多进程入门参考Python map
python 内置了一个函数 map,专门解决这种不断往同一个函数传不同参数的问题。
参考:
https://zhuanlan.zhihu.com/p/359369130
https://zhuanlan.zhihu.com/p/340657122
一、多进程
multiprocessing.Process
multiprocessing.Pool
1、Process进程实例
创建一个Process类的实例,并制定目标任务函数
# importing the multiprocessing module
import multiprocessing
def print_cube(num):
print("Cube: {}".format(num * num * num))
def print_square(num):
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating processes
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
# starting process 1&2
p1.start()
p2.start()
# wait until process 1&2 is finished
p1.join()
p2.join()
# both processes finished
print("Done!")
def function1(id): # 这里是子进程
print(f'id {
id}')
def run__process(): # 这里是主进程
from multiprocessing import Process
process = [mp.Process(target=function1, args=(1,)),
mp.Process(target=function1, args=(2,)), ]
[p.start() for p in process] # 开启了两个进程
[p.join() for p in process] # 等待两个进程依次结束
# run__process() # 主线程不建议写在 if外部。由于这里的例子很简单,你强行这么做可能不会报错
if __name__ =='__main__':
run__process() # 正确做法:主线程只能写在 if内部
2、Process进程类
定义一个类并继承Process类,重写其__init__方法和run方法。
from multiprocessing import Process
import os
import time
class MyProcess(Process):
def __init__(self, delay):
super().__init__()
self.delay = delay
# 子进程要执行的代码
def run(self):
num = 0
#for i in range(self.delay * 100000000):
for i in range(self.delay * 100000):
num += i
print(f"进程pid为 {
os.getpid()},执行完成")
if __name__ == "__main__":
print("父进程pid为 %s." % os.getpid())
p0 = MyProcess(3)
p1 = MyProcess(3)
t0 = time.time()
print(p0.authkey)
p0.start()
p1.start()
p0.join()
p1.join()
t1 = time.time()
print(f"多进程并发执行耗时 {
t1-t0}")
在类中创建进程
# –*– coding: utf-8 –*–
# @Time : 2019/3/19 22:58
# @Author : Damon_duanlei
# @FileName : process_02.py
# @BlogsAddr : https://blog.csdn.net/Damon_duanlei
import multiprocessing
import time
class A(object):
def __init__(self):
self.a = None
self.b = None
# 初始化一个共享字典
self.my_dict = multiprocessing.Manager().dict()
def get_num_a(self):
time.sleep(3)
self.my_dict["a"] = 10
def get_num_b(self):
time.sleep(5)
self.my_dict["b"] = 6
def sum(self):
self.a = self.my_dict["a"]
self.b = self.my_dict["b"]
print("a的值为:{}".format(self.a))
print("b的值为:{}".format(self.b))
ret = self.a + self.b
return ret
def run(self,mydata):
print(mydata)
p1 = multiprocessing.Process(target=self.get_num_a)
p2 = multiprocessing.Process(target=self.get_num_b)
p1.start()
p2.start()
p1.join()
p2.join()
print(self.sum())
if __name__ == '__main__':
data={
'name':'jgnhg'}
t1 = time.time()
a = A()
a.run(data)
t2 = time.time()
print("cost time :{}".format(t2 - t1))
3、进程池pool
import multiprocessing
# a_list = multiprocessing.Manager().list()
# a_dict = multiprocessing.Manager().dict()
def func(input_list, input_dict, i, k):
input_list.append(i)
input_dict[k] = i
if __name__ == '__main__':
a_list = multiprocessing.Manager().list()
a_dict = multiprocessing.Manager().dict()
pool = multiprocessing.Pool(processes=3)
pool.apply_async(func, (a_list, a_dict, 0, 'a'))
pool.apply_async(func, (a_list, a_dict, 1, 'b'))
pool.apply_async(func, (a_list, a_dict, 2, 'c'))
pool.close()
pool.join()
print(a_list)
print(a_dict)
# 输出
# [0, 2, 1]
# {'a': 0, 'c': 2, 'b': 1}
#coding: utf-8
import multiprocessing
import time
def task(name):
print(f"{
time.strftime('%H:%M:%S')}: {
name} 开始执行")
time.sleep(3)
if __name__ == "__main__":
# 同一时刻有3个进程在执行
pool = multiprocessing.Pool(processes = 3)
