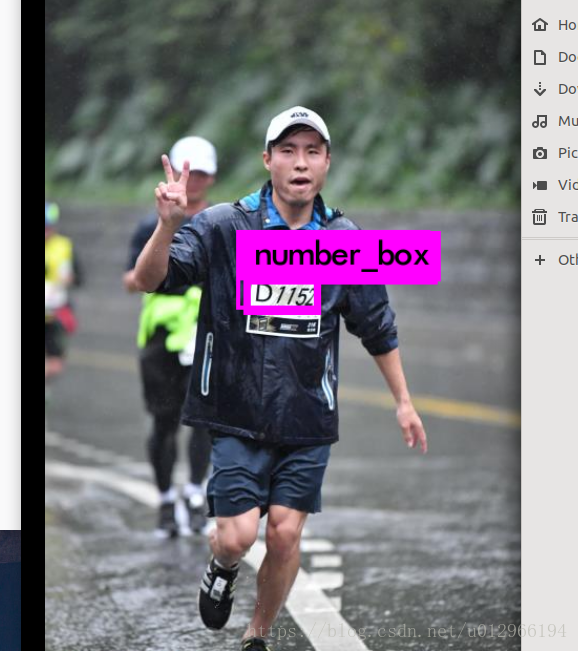
这篇文章将介绍编译darknet框架开始,到整理数据集,到用yolo网络实现一个内部数据集中号码簿的定位。
1. DarkNet的编译
- 当前的环境:亚马逊GPU实例P2:Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz + K80 + Ubuntu16.04
1.1 环境准备:
sudo -i
#先改软件源:
root@ip-****:~# cd /etc/apt/
root@ip-****:/etc/apt# sudo cp sources.list sources.list.bak
root@ip-****:/etc/apt# sudo vi /etc/apt/sources.list
>>>
deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
##测试版源
deb http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiverse
# 源码
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
##测试版源
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiverse
# Canonical 合作伙伴和附加
deb http://archive.canonical.com/ubuntu/ xenial partner
deb http://extras.ubuntu.com/ubuntu/ xenial main
root@ip-****:/etc/apt# sudo apt-get update
#安装rz:
apt install lrzsz
#查看opencv是否可用
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
import cv2 #没有报错说明本机opencv可以使用
nvcc -V #查看cuda是否可用
#下载工程并尝试编译
git clone https://github.com/pjreddie/darknet
cd darknet
vim Makefile:
... GPU=1
... CUDNN=1
... OPENCV=1
make -j4
#下载多线程下载器:
wget https://jaist.dl.sourceforge.net/project/kmphpfm/mwget/0.1/mwget_0.1.0.orig.tar.bz2
tar -xjf mwget_0.1.0.orig.tar.bz2
./build
make -j4
make install1.2 配置ftp服务器:
因为在远程终端环境,有很多测试图片我们看不到,我们就可以用ftp来从web访问这些图片
from pyftpdlib.authorizers import DummyAuthorizer
from pyftpdlib.handlers import FTPHandler
from pyftpdlib.servers import FTPServer
#实例化虚拟用户,这是FTP验证首要条件
authorizer = DummyAuthorizer()
#添加用户权限和路径,括号内的参数是(用户名, 密码, 用户目录, 权限)
authorizer.add_user('user', '12345', '/root', perm='elradfmw')
#添加匿名用户 只需要路径
authorizer.add_anonymous('/root')
#初始化ftp句柄
handler = FTPHandler
handler.authorizer = authorizer
#监听ip 和 端口,因为linux里非root用户无法使用21端口,所以我使用了2121端口
server = FTPServer(('192.168.1.151', 21), handler)
#开始服务
server.serve_forever()如你的服务器没有固定ip的话,在安装lrzsz后,可以使用sz file命令将文件下载下来。
2.数据准备:
先把数据集传上去
因为在公司内网,没有权限设置端口转发。所以不能在本地搭建FTP,然后在服务器上下载。
所以之前安装rz,现在只需要讲数据集压缩打包为zip,然后拖到xshell窗口中即可上传。
然后用unzip+文件名解压。
2.1 DarkNet读取数据的标准:
所有的.xml标签需要按照voc的格式来记录数据,因为后面需要voc_label.py按照这个格式来归一化数据集。
拿到数据后,要先把所有的数据放到一个文件夹中。一类是.xml的voc格式的标签文件,一类是图片文件。
之所以要把标签和数据都放在一个文件夹里是因为,我们要检查是否所有的标签都有对应的数据,或者数据有对应的标签。
我写了一个脚本来处理这件事情,它做的功能是如果有某个文件没有对应的标签或者数据集(我称它为单身文件),就将其删除。最终文件夹内都是情侣文件:
大家用这个脚本的时候需要根据自己的数据集路径稍微修改一下。
'''
清除单身的xml或者jpg
在Windows运行
'''
import os
import os.path
h = 0
a = ''
b = ''
dele = []
pathh = "C:\\Users\\于祥\\Desktop\\pic\\"
#dele.remove(1)
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = sorted(filenames[2])#为了保证按照顺序排列
for filename in filenames:
print(filename)
if h==0:
a = filename
h = 1
elif h==1:
#print(filename)
b = filename
if a[0:a.rfind('.', 1)]==b[0:b.rfind('.', 1)]:
h = 0
#print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print(dele)
for file in dele:
os.remove(pathh+file)
print("remove"+file+" is OK!")
