开始前建议依次阅读:
目录
1.概念梳理
1.1 线程
1.1.1 什么是线程?
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一个线程是一个execution context(执行上下文),即一个cpu执行时所需要的一串指令。
1.1.2 多线程
多线程就是允许一个进程内存在多个控制权,以便让多个函数同时处于激活状态,从而让多个函数的操作同时运行。即使是单CPU的计算机,也可以通过不停地在不同线程的指令间切换,从而造成多线程同时运行的效果。(见博客Linux并发与同步)
多线程相当于一个并发(concunrrency)系统。并发系统一般同时执行多个任务。如果多个任务可以共享资源,特别是同时写入某个变量的时候,就需要解决同步的问题,比如多线程火车售票系统:两个指令,一个指令检查票是否卖完,另一个指令,多个窗口同时卖票,可能出现卖出不存在的票。
1.2 进程
1.2.1 什么是进程?
一个程序的执行实例就是一个进程。每一个进程提供执行程序所需的所有资源。(进程本质上是资源的集合)
一个进程有一个虚拟的地址空间、可执行的代码、操作系统的接口、安全的上下文(记录启动该进程的用户和权限等等)、唯一的进程ID、环境变量、优先级类、最小和最大的工作空间(内存空间),还要有至少一个线程。
每一个进程启动时都会最先产生一个线程,即主线程。然后主线程会再创建其他的子线程。
1.2.2 多进程
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程(下面会解释为什么)。(在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行)
2.多线程
2.1 常用代码

2.2 使用Threading模块创建线程
import threading
import time
# 为线程定义一个函数
def print_time(threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
th1 = threading.Thread(target= print_time, args=("Thread-1", 2) ) #必须要加上target = 和args=
th2 = threading.Thread(target= print_time, args=("Thread-2", 4) )
#启动线程
th1.start()
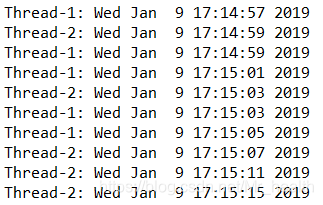
th2.start()执行结果如下:
2.3 继承threading.Thread来自定义线程类
其本质是重构Thread类中的run方法
import threading
import time
class myThread (threading.Thread): #继承父类threading.Thread
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID #线程的ID
self.name = name #线程的名称
self.counter = counter # 作为delay输入print_time,也就是延迟
def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1) #每隔1s print
thread2 = myThread(2, "Thread-2", 2) #每隔2s print
# 开启线程
thread1.start()
thread2.start()
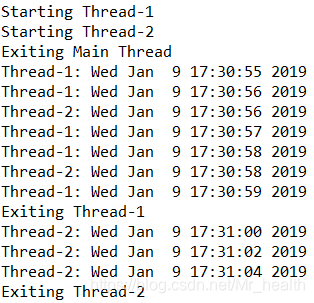
print ("Exiting Main Thread")执行结果如下:
2.3 线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
最简单的例子就是售票系统,要保证多个线程端的票数一致,不能出现一个线程刚判断没有余票,而另外一个线程就执行卖票操作。
解决的方法就是,使用Thread对象的Lock实现简单的线程同步,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据(比如某一个线程端的用户要购票了),可以将其操作放到acquire和release方法之间。如下:
import threading
import time
import os
def booth(tid):
global i
global lock
while True:
lock.acquire() # 得到一个锁,锁定
if i!=0:
i=i-1 # 售票 售出一张减少一张
print ("窗口:",tid,",剩余票数:",i) # 剩下的票数
time.sleep(0.5) # 票售完 退出程序
else:
print ("Thread_id",tid,"No more tickets")
os._exit(0)
lock.release() # 释放锁
time.sleep(0.5)
i = 20
lock=threading.Lock()
for k in range(10): #10个线程端
new_thread = threading.Thread(target=booth,args=(k,)) # 创建线程; Python使用threading.Thread对象来代表线程