for i in range(10):
#维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool.apply_async(func = task, args=(i,))
pool.close()
pool.join()
print("hello")
# from multiprocessing import Manager,Pool
# import time
#
# def cal(datas,s,e):
# print(s)
# sum = 0
# for i in range(s,e):
# sum = sum + i
# datas.append(sum)
#
# if __name__ == '__main__':
# pool = Pool(2)
# with Manager() as manager:
# start_time = time.time()
#
# datas = manager.list()
#
# process_list = []
# for i in range(2):
# pool.apply_async(func=cal,args=(datas,i*50000000,(1+i)*50000000))
#
# pool.close()
# pool.join()
#
# print('主进程获取datas数据')
# print(datas[0]+datas[1])
# print('结束测试')
# end_time = time.time()
# print(end_time - start_time)
# print(datas)
#
# # 1249999975000000
# # 3749999975000000
# # 主进程获取datas数据
# # 4999999950000000
# # 结束测试
# # 1.6817915439605713
# # [1249999975000000, 3749999975000000]
4、Pool的四种方法比较:map, apply, map_async, apply_async
pool类有以下4种非常常用的类型。
apply:阻塞,任务其实是一个一个执行完的。无法实现并行效果
apply_async
map
map_async
其中map和map_async的用法接近,apply和appy_async的用法接近。
带async的区别主要有:
返回的顺序不是按照建立任务的顺序来的,完全看哪个任务先结束谁先返回
有一个callback参数。可以用于记录返回值和其他回调功能,比如结合tqdm制作多进程进度条。
异步函数接受参数,但同步函数接受一个装载参数的迭代器
参考链接:https://blog.csdn.net/qq_34914551/article/details/119451639
multiprocessing.dummy Pool()
非阻塞方法
multiprocessing.dummy.Pool.apply_async() 和 multiprocessing.dummy.Pool.imap()
线程并发执行
阻塞方法
multiprocessing.dummy.Pool.apply()和 multiprocessing.dummy.Pool.map()
线程顺序执行
原文链接:https://blog.csdn.net/ye__mo/article/details/123664568
5、join,daemon
默认情况下,主进程会等所有子进程执行完,再退出。
子进程设置成守护进程后,当主进程一旦完成,子进程立马结束
dance_process=multiprocessing.Process(target=dance,args=(“lin”,3),daemon=True)
使用join()方法加塞,只有当设置的子进程结束后,才会开始主进程
sing_process.start()
dance_process.join()
print(“main主进程{}”.format(os.getpid()))
(1)阻塞主进程
创建完Process对象以后通过start()方法来启动该进程,同时如果想让某个进程阻塞主进程,可以执行该进程的join()方法。正常情况下创建完子进程以后主进程会继续向下执行直到结束,如果有子进程阻塞了主进程则主进程会等待该子进程执行完以后才向下执行。这里主进程会等待p1和p2两个子进程都执行完毕才计算结束时间。
if __name__ == '__main__':
print('main process is {}'.format(os.getpid()))
start_time = time.time()
### multiprocess
from multiprocessing import Process
p1 = Process(target=func)
p2 = Process(target=func)
p1.start()
p2.start()
p1.join()
p2.join()
end_time = time.time()
print('total time is {}'.format(str(end_time - start_time)))
(2)daemon守护进程
守护进程: 当主进程结束了子进程立刻结束.
生成子进程将使用.deamon=True 方法 将子进程进程对象, 设置为守护进程.
注意点:
* 1. 子进程中无法在创建守护进程,守护进程内无法再开启子进程,否则抛出异常
* 2. 在开启进程前设置.
* 3.进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
from multiprocessing import Process
def task():
print('我是子进程!')
if __name__ == '__main__':
p = Process(target=task)
# 设置守护进程
p.daemon = True
p.start()
print('我是主进程')
from multiprocessing import Process
import time
# 子进程
def task():
# 打印123
print(123)
# 延时1秒
time.sleep(1)
# 打印end123
print("end123")
if __name__ == '__main__':
# 生成子进程对象
p1 = Process(target=task)
# 开启进程守护
p1.daemon = True
# 开启子进行
p1.start()
# 延时0.5秒(让子进行执行)
time.sleep(0.5)
# 打印main-------
print("main-------")
6、共享内存(Manager 多进程变量共享问题)
Value、Array是通过共享内存的方式共享数据
Manager是通过共享进程的方式共享数据。
num=multiprocessing.Value('d',1.0)#num=0
arr=multiprocessing.Array('i',range(10))#arr=range(10)
p=multiprocessing.Process(target=func1,args=(num,arr))
manager=Manager()
list1=manager.list([1,2,3,4,5])
dict1=manager.dict()
array1=manager.Array('i',range(10))
value1=manager.Value('i',1)
一个核心,我们多线程处理时,可以使用全局变量来共享数据。但是多进程之间是不行的,那我们多进程之间应该如何共享数据呢?那就得用到共享内存了!
