由于最近要用python大量的数据预处理,单核处理实在太慢了,于是学习了python的多线程、多进程。
首先对python的多线程、多进程效果做了对比试验。
对比试验主要参考于http://python.jobbole.com/86822/
然后介绍如何得到多进程的返回值。
1、定义操作
分为两种,cpu密集型和IO密集型,python的多线程对于cpu密集型比较鸡肋,下面通过结果也可以看的出来。
1.1 cpu密集型操作
定义一个函数,实现加法操作150万次。
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c1.2 IO密集型操作
定义读写操作,写入50万行,并读取。
def write():
f = open("test1.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test1.txt", "r")
lines = f.readlines()
f.close()2、单进程测试
def line():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test1.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test1.txt", "r")
lines = f.readlines()
f.close()
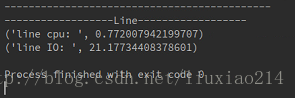
print "--------------------------------------------"
print "------------------Line------------------"
t = time.time()
for x in range(10):
count(1, 1)
print("line cpu: ", time.time() - t)
t = time.time()
for x in range(10):
write()
read()
print("line IO: ", time.time() - t)结果:
3、多线程测试
def thread():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test2.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test2.txt", "r")
lines = f.readlines()
f.close()
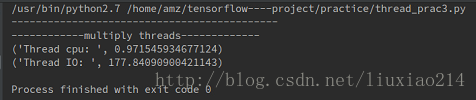
print "--------------------------------------------"
print "------------multiply threads-------------"
counts = []
t = time.time()
for x in range(10):
thread = Thread(target=count, args=(1, 1))
counts.append(thread)
thread.start()
e = counts.__len__()
while True:
for th in counts:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Thread cpu: ", time.time() - t)
def io():
write()
read()
ios = []
t = time.time()
for x in range(10):
thread = Thread(target=io)
ios.append(thread)
thread.start()
e = ios.__len__()
while True:
for th in ios:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Thread IO: ", time.time() - t)结果:
4、多进程测试
def process():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test3.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test3.txt", "r")
lines = f.readlines()
f.close()
def io():
write()
read()
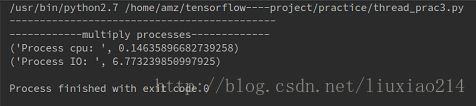
print "--------------------------------------------"
print "------------multiply processes-------------"
counts = []
t = time.time()
for x in range(10):
process = Process(target=count, args=(1, 1))
counts.append(process)
process.start()
e = counts.__len__()
while True:
for th in counts:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Process cpu: ", time.time() - t)
t = time.time()
ios = []
t = time.time()
for x in range(10):
process = Process(target=io)
ios.append(process)
process.start()
e = ios.__len__()
while True:
for th in ios:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Process IO: ", time.time() - t)结果:
5、结果比较
| 类型 | 单进程 | 多线程 | 多进程 |
|---|---|---|---|
| cpu密集型 | 0.772 | 0.971 | 0.146 |
| IO密集型 | 21.177 | 177.840 | 6.773 |
.
.