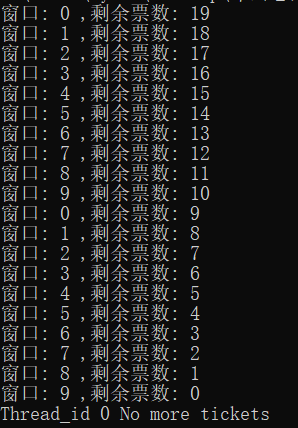
new_thread.start() # 调用start()方法启动线程运行结果为:
上面的操作也称为互斥锁。我们可以将互斥锁想像成为一个只能容纳一个人的洗手间,当某个人进入洗手间的时候,可以从里面将洗手间锁上。其它人只能在互斥锁外面等待那个人出来,才能进去。在外面等候的人并没有排队,谁先看到洗手间空了,就可以首先冲进去。
由此可以看出,当有多个线程的时候,并不是真的是并行运行的,因为锁的存在,谁申请到了谁运行。这就是为什么前面我说到python中的多线程其实并不是真正的多线程。对此的解释是:
在python的原始解释器CPython中存在着GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限制线程对共享资源的访问,直到解释器遇到I/O操作或者操作次数达到一定数目时才会释放GIL。
所以,虽然CPython的线程库直接封装了系统的原生线程,但CPython整体作为一个进程,同一时间只会有一个获得GIL的线程在跑,其他线程则处于等待状态。这就造成了即使在多核CPU中,多线程也只是做着分时切换而已。
因此:
python下想要充分利用多核CPU,就用多进程。因为每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行,在python中,多进程的执行效率优于多线程(仅仅针对多核CPU而言)。
3.多进程
3.1 基本构成
语法:Process([group[,target[,name[,args[,kwargs]]]]])
参数含义:target表示调用对象;args表示调用对象的位置参数元祖;kwargs表示调用对象的字典。name为别名,groups实际上不会调用。
方法:is_alive():
join(timeout):
run():
start():
terminate():
属性:authkey、daemon(要通过start()设置)、exitcode(进程在运行时为None、如果为-N,表示被信号N结束)、name、pid。其中daemon是父进程终止后自动终止,且自己不能产生新的进程,必须在start()之前设置。
3.2 创建函数并将其作为单个进程
import multiprocessing
import time
def worker(interval):
n = 5
while n > 0:
print("The time is {0}".format(time.ctime()))
time.sleep(interval)
n -= 1
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print "p.pid:", p.pid
print "p.name:", p.name
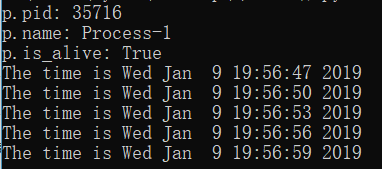
print "p.is_alive:", p.is_alive()运行结果:
3.3 创建函数并将其作为多个进程
def worker_1(interval):
print ("worker_1")
time.sleep(interval)
print ("end worker_1")
def worker_2(interval):
print ("worker_2")
time.sleep(interval)
print ("end worker_2")
def worker_3(interval):
print ("worker_3")
time.sleep(interval)
print ("end worker_3")
if __name__ == "__main__":
#创建了3个进程
p1 = multiprocessing.Process(target = worker_1, args = (2,))
p2 = multiprocessing.Process(target = worker_2, args = (3,))
p3 = multiprocessing.Process(target = worker_3, args = (4,))
#开始运行进程
p1.start()
p2.start()
p3.start()
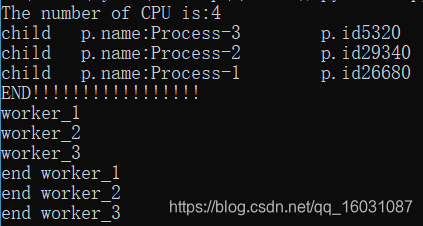
print("The number of CPU is:" + str(multiprocessing.cpu_count())) #返回cpu的核心数
for p in multiprocessing.active_children(): #multiprocessing.active_children():返回当前进程所有活动子进程列表。
print("child p.name:" + p.name + "\tp.id" + str(p.pid))
print ("END!!!!!!!!!!!!!!!!!")运行结果:
3.4 将进程定义为类
class ClockProcess(multiprocessing.Process):
def __init__(self, interval):
multiprocessing.Process.__init__(self)
self.interval = interval
