自编码算法定义:AutoEncoder(AE)是一个无监督学习模型,它利用反向传播算法,让模型的输出等于输入。
高维和我看到这个定义一头雾水,输出等于输入,那这个模型用来做什么啊?
路思打开维基百科关于AutoEncoder的解释。
维基百科对定义的解释:自动编码机将神经网络的隐含层看成是一个编码器和解码器,输入数据经过隐含层的编码和解码,到达输出层时,确保输出的结果尽量与输入数据保持一致,图2.2.2.1展示的是AutoEncoder的过程。
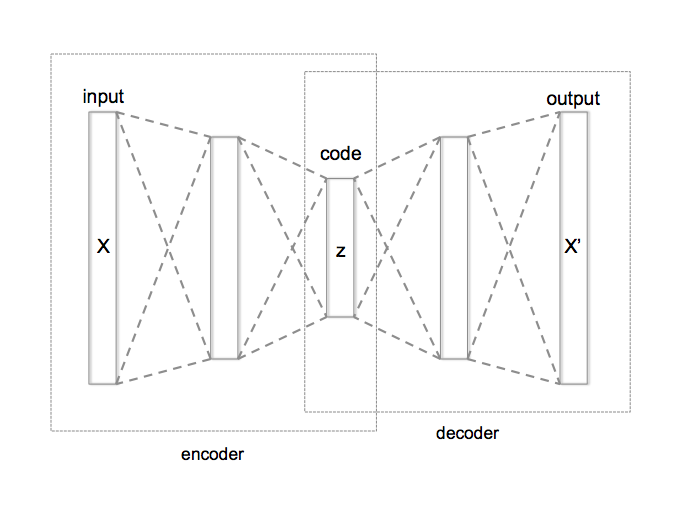
图2.2.2.1[1]
路思直到看到AutoEncoder编码有压缩数据的功能时,豁然开朗,说:我明白了,这样做的一个好处是,中间的层Code能够抓住输入数据的特点,使其特征保持不变。例如,假设输入层有100个点,中间层只有50个点,输出层还是100个点,通过自动编码器算法,只用中间层的50个点就找到了100个输入层数据的特点,能够保证输出数据和输入数据大致一致,就大大降低了特征层的维度,这样对于AutoEcoder可以用于数据的降维和特征抽取。
安逸:恩, AutoEncoder定义的结构分为输入层,隐藏层和输出层,这里的隐藏层的维度要远远小于输入层来达到压缩的目的,而输出层则要重构输入层,重构输入的数据来源则是隐藏层提供的,所以对照图2.2.2.1,我们将输入层进行压缩到隐藏层的过程称为encoder编码,把从隐藏层到输出层重构数据的过程称为decoder解码,在构建模型时同时也需要不断的将预测数据与期望数据做调整来达到最小误差,我把这个过程画成了图2.2.2.2。
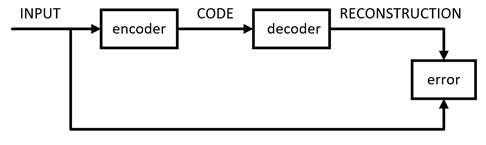
图2.2.2.2
高维:你们讲的还是太理论了,我接着用客户分析的例子理解一下,你们看看对不对。之前在K-Means算法中要将客户分类需要大量的属性,如一些基础属性年龄,性别,城市,月薪等,还有很多个性特征属性如旅行次数,微博活跃度,日均上网时间等等,这会造成特征爆炸,当成百上千的属性出现时,对甄别出的用户进行特征描述成了问题。如果按照AutoEncoder的思路,我们可以将这大量的特征进行压缩,而这些压缩过特征又能还原回原有客户群,这样,我们只需对这些压缩特征进行分析即可。
路思:是的,AutoEncoder不但能降维压缩,通过你的例子还可以看到该算法还能去噪,比如一些对客户分类有影响的属性都会在算法中被过滤掉的。
安逸:只是这样得到的隐藏层的特征都不像原始特征那样变得可以读懂了。
高维:AutoEncoder算法将客户的特征变得不可描述了,这样对于分析人员不是很直观,而且自定义的隐藏层的节点个数容易造成有效特征丢失的,我在上学时学到过电商的数据都是有很强的相关性的,比如浏览量和访客数,下单数与成交数,这样我们删除强相关性的一个指标对总体分析不会有影响的,所以我想
是否有一种算法可以实现这种降维么?
路思:你的降维思路很好,但是机器学习中一般都不会直接靠删除列来降维,而是通过某些变换将原始数据变为更少的列同时信息丢失的也最少。
[1] By Chervinskii - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=45555552