除multiprocessing.Value外,window不支持多进程变量共享声明在main函数外,Linux支持
num = multiprocessing.Value(“d”, 1) # d表示数值,主进程与子进程共享这个value。(主进程与子进程都是用的同一个value)
mgr_dict = multiprocessing.Manager().dict({‘flag’:1,‘imgpath’:‘./static/img’,‘videopath’:‘./static/video’}) # 主进程与子进程共享这个字典
3.3 在windows中使用process模块的注意事项
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if name =='main 判断保护起来,import 的时候,就不会递归运行了。
https://www.cnblogs.com/SkyOceanchen/p/11537587.html#multiprocessingprocess%E6%A8%A1%E5%9D%97
注意:在Windows上要想使用进程模块,就必须把有关进程的代码写在当前.py文件的if name == ‘main’ :语句的下面,才能正常使用Windows下的进程模块,Unix/Linux下则不需要。
(1)Process 多进程
使用 Process 定义的多进程之间共享变量可以直接使用 multiprocessing 下的 Value,Array,Queue 等,如果要共享 list,dict,可以使用强大的 Manager 模块。
import multiprocessing
def func(num):
# 共享数值型变量
# num.value = 2
# 共享数组型变量
num[2] = 9999
if __name__ == '__main__':
# 共享数值型变量
# num = multiprocessing.Value('d', 1)
# print(num.value)
# 共享数组型变量
num = multiprocessing.Array('i', [1, 2, 3, 4, 5])
print(num[:])
p = multiprocessing.Process(target=func, args=(num,))
p.start()
p.join()
# 共享数值型变量
# print(num.value)
# 共享数组型变量
print(num[:])
(2)Pool 进程池
进程池之间共享变量是不能使用上文方式的,因为进程池内进程关系并非父子进程,想要共享,必须使用 Manager 模块来定义。
from multiprocessing import Pool, Manager
def func(my_list, my_dict):
my_list.append(10)
my_list.append(11)
my_dict['a'] = 1
my_dict['b'] = 2
if __name__ == '__main__':
manager = Manager()
my_list = manager.list()
my_dict = manager.dict()
pool = Pool(processes=2)
for i in range(0, 2):
pool.apply_async(func, (my_list, my_dict))
pool.close()
pool.join()
print(my_list)
print(my_dict)
(3)位置
import multiprocessing
# window不支持多进程变量共享声明在main函数外,Linux支持
除multiprocessing.Value外,window不支持多进程变量共享声明在main函数外,Linux支持
num = multiprocessing.Value("d", 0.0) # d表示数值,主进程与子进程共享这个value。(主进程与子进程都是用的同一个value)
# mgr_list = multiprocessing.Manager().list() # 主进程与子进程共享这个字典
# mgr_dict = multiprocessing.Manager().dict({'name': 'kunkun'}) # 主进程与子进程共享这个字典
def worker(num, mgr_dict, mgr_list, key, value):
mgr_dict[key] = value
mgr_list.append(key)
num.value += value
mgr_dict['name'] ='jinmai'
# print(mgr_dict.get('name'))
if __name__ == '__main__':
# num = multiprocessing.Value("d", 0.0) # d表示数值,主进程与子进程共享这个value。(主进程与子进程都是用的同一个value)
mgr_list = multiprocessing.Manager().list() # 主进程与子进程共享这个字典
mgr_dict = multiprocessing.Manager().dict({
'name': 'kunkun'}) # 主进程与子进程共享这个字典
jobs = [multiprocessing.Process(target=worker, args=(num, mgr_dict, mgr_list, i, i * 2)) for i in range(10)]
for j in jobs:
j.start()
for j in jobs:
j.join()
print('Results:')
print('数字', num.value)
print('字典', mgr_dict)
print('列表', mgr_list)
from flask import Flask
import time
import multiprocessing
app = Flask(__name__)
除multiprocessing.Value外,window不支持多进程变量共享声明在main函数外,Linux支持
num = multiprocessing.Value("d", 1) # d表示数值,主进程与子进程共享这个value。(主进程与子进程都是用的同一个value)
def func(num):
print('子线程1:', num.value)
time.sleep(5)
print('睡眠完成')
a=1/0
num.value = 1 # 子进程改变数值的值,主进程跟着改变
print('子线程2:',num.value)
# return '子线程处理完成'
@app.route('/')
def hello_world():
if num.value:
num.value=0
p = multiprocessing.Process(target=func, args=(num,))
p.start()
print('提交成功,请等待处理')
return '提交成功,请等待处理'
if not num.value:
print('正在执行,请等待')
return '正在执行,请等待'
return 'Hello World!'
