通过树型结构的长短期记忆网络改进语义表示
https://arxiv.org/pdf/1503.00075.pdf
Kai Sheng Tai,Richard Socher *,Christopher D. Manning
斯坦福大学计算机科学系,* MetaMind Inc.
[email protected],richard @ metmind.io,manning @ stanford.edu
摘要 由于长短期记忆(LSTM)网络是一种具有更复杂计算单元的递归神经网络,因其具有更强的随时间保存序列信息的能力,因此在各种序列建模任务中获得了强有力的结果。迄今为止探索的唯一潜在LSTM结构是线性链。
然而,自然语言表现出自然地将单词与短语结合的句法属性。 我们介绍了Tree-LSTM,它是LSTM到树状结构网络拓扑的一种推广。 TreeLSTM在两个任务上优于所有现有系统和强大的LSTM基线:预测两个句子(SemEval 2014,Task 1)和情感分类(Stanford Sentiment Treebank)的语义相关性。
1简介
用于短语和句子的分布式表示的大多数模型 - 即,使用实值向量来表示意义的模型 - 属于三个类别之一:词袋模型,序列模型和树结构模型。 在词袋模型中,短语和句子表示独立于词序; 例如,它们可以通过平均构成词表示来生成(Landauer和Dumais,1997; Foltz等,1998)。 相反,序列模型构造句子表示作为令牌序列的顺序敏感函数(Elman,1990; Mikolov,2012)。 最后,树形结构模型根据句子上的给定句法结构,从其构成的子词组成每个短语和句子表示(Goller和Kuchler,1996; Socher等,2011)。
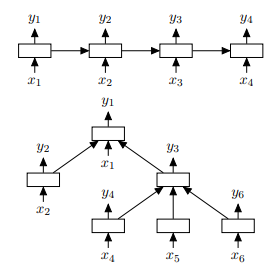
图1:顶部:链结构LSTM网络。 底部:树状结构的LSTM网络具有任意分支因子。

对顺序不敏感的模型不足以完全捕获自然语言的语义,因为它们无法解释由于词序或句法结构的差异导致的意义差异(例如,“猫爬树”与“爬树猫”))。 因此,我们转向有序的顺序或树状结构模型。 特别是,树状结构模型是一种语言上具有吸引力的选择,因为它们与句子结构的句法解释有关。 那么,一个自然的问题是:在多大程度上(如果有的话)我们可以用树状结构模型做得更好,而不是句子表示的顺序模型? 在本文中,我们通过直接比较最近用于实现若干NLP任务中的最新结果的顺序模型类型与其树结构化概括来解决该问题。
由于它们具有处理任意长度序列的能力,递归神经网络(RNN)是序列建模任务的自然选择。最近,具有长短期记忆(LSTM)单元的RNN(Hochreiter和Schmidhuber,1997)由于其在捕获长期依赖性方面的代表性和有效性而重新成为流行的架构.LSTM网络,我们在Sec中查看。 2,已成功应用于各种序列建模和预测任务,尤其是机器翻译(Bahdanau等,2014; Sutskever等,2014),语音识别(Graves et al。,2013),图像标题生成(Vinyals等,2014)和程序执行(Zaremba和Sutskever,2014)。
在本文中,我们介绍了标准LSTM体系结构到树状结构网络拓扑的概括,并展示了它在序列LSTM上表示句子意义的优越性。当标准LSTM从当前时间步的输入和前一时间步中LSTM单元的隐藏状态组成其隐藏状态时,树形结构的LSTM或Tree-LSTM从输入向量组成其状态,并且任意多个子单位的隐藏状态。然后可以将标准LSTM视为Tree-LSTM的特例,其中每个内部节点只有一个子节点。
在我们的评估中,我们证明了Tree-LSTMs的经验强度作为表示句子的模型。我们在两个任务上评估Tree-LSTM架构:电影评论中句子对的语义关联性预测及句子情感分类。我们的实验表明Tree-LSTM在两个任务上都优于现有系统和顺序LSTM基线。我们的模型和实验的实现可以在https://github.com/stanfordnlp/treelstm上找到。
2 长短期记忆网络
2.1概述