#与上面定义的线程类一样,在创建后会直接运行run函数
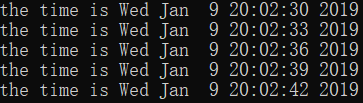
def run(self):
n = 5
while n > 0:
print("the time is {0}".format(time.ctime()))
time.sleep(self.interval)
n -= 1
if __name__ == '__main__':
p = ClockProcess(3)
p.start()运行结果:
3.5 进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
进程池中常用方法:
apply()同步执行(串行)apply_async()异步执行(并行)terminate()立刻关闭进程池,不在处理未完成的任务。join()主进程阻塞,等待所有子进程执行完毕。必须在close或terminate()之后。close()等待所有进程结束后,才关闭进程池,使其不在接受新的任务。
(1)并行
import multiprocessing
import time
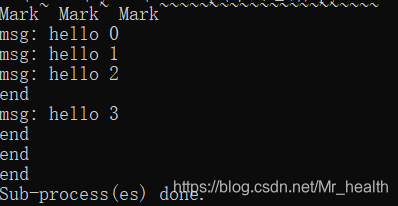
def func(msg):
print ("msg:", msg)
time.sleep(3)
print ("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3) #进程池的大小为3
for i in range(4):
msg = ("hello %d" %(i))
pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,并行
print ("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print ("Sub-process(es) done.")运行结果:
执行说明:
创建一个进程池pool,并设定进程的数量为3,range(4)会相继产生四个对象[0, 1, 2, 4],四个对象被提交到pool中,因pool指定进程数为3,所以0、1、2会直接送到进程中执行,当其中一个执行完事后才空出一个进程处理对象3,所以会出现输出“msg: hello 3”出现在"end"后。因为为非阻塞,主函数会自己执行自个的,不搭理进程的执行,所以运行完for循环后直接输出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()处等待各个进程的结束。
(2)串行
import multiprocessing
import time
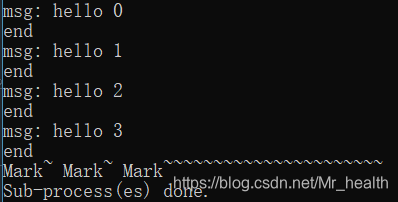
def func(msg):
print ("msg:", msg)
time.sleep(3)
print ("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3) #进程池的大小为3
for i in range(4):
msg = ("hello %d" %(i))
pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后才会添加新的进程进去
print ("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print ("Sub-process(es) done.")运行结果:
知识点:
- 进程池默认的大小为cpu的核数
- 如果设置的进程数量大于cpu核数,执行效率会降低
3.6 实例
import os
import PIL
import time
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
path = []
for f in os.listdir(folder):
if 'jpg' in f:
imgpath = os.path.join(folder, f)
path.append(imgpath)
return path
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
start = time.time()
path = r'F:\\faster_rcnn数据\\fasterrcnn船舶数据\\fasterrcnn数据2'
os.mkdir(os.path.join(path, SAVE_DIRECTORY))
img_paths = get_image_paths(path)
pool = Pool()
pool.map(create_thumbnail, img_paths)
pool.close()
pool.join()
for image in img_paths:
create_thumbnail(image)
end = time.time()
print(end - start)
该代码实现批量生成缩略图,其中用到了pool.map,其第二个参数是需要处理的数据的集合
4.多线程和多进程中Join()和daemon的用法
多线程和多进程的Join和daemon的用法基本相同,因此放在一起讲,见博客Python多线程和多进程的Join和daemon(守护)的用法。