if __name__ == '__main__':
app.run(debug=True, port=6006)
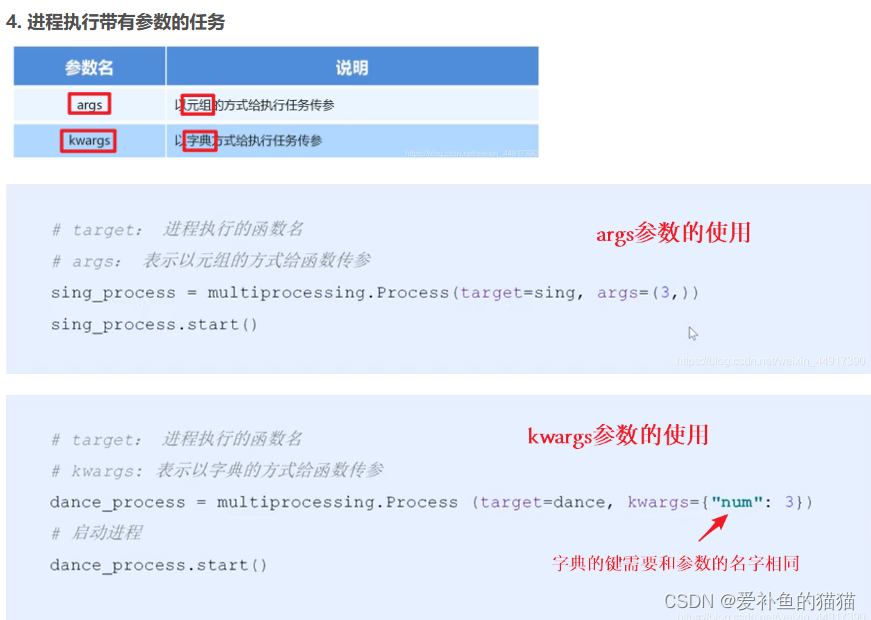
'''
时间:2021.8.11
作者:手可摘星辰不去高声语
名称:03-进程中执行带有参数的任务.py
'''
# 1.导入包和模块
import multiprocessing
import time
def sing(num, name):
for i in range(num):
print(name)
print("---i am sing ooo~")
time.sleep(0.5)
def dance(num, name):
for i in range(num):
print(name)
print("i am dance lll~")
time.sleep(0.5)
if __name__ == '__main__':
# 2.使用进程类创建进程对象
# target:指定进程执行的函数名,不加括号
# args:使用元组方式给指定任务传参,顺序一致(参数顺序)
# kwargs:使用字典的方式给指定任务传参,名称一致(参数名称)
sing_process = multiprocessing.Process(target=sing, args=(3, "猪猪"))
dance_process = multiprocessing.Process(target=dance, kwargs={
"name": "珊珊", "num": 2})
# 3. 使用进程对象启动进程执行指定任务
sing_process.start()
dance_process.start()
7、进程锁lock
进程锁和线程锁的用法基本一致。进程锁的诞生是为了避免多进程之间抢占共享数据,进而造成多进程之间混乱修改共享内存的局面。如果某一时间只能有一个进程访问某个共享资源,这种情形就需要使用锁。
(1)不加锁之前
# coding:utf-8
import multiprocessing as mp
import time
"""
进程中的锁lock
"""
def job(v, num):
for i in range(10):
v.value += num
print(v.value)
time.sleep(0.2)
if __name__ == "__main__":
# 多进程中的共享内存
v = mp.Value("i", 0)
# 进程1让共享变量每次加1
process1 = mp.Process(target=job, args=(v, 1))
# 进程2让共享变量每次加3
process2 = mp.Process(target=job, args=(v, 3))
process1.start()
process2.start()
(2)加锁之后
# coding:utf-8
import multiprocessing as mp
import time
"""
进程中的锁lock
"""
def job(v, num, l):
# 加锁
l.acquire()
for i in range(10):
v.value += num
print(v.value)
time.sleep(0.2)
# 解锁
l.release()
if __name__ == "__main__":
# 创建进程锁
l = mp.Lock()
# 多进程中的共享内存
v = mp.Value("i", 0)
process1 = mp.Process(target=job, args=(v, 1, l))
process2 = mp.Process(target=job, args=(v, 3, l))
process1.start()
process2.start()
multiprocessing模块和threading模块一样也支持锁。通过acquire获取锁,执行操作后通过release释放锁。
#-*- coding:utf8 -*-
from multiprocessing import Process, Lock
def printer(item, lock):
# 获取锁
lock.acquire()
try:
print(item)
except Exception as e:
print(e)
else:
print('no exception.')