递归神经网络(RNN)能够通过在隐藏状态向量ht上递归应用转移函数来处理任意长度的输入序列。在每个时间步t,隐藏状态ht是网络在时间t接收的输入矢量xt及其先前隐藏状态ht-1的函数。 例如,输入矢量xt可以是文本正文中第t个单词的矢量表示(Elman,1990; Mikolov,2012)。隐藏状态ht∈Rd可以被解释为直到时间t观察到的顺序序列的多维分布表示。通常,RNN转移函数是仿射变换,其后是非线性点状函数,例如双曲正切函数:
![]()
不幸的是,具有这种形式的转变函数的RNN的问题在于,在训练期间,梯度向量的组分可以在长序列上呈现指数地增长或衰减(Hochreiter,1998; Bengio等,1994)。梯度爆炸或消失的这个问题使得RNN模型难以学习序列中的长距离相关性。
LSTM架构(Hochreiter和Schmidhuber,1997)通过引入能够长时间保持状态的存储器单元来解决学习长期依赖性的问题。虽然已经描述了许多LSTM变体,但在这里我们描述了Zaremba和Sutskever(2014)使用的版本(arXiv:1410.4615)。
我们在每个时间步骤t将LSTM单元定义为Rd中的向量集合:输入门it,遗忘门ft,输出门ot,存储器单元ct和隐藏状态ht。门控矢量it,ft和ot的取值范围在[0,1]中。我们称之为LSTM的内存维度,LSTM过渡方程式如下:
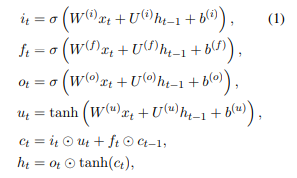
其中xt是当前时间步的输入,σ表示逻辑sigmoid函数并表示元素之间的点乘。直观地,遗忘门控制忘记前一个存储器单元的程度,输入门控制每个单元的更新程度,输出门控制内部存储器状态。
因此,LSTM单元中的隐藏状态向量是单元内部存储器单元状态的门控局部视图。由于门控变量的值对于每个矢量元素而变化,因此模型可以学习在多个时间尺度上表示信息。
2.2变种
两种常用的基本LSTM架构变体是双向LSTM和多层LSTM(也称为堆叠或深LSTM)。
双向LSTM,双向LSTM(Graves等,2013)由两个并行运行的LSTM组成:一个在输入序列上,另一个在输入序列的反向上。在每个时间步,双向LSTM的隐藏状态是前向和后向隐藏状态的串联。此设置允许隐藏状态捕获过去和未来信息。
多层LSTM,在多层LSTM架构中,层中的LSTM单元的隐藏状态在同一时间步骤中用作层+1中的LSTM单元的输入(Graves等,2013; Sutskever等,2014; Zaremba和 Sutskever,2014)。 这里的想法是让多层结构捕获输入序列的长度依赖性。这两种变体可以组合成多层双向LSTM(Graves等,2013)。
3 树结构的LSTM
上一节中描述的LSTM体系结构的局限性在于它们仅允许严格的顺序信息传播。在这里,我们提出了基本LSTM架构的两个自然扩展:Child-Sum Tree-LSTM和N-ary Tree-LSTM。两种变体都允许更丰富的网络拓扑,其中每个LSTM单元能够合并来自多个子单元的信息。
与标准LSTM单元一样,每个Tree-LSTM单元(由j索引)包含输入和输出门ij和oj,存储器单元cj和隐藏状态hj。标准LSTM单元和Tree-LSTM单元之间的区别在于门控向量和存储器单元更新取决于可能许多子单元的状态。另外,TreeLSTM单元不是单个忘记门,而是为每个子k包含一个忘记门fjk。这允许Tree-LSTM单元有选择地合并来自每个子节点的信息。例如,Tree-LSTM模型可以学习在语义相关性中强调语义头,或者它可以学习如何保留情感丰富的子项的表示以用于情感分类。
与标准LSTM一样,每个Tree-LSTM单元采用输入向量xj。在我们的应用程序中,每个xj是句子中单词的向量表示。每个节点的输入字取决于网络使用的树结构。例如,在依赖树上的Tree-LSTM中,树中的每个节点将对应于头字的向量作为输入,而在选区树上的TreeLSTM中,叶节点将相应的字向量作为输入。
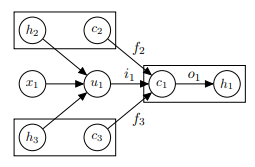
图2:用两个子节点(下标2和3)组成Tree-LSTM单元的存储单元c1和隐藏状态h1。 被剥离的边缘对应于所指示的门控向量的门控,为了紧凑而省略了依赖性。
3.1 Child-Sum Tree-LSTMs
给定一棵树,让C(j)表示节点j的子集。 Child-Sum Tree-LSTM转换方程式如下:

Eq. 4, k ∈ C(j).
