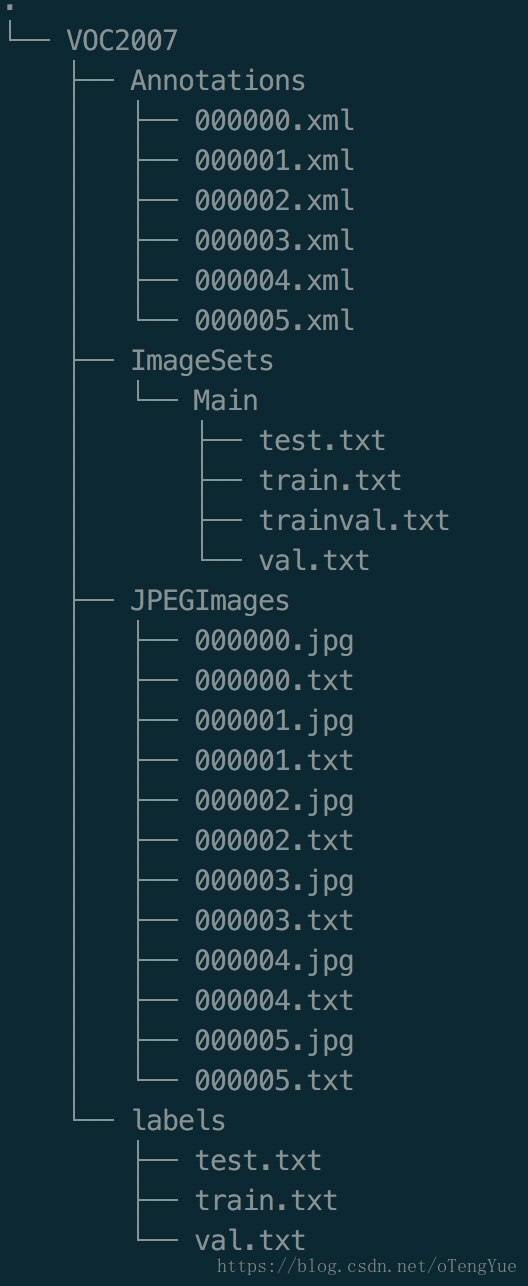
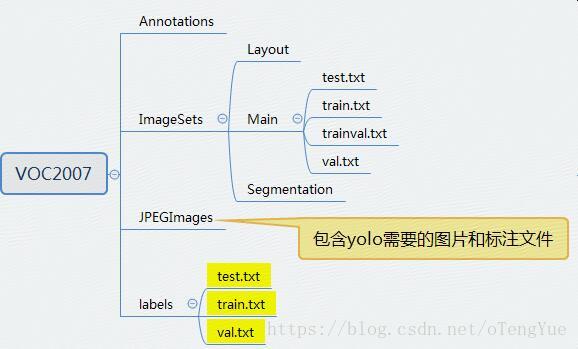
采用yolov3训练目标检测模型第一步也是生成训练数据,本文提供一种从faster-rcnn训练数据到yolov3训练数据的方式,由于faster-rcnn的训练数据为VOC标注文件格式,这种数据比较容易获取,而采用原作者github的yolov3的训练数据是独有的,所以需要进行一步转换。由原始的VOC标注文件转换为faster-rcnn训练数据博文详见:faster-rcnn之生成训练数据,本文是在其基础上进一步生成的。首先同样看生成后的结构图:
代码如下:label_rcnn2yolo.py
# coding=utf-8
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
class LabelRcnn2yolo:
def __init__(self, voc_root_dir, txts, clss):
self.voc_root_dir = voc_root_dir
self.voc_labels_dir = os.path.join(self.voc_root_dir, 'labels')
if not os.path.exists(self.voc_labels_dir):
os.mkdir(self.voc_labels_dir)
self.txts = txts
self.classes = clss
def convert(self, size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(self, image_id):
in_file = open('%s/Annotations/%s.xml' % (self.voc_root_dir, image_id))
out_file = open('%s/JPEGImages/%s.txt' % (self.voc_root_dir, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text.encode('utf-8')
if cls not in self.classes or int(difficult) == 1:
continue
cls_id = self.classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = self.convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def rcnn2yolo(self):
for txt in self.txts:
image_ids = open('%s/ImageSets/Main/%s.txt' % (self.voc_root_dir, txt)).read().strip().split()
list_file = open(os.path.join(self.voc_labels_dir, txt + '.txt'), 'w')
for image_id in image_ids:
list_file.write('%s/JPEGImages/%s.jpg\n' % (self.voc_root_dir, image_id))
self.convert_annotation(image_id)
list_file.close()
if __name__ == '__main__':
voc_root_dir = r'/Users/songhongwei/data/cashier/tmp/VOC2007'
txts = ['train', 'val', 'test']
classes = ['1_红牛','3_绿茶','4_可口可乐']
labelRcnn2yolo = LabelRcnn2yolo(voc_root_dir,txts,classes)
labelRcnn2yolo.rcnn2yolo()说明:
1、yolo生成标注文件内容说明如下:

具体的每一个值的计算方式是这样的:假设一个标注的boundingbox的左下角和右上角坐标分别为(x1,y1)(x2,y2),图像的宽和高分别为w,h
归一化的中心点x坐标计算公式:((x2+x1) / 2.0-1)/ w
归一化的中心点y坐标计算公式:((y2+y1) / 2.0-1)/ h
归一化的目标框宽度的计算公式: (x2-x1) / w
归一化的目标框高度计算公式:((y2-y1)/ h
参考:https://blog.csdn.net/u012135425/article/details/80294884
2、生成的yolo标注文件是放在JPEGImages目录下的,经尝试放在其他目录下无法进入训练。
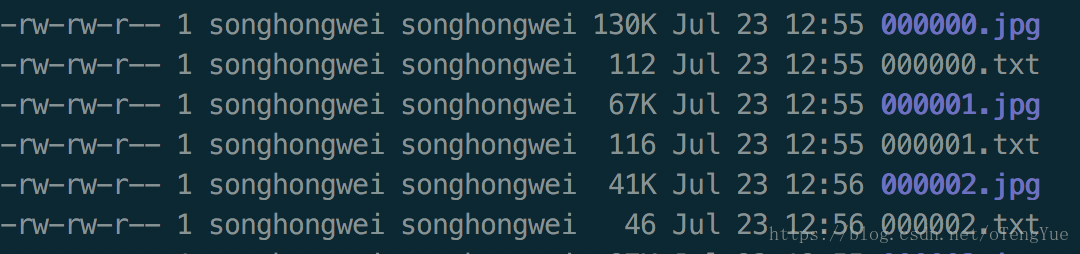
3、labels下的txt文件中每行记录的是图片的绝对路径
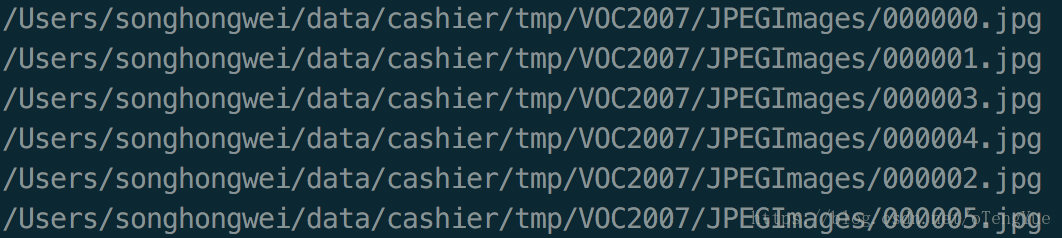
4、最终文件路径结构图(五张标注图片)