finally:
# 释放锁
lock.release()
if __name__ == '__main__':
# 实例化全局锁
lock = Lock()
items = ['PHP', 'Python', 'Java']
procs = []
for item in items:
proc = Process(target=printer, args=(item, lock))
procs.append(proc)
proc.start()
for proc in procs:
proc.join()
print('Done.')
8、信号量Semaphore(多把锁)
互斥锁(线程锁)同时只允许一个线程更改数据, (一把锁).
信号量(Semahpore)同时允许一定数量的线程更改数据, (多把锁).
信号量: 是一个变量, 控制着对公共资源或者临界区的访问.
信号量维护着一个计数器, 指定可同时访问资源或者进入临界区的线程数.
每次有一个线程获得信号量时, 计数器-1.
若计数器为0, 其他线程就停止访问信号量, 直到另一个线程释放信号量.
from multiprocessing import Process, Semaphore
import time
# 子进程调用的函数
def task(lock, i):
# 加信号量锁
lock.acquire()
print('%s号程序开始执行!' % i)
time.sleep(2)
print('%s号程序执行完毕!' % i)
time.sleep(2)
# 释放信号量锁
lock.release()
if __name__ == '__main__':
# 创建信号量对象, 看成是两把锁
lock = Semaphore(2)
# 创建10个子进程
for i in range(10):
p = Process(target=task, args=(lock, i))
p.start()
9、进程间通信
进程间通信的方式一般有管道(Pipe)、消息队列(Message)、信号(Signal)、信号量(Semaphore)、共享内存(Shared Memory)、套接字(Socket)等。这里我们着重讲一下在Python多进程编程中常用的进程方式multiprocessing.Pipe函数和multiprocessing.Queue类。
Pipe
multiprocessing.Pipe()即管道模式,调用Pipe()方法返回管道的两端的Connection。Pipe方法返回(conn1, conn2)代表一个管道的两个端。Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说conn1和conn2均可收发;duplex为False,conn1只负责接受消息,conn2只负责发送消息。send()和recv()方法分别是发送和接受消息的方法。一个进程从Pipe某一端输入对象,然后被Pipe另一端的进程接收,单向管道只允许管道一端的进程输入另一端的进程接收,不可以反向通信;而双向管道则允许从两端输入和从两端接收。
#-*- coding:utf8 -*-
import os, time
from multiprocessing import Process, Pipe, current_process
def proc1(pipe, data):
for msg in range(1, 6):
print('{0} 发送 {1}'.format(current_process().name, msg))
pipe.send(msg)
time.sleep(1)
pipe.close()
def proc2(pipe, length):
count = 0
while True:
count += 1
if count == length:
pipe.close()
try:
# 如果没有接收到数据recv会一直阻塞,如果管道被关闭,recv方法会抛出EOFError
msg = pipe.recv()
print('{0} 接收到 {1}'.format(current_process().name, msg))
except Exception as e:
print(e)
break
if __name__ == '__main__':
conn1, conn2 = Pipe(True)
data = range(0, 6)
length = len(data)
proc1 = Process(target=proc1, args=(conn1, data))
proc2 = Process(target=proc2, args=(conn2, length))
proc1.start()
proc2.start()
proc1.join()
proc2.join()
print('Done.')