直观地,我们可以将这些方程中的每个参数矩阵解释为编码Tree-LSTM单元的分量矢量,输入xj和单元子节点的隐藏状态hk之间的相关性。 例如,在依赖树(依存树的特点:每个节点只有一个父节点,(其中有一个节点的父节点是Root),标点符号不参与依存树分析)应用程序中,模型可以学习参数W(i),使得当语义上重要的内容词(例如动词)时,输入门ij的组件具有接近1的值(即,“打开”)。 当输入是相对不重要的单词(例如确定器)时,给出输入,并且值接近0(即,“关闭”)。
依赖树-LSTM。由于ChildSum Tree-LSTM单元根据子隐藏状态hk的总和调整其组件,因此适用于具有高分支因子或其子项无序的树。 例如,对于依赖树来说,它是一个很好的选择,其中头部的从属数量可以是高度可变的。我们将应用于依赖关系树的Child-Sum Tree-LSTM称为依赖树-LSTM。
3.2 N-ary树-LSTM(N叉LSTM树)
N-ary Tree-LSTM可用于树结构,其中分支因子最多为N,并且子项是有序的,即它们可以从1到N索引。对于任何节点j,写入隐藏状态和存储单元 其第k个孩子分别为hjk和cjk。 N-ary Tree-LSTM转换方程如下:

在Eq。的位置 10,k = 1,2,....。。 ,N。,当树只是一个线性链时,公式(2)-(8)和公式(9)-(14)都减少到标准LSTM计算公式(1)。为每个子k引入单独的参数矩阵允许N-ary Tree-LSTM模型在单元子的状态上学习比ChildSum Tree-LSTM更细粒度的条件。例如,考虑一个选区树应用程序,其中节点的左子节点对应于名词短语,右侧子节点对应动词短语。假设在这种情况下强调动词短语是有利的
在表示中。然后可以训练U(f)k'参数,使得fj1的分量接近0(即“忘记”),而fj2的分量接近1(即“保留”)。
忘记门参数化。在Eq。在图10中,我们定义第k个孩子的遗忘门fjk的参数化,其包含“非对角线”参数矩阵U(f)k`,k 6 =`。此参数化允许更灵活地控制从子级到父级的信息传播。例如,这允许二叉树中的左隐藏状态对右孩子的遗忘门具有兴奋或抑制效果。然而,对于大的N值,这些附加参数是不切实际的并且可以被绑定或固定为零。
选区树-LSTMs。 我们可以自然地将二叉树-LSTM单元应用于二值化选区树,因为区分了左右子节点。 我们将二叉树-LSTM的这个应用称为选区树-LSTM。注意,在选区树-LSTM中,节点j仅在它是叶节点时才接收输入向量xj。在本文的其余部分,我们关注关于依赖树-LSTM和选区树-LSTM的特殊情况。 事实上,这些架构密切相关; 由于我们只考虑二值化选区树,因此两个模型的参数化非常相似。关键区别在于组成参数的应用:依赖树与LSTM的依赖与头部,以及选区树-LSTM的左子与右子。
4 型号
我们现在描述两个具体的模型,它们应用了前一节中描述的树LSTM架构。
4.1树-LSTM分类(看不懂)
在此设置中,我们希望预测标签y树的某些节点子集的离散类集Y. 例如,解析树中节点的标签可以对应于该节点上周期性短语的某些属性。在每个节点j,我们使用softmax分类器来预测标签(怎么预测)yj,给定在节点处观察到的输入{x} j 在根植于j的子树中。分类器将节点处的隐藏状态hj作为输入:

成本函数是每个标记节点上真实类标签y(k)的负对数似然性:
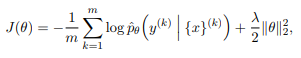
其中m是训练集中标记节点的数量,上标k表示第k个标记节点,λ是L2正则化超参数。
4.2 句子对的语义相关性
给定句子对,我们希望预测某个范围[1,K]中的实值相似度得分,其中K> 1是整数。序列{1,2,...。。 ,K}是一些序数相似度,其中较高的分数表示较大的相似度,并且我们允许实值分数考虑地面实况等级,这是几个人类注释者的评估的平均值。