按理说,python的多线程虽然鸡肋,但是对于IO密集型的还是有效果的,但是这里不知道为何这么慢。对于cpu密集型,多线程没有什么作用,反而因为线程的管理开销浪费时间。
所以cpu密集型还是最好采用多进程的方式。
所以下面介绍如何多进程并返回函数值。
6、多进程返回函数值
6.1 使用apply_async
def count1(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def process1():
print "--------------------------------------------"
print "------------multiply processes-------------"
counts = []
t = time.time()
p = Pool(10)
for i in range(10):
counts.append(p.apply_async(count, (1, 1)))
for i in range(len(counts)):
print counts[i].get()
print("Process cpu: ", time.time() - t)结果:
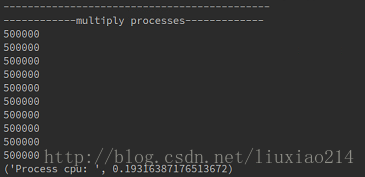
这里,count1函数定义在processes1函数里面外面都可以。count1函数可以是多个参数。
6.2 使用map
import multiprocessing
class ppp:
def __init__(self):
pass
def f1(self, x):
return x*x
list = [1, 2, 3, 4, 5]
def f2(x):
return x * x
def go():
def f3(x):
return x * x
pool = multiprocessing.Pool(processes=4)
# 1
print pool.map(f2, list)
# 2
pppp = ppp()
print pool.map(pppp.f1, list)
# 3
print pool.map(f3, list)
if __name__== '__main__' :
go()注意,上面采用了3种方法,求平方的函数分别定义在一个类中,公共函数,和函数go中。
但是只有定义为公共函数,才会返回结果。
也就是上面只有1会得到结果:

2和3都会得到错误:
“cPickle.PicklingError: Can’t pickle type ‘instancemethod’>: attribute lookup builtin.instancemethod failed”
搜了一下,https://stackoverflow.com/questions/1816958/cant-pickle-type-instancemethod-when-using-multiprocessing-pool-map有答案解释,但是没太看明白,遂放弃这种方法。
注意,map接收参数时,只能接收一个迭代器,而不能像apply_async一样,接受多个参数。
总之,这就是python使用多线程、多进程的方法。
7、全部代码
import requests
import time
from threading import Thread
from multiprocessing import Process, Pool
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def line():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test1.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test1.txt", "r")
lines = f.readlines()
f.close()
print "--------------------------------------------"
print "------------------Line------------------"
t = time.time()
for x in range(10):
count(1, 1)
print("line cpu: ", time.time() - t)
t = time.time()
for x in range(10):
write()
read()
print("line IO: ", time.time() - t)
def thread():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test2.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test2.txt", "r")
lines = f.readlines()
f.close()
print "--------------------------------------------"
print "------------multiply threads-------------"
counts = []
t = time.time()
for x in range(10):
thread = Thread(target=count, args=(1, 1))
counts.append(thread)
thread.start()
e = counts.__len__()
while True:
for th in counts:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Thread cpu: ", time.time() - t)
def io():
write()
read()
ios = []
t = time.time()
for x in range(10):
thread = Thread(target=io)
ios.append(thread)
thread.start()
e = ios.__len__()
while True:
for th in ios:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Thread IO: ", time.time() - t)
def process():
def count(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def write():
f = open("test3.txt", "w")
for x in range(5000000):
f.write("testwrite\n")
f.close()
def read():
f = open("test3.txt", "r")
lines = f.readlines()
f.close()
def io():
write()
read()
print "--------------------------------------------"
print "------------multiply processes-------------"
counts = []
t = time.time()
for x in range(10):
process = Process(target=count, args=(1, 1))
counts.append(process)
process.start()
e = counts.__len__()
while True:
for th in counts:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Process cpu: ", time.time() - t)
t = time.time()
ios = []
t = time.time()
for x in range(10):
process = Process(target=io)
ios.append(process)
process.start()
e = ios.__len__()
while True:
for th in ios:
if not th.is_alive():
e -= 1
if e <= 0:
break
print("Process IO: ", time.time() - t)
def count1(x, y):
c = 0
while c < 500000:
c += 1
x += 1
y += 1
return c
def process1():
print "--------------------------------------------"
print "------------multiply processes-------------"
counts = []
t = time.time()
p = Pool(10)
for i in range(10):
counts.append(p.apply_async(count, (1, 1)))
for i in range(len(counts)):
print counts[i].get()
print("Process cpu: ", time.time() - t)
#line()
#thread()
#process1()
import multiprocessing
class ppp:
def __init__(self):
pass
def f1(self, x):
return x*x
list = [1, 2, 3, 4, 5]
def f2(x):
return x * x
def go():
def f3(x):
return x * x
pool = multiprocessing.Pool(processes=4)
# 1
print pool.map(f2, list)
# 2
pppp = ppp()
print pool.map(pppp.f1, list)
# 3
print pool.map(f3, list)
if __name__== '__main__' :
go()————————————————————