Queue
队列和管道的数据都是将数据存放于内存中.
队列是基于管道加锁实现的, 使用队列来解决数据共享问题.
队列的特性:先进先出.
创建共享的队列:
队列对象 = Queue([maxsize])
Queue能安全的实现多进程之间的数据传递.
maxsize 是队列运行的最大项数, 省略则为无限制
生产消费模型:在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据
生产数据的--> 比喻为生产者, 使用数据的--> 比喻为消费者.
生产者处理速度快, 消费者处理速度慢, 则生成者必须等待消费者处理, 有位置存放, 才能继续数据生产.
消费者处理速度快, 生产者处理速度慢, 则消费者必须等待生产者生产, 有了数据后, 才能继续进行处理.
生产者与消费者通过一个容器来解决生产者和消费者的强耦合问题,
生产者和消费者之间不直接通信, 而是通过阻塞队列进行通信,
生产者将数据存进阻塞队列中, 消费者从阻塞队列中取数据.
from multiprocessing import Process, Queue
import time
# 生产者
def production(q, name, food):
for i in range(10):
date = ('%s生产了第%s个%s.' % (name, i, food))
date1 = ('%s生产的第%s个%s.' % (name, i, food))
# 将生产的包子存到队列中
q.put(date1)
print(date)
# 消费者
def consumption(q, name):
for i in range(10):
time.sleep(1)
# 从队列中取出包子吃
print('%s 吃了 %s' % (name, q.get()))
if __name__ == '__main__':
# 创建队列
q = Queue(2)
# 创建生产者子进程
p1 = Process(target=production, args=(q, 'kid', '包子'))
# 开始生产
p1.start()
# 创建消费者子进程
p2 = Process(target=consumption, args=(q, 'qz'))
# 开始消费
p2.start()
https://zhuanlan.zhihu.com/p/104919288
10、事件Event
在event.wait()之前的不阻塞,运行到event.wait()时阻塞该进程
事件Event是用于堵塞进程执行的一个用途,可以让进程之间做到同时堵塞同时进行,类似于一种断点的效果,常用于一种信号状态的传递。Event 是用来实现进程间同步通信的(当然多线程中也可以用 event )。事件event运行的机制是:全局定义了一个Flag,如果Flag值为 False,当程序执行event.wait()方法时就会阻塞,如果Flag值为True时,程序执行event.wait()方法时不会阻塞继续执行。
Event事件: 事件处理的机制, 通过标志为, 控制全部进程进入阻塞状态,
也可以通过控制标志位,解除全部进程的阻塞.
注意:定义的事件对象, 默认状态是阻塞.
e = Event() #创建一个event对象
e.is_set() #展示当前event的状态,一个对象刚被创建是,状态都为False即阻塞状态
e.wait() #wait方法会根据当前的对象状态来控制程序是否阻塞
e.set() #将当前的事件状态改为True
e.clear() #将当前的事件状态改为False
下面代码定义了2个进程函数,一个用于等待事件发生,另一个用于等待事件发生并设置超时时间,主进程调用事件的set()方法唤醒等待事件的进程,唤醒后用clear()方法清除事件的状态并重新等待,以此达到进程的同步控制。
import multiprocessing
import time
def wait_for_event(e):
e.wait()
time.sleep(1)
e.clear()
print(f'{
time.strftime("%H:%M%S")} 进程A 等')
e.wait()
print(f'{
time.strftime("%H:%M%S")} 进程A 一起走')
def wait_for_timeout(e, t):
e.wait()
time.sleep(1)
e.clear()
print(f'{
time.strftime("%H:%M%S")} 进程B 最多等{
t}秒')
e.wait()
print(f'{
time.strftime("%H:%M%S")} 进程B 继续走')
if __name__ == '__main__':
e = multiprocessing.Event()
w1 = multiprocessing.Process(target=wait_for_event, args=(e,))
w2 = multiprocessing.Process(target=wait_for_timeout, args=(e, 3))
w1.start()
w2.start()
print(f'{
time.strftime("%H:%M%S")} 主进程 需要5秒')
e.set()
time.sleep(8)
print(f'{
time.strftime("%H:%M%S")} 主进程 赶上')
e.set()
w1.join()
w2.join()
print(f'{
time.strftime("%H:%M%S")} 主进程 退出')
红绿灯模型
下面这个例子展示的就是event堵塞的效果,当绿灯亮的时候,就会使得cars方法向下执行,而当红灯亮的时候就会堵塞程序的执行
from multiprocessing import Process,Event
import random
from time import sleep
def lights(e):
while True:
e.clear()
print("红灯亮,禁止通行")
sleep(8)
e.set()
print("绿灯亮,冲冲冲")
sleep(8)
def cars(i,e):
if e.is_set:
print("car%i在等待"%i)
e.wait()
e.wait()
print("car%i通过了"%i)
if __name__ == '__main__':
e = Event()
p = Process(target=lights,args=(e,))
p.start()
car = Process(target=cars,args=(i,e))
car.start()
11、多进程使+tqdm显示进度
import time
from multiprocessing import Pool, RLock, freeze_support
from tqdm import tqdm
import os
def my_process(process_name):