首先,我们使用树-lstm模型在每个句子的分析树上为每对句子生成句子表示hl和hr。给出这些句子表示,我们使用考虑到它们之间的距离和角度的神经网络来预测相似性得分y。 对(hL,hR):

其中r T = [1 2。。。 K]和绝对值函数按元素应用。 远距离测量h×和h +的使用是凭经验推动的:我们发现该组合优于单独使用任何一种测量。 乘法度量h×可以解释为输入表示的符号的元素比较。
我们希望给定模型参数θ的预测分布pθ下的预期评级接近最佳评级。因此我们定义(1在随后的实验中,我们发现了优化这个目标比平均值产生更好的性能错误目标)p满足稀疏目标分布

5实验
我们在两个任务上评估我们的Tree-LSTM架构:(1)对电影评论中抽样的句子进行情感分类和(2)预测对象的语义相关性。在将我们的Tree-LSTM与顺序LSTM进行比较时,我们通过改变隐藏状态(2对于双向LSTM,前向和后向转换函数的参数是共享的。 在我们的实验中,这实现了双向LSTM的优越性能,具有无权重和相同数量的参数(因此较小的隐藏矢量维度)。)的维数来控制LSTM参数的数量。表1总结了每种模型变体的详细信息。
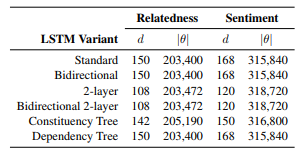
表1:存储器尺寸d和合成功能参数计数|θ| 对于我们评估的每个LSTM变体。
5.1情绪分类
在这项任务中,我们预测从电影评论中抽样的句子的情绪。我们使用Stanford Sentiment Treebank(Socher et al。,2013)。有两个子任务:句子的二元分类,以及五类的细粒度分类:非常消极,消极,中立,积极和非常积极。我们使用6920/872/1821的标准train / dev / test拆分用于二进制分类子任务,使用8544/1101/2210用于细粒度分类子任务(二进制子任务的例子较少,因为排除了中性句子)。为数据集中的每个句子提供标准二值化(二值网络是将权值W和隐藏层激活值二值化1或者-1。通过二值化,使模型的参数占用更小的存储空间;同时利用位移操作来代替网络中的乘法运算,大大降低了运算时间。由于二值网络只是将网络的参数和激活值二值化,并没有改变网络的结构。因此我们主要关注如何二值化,以及二值化后参数如何更新。同时关注一下如何利用二进制位操作实现GPU加速计算的。)选区解析树,并且这些树中的每个节点都用情感标签注释。
对于顺序LSTM基线,我们使用最终LSTM隐藏状态给出的表示来预测短语的情绪。顺序LSTM模型在对应于训练集中的标记节点的跨度上训练。
我们使用4.1节中描述的分类模型。 同时使用(第3.1节)依赖树-LSTM和(第3.2节)选区树-LSTM。选区树-LSTM根据提供的解析树构建。对于依赖树-LSTM,我们生成每个句子的依赖解析; 如果树的每个节点的跨度与训练集中的标记跨度匹配,则为其提供情感标签。
5.2语义相关性
对于给定的句子对,语义相关性任务是预测人类生成的两个句子在意义上的相似性评级。我们使用包含句子的成分知识(SICK)数据集(Marelli et al。,2014),包括在4500/500/4927训练/开发/测试拆分中的9927个句子对。句子来自现有的图像和视频描述数据集。每个句子对用相关性得分y∈[1,5]注释,其中1表示两个句子完全不相关,5表示两个句子非常相关。每个标签是由不同的人类注释器分配的10个评级的平均值。在这里,我们使用4.2节第2部分中描述的相似性模型。对于相似性预测网络(方程15),我们使用大小为50的隐藏层。我们为我们的选区树lstm和相关性tree lstm模型生成数据集中句子的二值化选区分析和相关性分析。
5.3超参数和培训细节
我们模型的超参数在每个任务的开发集上进行了调整。