#再循环一次看看有没有遗漏的单身文件
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
if h==0:
a = filename
h = 1
elif h==1:
#print(filename)
b = filename
if a[0:a.rfind('.', 1)]==b[0:b.rfind('.', 1)]:
h = 0
#print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print (dele)
现在这些文件都是情侣文件了。
然后要把图片和标签分开,分别存在Annotations和pic文件下里
2.2 制作box_train.txt 和 box_test.txt文件:
然后我们要将每张数据图片的地址给列出来,放到box_train.txt 和 box_test.txt里,因为不仅归一化脚本要用到box_train.txt来读取文件,DarkNet在训练时也要从中读取文件。
# -*- coding: utf-8 -*-
import os
import os.path
pathh = "/root/darknet/hebing2/pic/"
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
with open ("box_train.txt",'a') as f:
f.write(pathh+filename+'\n')这样,在工程目录下就有一个box_train.txt了。我们选一部分剪切进box_test.txt中。
2.3 然后我们需要用voc_label.py归一化标签
voc_label.py读取数据的格式为以下格式:

数据集文件夹名
|—Annotations #存放xml标签
|—labels #存放DarkNet可以识别的归一化后的标签文件,我后面的脚本会自动创建
|—pic #存放数据集
因为源码中的voc_label.py是针对voc数据集的,无论路径上还是数据格式都和我们自己的数据有出入,所以我们要自己编写voc_label.py来处理自己的数据。比如我的供大家参考:
(我这个数据集标准人员在标注的时候有错误标签了应该是号码簿代号box,他们给标成了号码簿的号码,所以我在41-46行加了一步处理,请大家忽略)
# -*- coding: utf-8 -*-
#此脚本需要执行两次,在91行train_number执行一次,test_number执行一次
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = []
classes = ["box"]
#原样保留。size为图片大小
# 将ROI的坐标转换为yolo需要的坐标
# size是图片的w和h
# box里保存的是ROI的坐标(x,y的最大值和最小值)
# 返回值为ROI中心点相对于图片大小的比例坐标,和ROI的w、h相对于图片大小的比例
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
#对于单个xml的处理
def convert_annotation(image_add):
#image_add进来的是带地址的.jpg
image_add = os.path.split(image_add)[1] #截取文件名带后缀
image_add = image_add[0:image_add.find('.',1)] #删除后缀,现在只有文件名没有后缀
in_file = open('/root/darknet/hebing2/Annotations/'+ image_add+'.xml')
print('now write to: hebing2/labels/%s.txt'%(image_add))
out_file = open('hebing2/labels/%s.txt'%(image_add), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
#加入我的预处理<name>代码:
for obj in root.findall("object"):
#obj.append("number") = obj.find('name').text
obj.find('name').text = "box"
print(obj.find('name').text)
tree.write('/root/darknet/hebing2/Annotations/'+ image_add + '.xml')
size = root.find('size')
# <size>
# <width>500</width>
# <height>333</height>
# <depth>3</depth>
# </size>
w = int(size.find('width').text)
h = int(size.find('height').text)
#在一个XML中每个Object的迭代
for obj in root.iter('object'):
#iter()方法可以递归遍历元素/树的所有子元素
'''
<object>
<name>car</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>141</xmin>
<ymin>50</ymin>
<xmax>500</xmax>
<ymax>330</ymax>
</bndbox>
</object>
'''
difficult = obj.find('difficult').text
#找到所有的椅子
cls = obj.find('name').text
#如果训练标签中的品种不在程序预定品种,或者difficult = 1,跳过此object
if cls not in classes or int(difficult)==1:
continue
#cls_id 只等于1
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
#b是每个Object中,一个bndbox上下左右像素的元组
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if not os.path.exists('hebing2/labels/'):
os.makedirs('hebing2/labels/')
image_adds = open("box_train.txt")
for image_add in image_adds:
image_add = image_add.strip()
print (image_add)
convert_annotation(image_add)
'''voc
wd = getcwd()
for year, image_set in sets:
#如果lebal文件夹中不存在年份文件夹则创建
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
#000034的这种id
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
#2007_test.txt的这种文件
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
#/home/yuxiang/Desktop/darknet/VOCdevkit/VOC2007/JPEGImages/000001.jpg
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
#/VOC%s/ImageSets/Main/train.txt中每一个image_id都要被执行这个方法
convert_annotation(year, image_id)
list_file.close()
'''如果有个别文件找不到。或者有除0异常的话,去box_train.txt中dd那一行就行。
现在就已经在label/中打好标签了
对于除voc外普通数据集,darknet是会在图片目录下寻找label.txt。进入label/后使用cp * ../pic 整合
3 配置darknet文件:
-
vim cfg/box.data :
… classes = 1
… train = /root/darknet/box_train.txt
… valid = /root/darknet/box_text.txt
… names = data/box.names
… backup = backup -
vim data/box.name:
… box -
cfg/yolov3.cfg:
首先要把net层最顶上两行的Testing注释掉,把Training打开。
后面的Width和height暂时不要懂。因为Yolo行的锚点是根据这个又做了一些聚类算出来的。
里面3个yolo层上面的conv层的filters都要修改,修改公式为3 * (classes + 5)。例如我的就是18
所有的的yolo层class改为1 -
mkdir ./backup
4.训练
./darknet detector train cfg/box.data cfg/yolov3.cfg darknet53.conv.74.0————————
现在就开始训练了。在训练过程中也可以调用一下训练时候阶段输出的权重来测试一下。
使用在/backup中找到每百次的训练权重,然后使用命令测试一下:
./darknet detect cfg/yolov3.cfg backup/yolov3_801.weights -thresh 0时候会让你输入图片地址,当然你也可以在参数上加上图片地址。
训练时我们可以再开一个终端,通过nvidia-smi命令来查看cuda和显存的使用情况
5.DarkNet的Python接口:
注意使用Python测试的时候必须要有GPU和安装好cuda驱动,因为作者提供的Python的接口只有GPU调用函数
作者给出的使用的Demo为:
# Stupid python path shit.
# Instead just add darknet.py to somewhere in your python path
# OK actually that might not be a great idea, idk, work in progress
# Use at your own risk. or don't, i don't care
import sys, os
sys.path.append(os.path.join(os.getcwd(),'python/'))
import darknet as dn
import pdb
dn.set_gpu(0)
net = dn.load_net("cfg/yolo-thor.cfg", "/home/pjreddie/backup/yolo-thor_final.weights", 0)
meta = dn.load_meta("cfg/thor.data")
r = dn.detect(net, meta, "data/bedroom.jpg")
print r
# And then down here you could detect a lot more images like:
r = dn.detect(net, meta, "data/eagle.jpg")
print r
r = dn.detect(net, meta, "data/giraffe.jpg")
print r
r = dn.detect(net, meta, "data/horses.jpg")
print r
r = dn.detect(net, meta, "data/person.jpg")
print r我们不难看出除了系统模块之外,只调用了darknet.py模块,存放在工程的python目录里。
但darknet.py中有一些路径是软地址要改一下(在47行中,仿照着注释的格式):
#lib = CDLL("/home/pjreddie/documents/darknet/libdarknet.so", RTLD_GLOBAL)
lib = CDLL("libdarknet.so", RTLD_GLOBAL)但这个模块是基于Python2编写,如果直接使用Python2运行的话还会有一些包存在路径问题,哪我们不如将他稍微修改一下:
在154行,即最后一行中,print需要加上括号
print (r)这样,我们在工程目录下进行模块导入就没有任何问题了。
我们仿照着把配置文件路径和要测试的图片地址改好就可以了。比如我的:
In [10]: dn = set_gpu(0)
...: net = dn.load_net("cfg/yolov3.cfg", "/home/pjreddie/backup/yolov3_400.weights", 0)
...: meta = dn.load_meta("cfg/number.data")
...: r = dn.detect(net, meta, "zhebing/pic/20171105_636454947681503257_P.jpg")
...: print (r)就可以显示出测试图像啦。