# tqdm中的position参数需要设定呦!!!
pro_bar = tqdm(range(50), ncols=80, desc=f"Process—{
process_name} pid:{
str(os.getpid())}",
delay=0.01, position=process_name, ascii=False)
for file in pro_bar:
time.sleep(0.2)
pro_bar.close()
if __name__ == '__main__':
print(f'父进程 {
os.getpid()}')
freeze_support()
pro_num = 3
# 多行显示,需要设定tqdm中全局lock
p = Pool(pro_num, initializer=tqdm.set_lock, initargs=(RLock(),))
for idx in range(pro_num):
p.apply_async(my_process, kwds={
"process_name": idx})
p.close()
p.join()
# 1、入门https://zhuanlan.zhihu.com/p/163613814
12、进程同步与互斥
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
同步是一种更为复杂的互斥,而互斥是一种特殊的同步。也就是说互斥是两个线程之间不可以同时运行,他们会相互排斥,必须等待一个线程运行完毕,另一个才能运行,而同步也是不能同时运行,但他是必须要按照某种次序来运行相应的线程(也是一种互斥)!
二、多线程
线程执行顺序:
1、子线程启动后start() ,主线程也不等待子线程,子线程运行结束后自行关闭
2、子线程启动后,调用 join()方法,主线程等待子线程运行结束。
3、子线程启动前,设置setDaemon(True)把所有的子线程都变成了主线程的守护线程,启动后,当主进程结束后,子线程也会随之结束。
1、Thread实例化
调用start()方法。
import time
import threading
def task_thread(counter):
print(
f'线程名称:{
threading.current_thread().name} 参数:{
counter} 开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}'
)
num = counter
while num:
time.sleep(3)
num -= 1
print(
f'线程名称:{
threading.current_thread().name} 参数:{
counter} 结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}'
)
if __name__ == "__main__":
print(f'主线程开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
# 初始化3个线程,传递不同的参数
t1 = threading.Thread(target=task_thread, args=(3,))
t2 = threading.Thread(target=task_thread, args=(2,))
t3 = threading.Thread(target=task_thread, args=(1,))
# 开启三个线程
t1.start()
t2.start()
t3.start()
# 等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
2、继承Thread类
在子类中重写run()和init()方法
import time
import threading
class MyThread(threading.Thread):
def __init__(self, counter):
super().__init__()
self.counter = counter
def run(self):
print(
f'线程名称:{
threading.current_thread().name} 参数:{
self.counter} 开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}'
)
counter = self.counter
while counter:
time.sleep(3)
counter -= 1
print(
f'线程名称:{
threading.current_thread().name} 参数:{
self.counter} 结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}'
)
if __name__ == "__main__":
print(f'主线程开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
# 初始化3个线程,传递不同的参数
t1 = MyThread(3)
t2 = MyThread(2)
t3 = MyThread(1)
# 开启三个线程
t1.start()
t2.start()
t3.start()
# 等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
import time
import threading
def task_thread(counter):
print(f'线程名称:{
threading.current_thread().name} 参数:{
counter} 开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
num = counter
while num:
time.sleep(3)
num -= 1
print(f'线程名称:{
threading.current_thread().name} 参数:{
counter} 结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
class MyThread(threading.Thread):
def __init__(self, target, args):
super().__init__()
self.target = target
self.args = args
def run(self):
self.target(*self.args)
if __name__ == "__main__":
print(f'主线程开始时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
# 初始化3个线程,传递不同的参数
t1 = MyThread(target=task_thread,args=(3,))
t2 = MyThread(target=task_thread,args=(2,))
t3 = MyThread(target=task_thread,args=(1,))
# 开启三个线程
t1.start()