我们使用公开的300维Glove载体5初始化了我们的单词表示(Pennington等,2014)。 对于情感分类任务,在训练期间更新单词表示,学习率为0.1。 对于语义相关性任务,单词表示被固定,因为我们在调整表示时没有观察到任何显着的改进。
我们的模型使用AdaGrad(Duchi等人,2011)进行训练,学习率为0.05,小批量大小为25.模型参数正规化,每个小批量L2正则化强度为10-4。 使用遮罩(Hinton等人,2012),情绪分类器进一步正规化,遮罩率为0.5。 我们没有使用语义相关性任务的丢失来观察性能提升。
6结论
6.1情绪分类
我们的结果总结在表2中。选区树-LSTM在细粒度分类子任务上优于现有系统,并且实现了与二元子任务中的状态相当的精度。特别是,我们发现它优于依赖树-LSTM。这种性能差距至少部分归因于依赖树-LSTM在较少数据上训练的事实:约150K标记节点而选区树-LSTM为319K。这种差异是由于(1)依赖性表示包含的节点少于相应的选区表示,以及(2)无法将约9%的依赖节点与训练数据中的相应跨度相匹配。我们发现在训练期间更新单词表示(“微调”词嵌入)可以显著提高细粒度分类子任务的性能,并在二进制分类子任务上获得少量的收益(这一发现与此前任务相关的Kim( 2014))。这些收益是可以预期的,因为用于初始化我们的单词表示的向量最初并未训练以捕捉情绪。
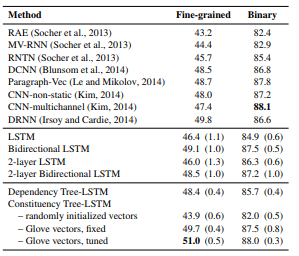
表2:斯坦福情绪树库的测试集准确度。对于我们的实验,我们报告了5次运行的平均精度(括号中的标准偏差)。细粒度:5级情绪分类。 二元:正/负情绪分类。
6.2语义相关性
我们的结果总结在表3中。遵循Marelli等人。 (2014),我们使用Pearson的r,Spearman的ρ和均方误差(MSE)作为评估指标。前两个指标是与人类语义相关性评估相关的度量。
我们将模型与许多非LSTM基线进行比较。平均向量基线将句子表示计算为组成单词的表示的平均值。 DT-RNN和SDT-RNN模型(Socher等人,2014)都将依赖树中的节点的矢量表示组合为仿射变换的子矢量的和,然后是非线性。 SDT-RNN是DTRNN的扩展,其对每个依赖关系使用单独的变换。对于我们的每个基线,包括LSTM模型,我们使用第2节中描述的相似性模型。 4.2。
我们还比较了提交给SemEval 2014语义相关性共享任务的四个表现最好的系统6:ECNU Zhao et al。,2014),The Meaning Factory(Bjerva et al。,2014),UNAL-NLP(Jimenez et al。2014)和Illinois-LH(Lai和ockenmaier,2014)。这些系统经过大量的特征设计,通常使用表面形式重叠特征和源自WordNet或复述数据库的词汇距离特征的组合(Ganitkevitch等,2013) 。
我们的LSTM模型优于所有这些系统,无需任何额外的功能工程,并且依赖树-LSTM实现了最佳结果。回想一下,在此任务中,两个TreeLSTM模型仅在树的根处接收监督,这与在中间节点处也提供监督的情绪分类任务形成对比。我们推测,在这种情况下,依赖树-LSTM受益于其相对于选区树-LSTM的更紧凑的结构,在这种意义上,从输入字向量到树的根的路径在依赖树LSTM的聚合上更短。

表3:SICK语义相关性子任务的测试集结果。 对于我们的实验,我们报告超过5次运行的平均分数(括号中的标准偏差)。 结果分组如下:(1)2014年SemEval提交; (2)我们自己的基线; (3)顺序LSTM; (4)树状结构的LSTM。
7讨论和定性分析
7.1建模语义相关性
在表4中,我们列出了从SICK测试集的1000个句子样本中检索的最近邻句子。我们将依赖树-LSTM模型排序的邻居与每个句子的平均单词向量的余弦相似性的基线排名进行比较。
