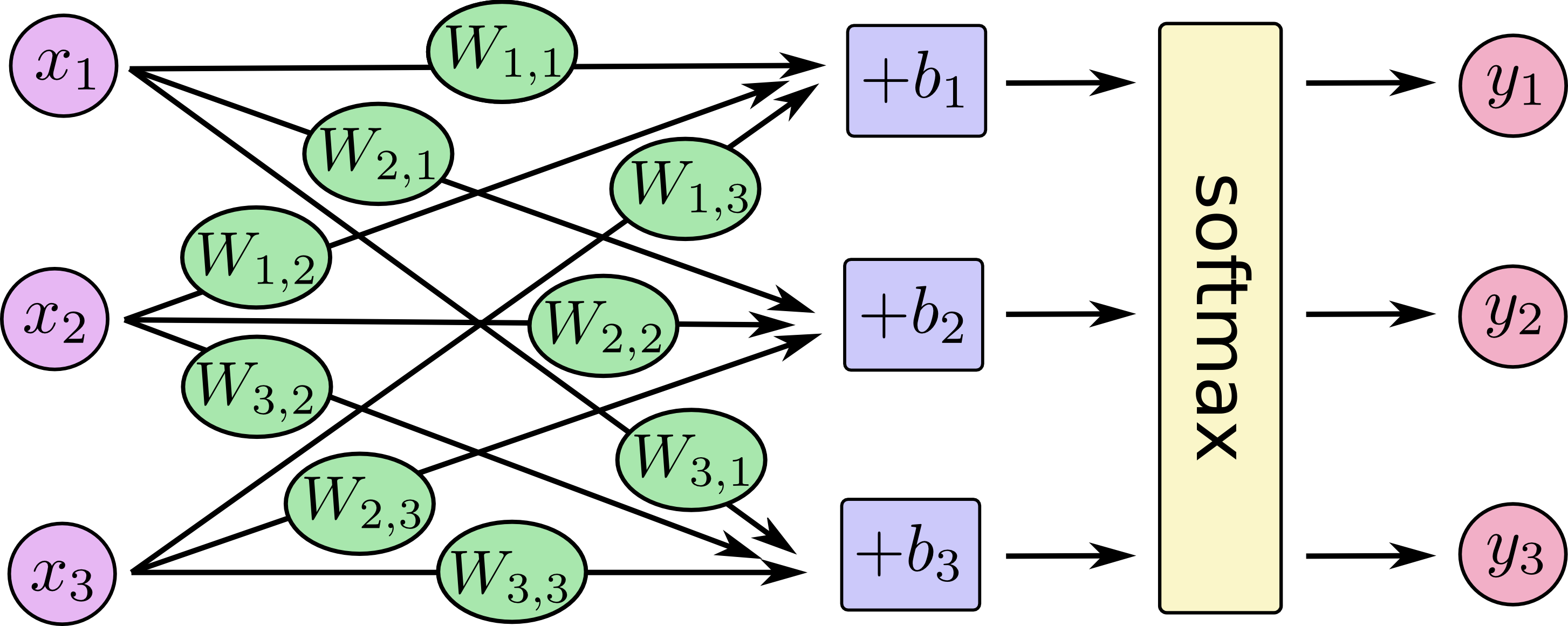
分类算法有很多,对每个可能结果都要评分的,可以选择Softmax算法,softmax是将原来输出值通过softmax函数作用后,映射成为(0,1)的值,而这些值的累和为1(归一化,符合概率特征),那么可以将它理解成概率,在最后选取输出的时候,模型选取概率最大(也就是值对应最大的)结点,作为输出的结果,表3.5.3.2说明以Softmax为算法的模型流程图。
|
X为输入,W为权重,b为偏差值,softmax为激活函数,y为输出 |
|
代入矩阵与公式Wx+b |
|
矩阵运算,计算公式Y = softmax(Wx+b) |


| #输出层 #dropout
|
卷积网络模型建立成功后,采用之前提到的损失优化函数来对训练结果进行优化,以此来达到最小损失率,这里共执行20000次数据的批数据读取与优化损失值,这里也可以设定当损失值达到一定预设值时停止。
| #批数据读取与损失优化函数 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) #通过上述卷积操作,最后使用公式W*x+b得到最终结果 y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
cross_entropy = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv)) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(20000): batch = mnist.train.next_batch(50) if i % 100 == 0: #这里需要注意的是batchp[0]和batch[1],这种写法和 #上一章batch_xs,batch_ys = mnist.train.next_batch(100) #是一样的,只是本章放在了一个数组里,通过索引来获得对应变量 train_accuracy = accuracy.eval(feed_dict={ x: batch[0], y_: batch[1], keep_prob: 1.0}) print('step %d, training accuracy %g' % (i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={ x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
|
完成了MNIST的模型建立与训练验证后,在模型应用时只需将需要预测的数据输入即可,但程序运行则需要每次都是从读取训练集开始,经过漫长的训练才能到达实际预测的步骤,这样的效率在实际应用场景下是不可以的,正确的做法是把训练的模型保存起来,应用直接引导模型就可以开始预测了,TensorFlow提供了对应的函数tf.train.Saver()来实现模型的存储与读取。以下示例用以展示如何应用模型的存储与引导。
TensorFlow模型的存储与引导:
| """ 初始化Saver,限制只保存最新的5个checkpoint """ saver = tf.train.Saver(max_to_keep=5) sess = tf.InteractiveSession() tf.global_variables_initializer().run()
for i in range(1000): batch_xs,batch_ys = mnist.train.next_batch(100) sess.run(train_op,feed_dict={x:batch_xs,y_:batch_ys}) saver.save(sess, './model/mnist/', global_step=i) """ 建立一个新的Session,用于从之前的最新的checkpoint恢复,并执行验证 """ _sess = tf.InteractiveSession() if tf.train.checkpoint_exists('./model/mnist/'): latest_check_point = tf.train.latest_checkpoint('./model/mnist/') saver.restore(_sess, latest_check_point)
|
在运行上述代码完成存储后,去./model/mnist目录查看模型存储的形态,如图3.5.3.1这里会发现只有编号为995~1000的五个模型,原因是TensorFlow默认的设定只保存最新五个的模型,当然这个数值是可以设定的,但一般都采用最后生成的模型所以保持默认五个模型已经足够了。

图3.5.3.1 TensorFlow模型保存
高维:好复杂的程序呀,需要写的代码太多了。
李里:建议虽然有很多封装的非常棒的机器学习套件,如Keras,sklearn等,但还是建议先从最基础的底层API开始用起来,这样才能更好的理解机器学习程序架构,再去使用Hi-Level API时才知道其所以然,不会面对一堆参数茫然不知所措。
高维:难道TensorFlow没有有封装更好的API么?
李里:当然有Hi-Level API用于简化开发。
[1] https://baike.baidu.com/item/卷积神经网络