依赖树-LSTM模型展示了几种理想的特性。请注意,在第二个查询语句的依赖关系解析中,单词“ocean”是从根开始的第二个最远的单词(“挥动”),深度为4.无论如何,检索到的句子在语义上都与单词相关“ocean”,表示TreeLSTM能够保存和强调来自相对较远节点的信息。此外,Tree-LSTM模型对句子长度的差异表现出更强的鲁棒性。鉴于查询“两个人正在弹吉他”,TreeLSTM将短语“弹吉他”与更长的相关短语“在人群面前跳舞和唱歌”相关联(注意两个短语之间没有令牌重叠) )。
7.2句子长度的影响
解释Tree-LSTM的经验强度的一个假设是树结构有助于缓解在长序列单词上保持状态的问题。 如果这是真的,我们预计在较长的句子上会比顺序LSTM看到最大的改进。 在图中 在图3和图4中,我们示出了由相关任务特定度量测量的句子长度与性能之间的关系。 每个数据点是5次运行的平均分数,为清楚起见,省略了误差条。
我们观察到,虽然依赖树LSTM做了很多, 对于长度为13到15的较长句子,它在相关性任务上执行其顺序对应(图4),它也可以在较短的句子上实现始终如一的强大表现。 这表明,与顺序LSTM不同,Tree-LSTM能够在它们组成的句子表示中对语义上有用的结构信息进行编码。

图3:细粒度情绪分类准确性与句子长度。 对于每个`,我们在窗口[` - 2,`+ 2]中绘制长度的测试集句子的准确度。 长度分布尾部的示例在最终窗口(`= 45)中进行批处理。

图4:预测的相似性与黄金评级与句子长度之间的Pearson相关系数r。 对于每个`,我们用r表示r窗口中的平均长度[`-2,`+2]。 长度分布尾部的示例在最终窗口(`= 18.5)中进行批处理。
8相关工作
单词的分布式表示(Rumelhart等,1988; Collobert等,2011; Turian等,2010; Huang等,2012; Mikolov等,2013; Pennington等,2014)适用于各种NLP任务。在取得这一成功之后,人们对学习分布式短语和句子表示的领域产生了浓厚的兴趣(Mitchell和Lapata,2010; Yessenalina和Cardie,2011; Grefenstette等,2013; Mikolov等,2013),以及分布式表示较长的文本体,如段落和文件(Srivastava等,2013; Le和Mikolov,2014)。
我们的方法建立在递归神经网络(Goller和Kuchler,1996; Socher等,2011)之上,我们将其简称为Tree-RNN,以避免与递归神经网络混淆。在树-RNN框架下,与树的每个节点相关联的向量表示被组成为对应于节点的子节点的向量的函数。组合函数的选择产生了该基本框架的许多变体。 TreeRNN已被用于解析自然场景的图像(Socher et al。,2011),用词向量构成短语表示(Socher et al。,,并对句子的情感极性进行分类(Socher et al。,2013)。
9结论
在本文中,我们介绍了LSTM到树状结构网络拓扑的概括。 Tree-LSTM架构可以应用于具有任意分支因子的树。我们通过将架构应用于两个任务来证明Tree-LSTM的有效性:语义相关性和情感分类,在两者上都优于现有系统。通过控制模型维度,我们证明了Tree-LSTM模型能够胜过其顺序对应物。我们的研究结果表明,在描述结构在产生分布式句子表征中的作用方面还有进一步的工作。
致谢
我们感谢匿名审稿人提供的宝贵意见。斯坦福大学非常感谢Google Inc.和美国国防部高级研究计划局(DARPA)在空军研究实验室(AFRL)合同中提供的深度探索和文本过滤(DEFT)计划提供的自然语言理解礼品的支持。 FA8750-13-2-0040。本材料中表达的任何观点,发现,结论或建议均为作者的观点,不一定反映DARPA,AFRL或美国政府的观点。