t2.start()
t3.start()
# 等待运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{
time.strftime("%Y-%m-%d %H:%M:%S")}')
3、线程池Pool
多线程实现的四种方式分别是:
(1)multiprocessing下面有两种:
from multiprocessing.dummy import Pool as ThreadPool # 线程池
from multiprocessing.pool import ThreadPool # 线程池,用法无区别,唯一区别这个是线程池
(2)另外两种:
from concurrent.futures import ThreadPoolExecutor # python原生线程池,这个更主流
import threadpool # 线程池,需要 pip install threadpool,很早之前的
原文链接:https://blog.csdn.net/ye__mo/article/details/123664568
方式1: multiprocessing.dummy Pool()
非阻塞方法:线程并发执行
multiprocessing.dummy.Pool.apply_async() 和 multiprocessing.dummy.Pool.imap()
阻塞方法:线程顺序执行
multiprocessing.dummy.Pool.apply()和 multiprocessing.dummy.Pool.map()
from multiprocessing.dummy import Pool as Pool
import time
def func(msg):
print('msg:', msg)
time.sleep(2)
print('end:')
pool = Pool(processes=3)
for i in range(1, 5):
msg = 'hello %d' % (i)
pool.apply_async(func, (msg,)) # 非阻塞,子线程有返回值
# pool.apply(func,(msg,)) # 阻塞,apply()源自内建函数,用于间接的调用函数,并且按位置把元祖或字典作为参数传入。子线程无返回值
# pool.imap(func,[msg,]) # 非阻塞, 注意与apply传的参数的区别 无返回值
# pool.map(func, [msg, ]) # 阻塞 子线程无返回值
print('Mark~~~~~~~~~~~~~~~')
pool.close()
pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print('sub-process done')
方式3:主流ThreadPoolExecutor
Python为我们提供了ThreadPoolExecutor来实现线程池,此线程池默认子线程守护。它的适应场景为突发性大量请求或需要大量线程完成任务,但实际任务处理时间较短。
from time import sleep
# fun为定义的待运行函数
with ThreadPoolExecutor(max_workers=5) as executor:
ans = executor.map(fun, [遍历值])
for res in ans:
print(res)
with ThreadPoolExecutor(max_workers=5) as executor:
list = [遍历值]
ans = [executor.submit(fun, i) for i in list]
for res in as_completed(ans):
print(res.result())
其中max_workers为线程池中的线程个数,常用的遍历方法有map和submit+as_completed。根据业务场景的不同,若我们需要输出结果按遍历顺序返回,我们就用map方法,若想谁先完成就返回谁,我们就用submit+as_complete方法。
- 等待任务完成
1、ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
2、使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄,注意submit()不是阻塞的,而是立即返回。
3、通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。
4、使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。
5、使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
参考:https://zhuanlan.zhihu.com/p/627853937
当使用 ThreadPoolExecutor 创建的线程池对象后,我们可以使用 submit、map、shutdown等方法来操作线程池中的线程以及任务。
1、submit方法 ThreadPoolExecutor的submit方法用于将任务提交到线程池中进行处理,该方法返回一个Future对象,代表将来会返回结果的值。submit方法的语法如下:
submit(fn, *args, **kwargs)
其中,fn参数是要执行的函数,*args和**kwargs是fn的参数。
示例:
from concurrent.futures import ThreadPoolExecutor
def multiply(x, y):
return x * y
with ThreadPoolExecutor(max_workers=3) as executor:
future = executor.submit(multiply, 10, 5)
print(future.result()) # 50
2、map方法 ThreadPoolExecutor的map方法用于将函数应用于迭代器中的每个元素,该方法返回一个迭代器。map方法的语法如下:
map(func, *iterables, timeout=None, chunksize=1)
其中,func参数是要执行的函数,*iterables是一个或多个迭代器,timeout和chunksize是可选参数。
示例:
from concurrent.futures import ThreadPoolExecutor
def square(x):
return x * x
def cube(x):
return x * x * x
with ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(square, [1, 2, 3, 4, 5])
for square_result in results:
print(square_result)
results = executor.map(cube, [1, 2, 3, 4, 5])
for cube_result in results:
print(cube_result)
3、shutdown方法 ThreadPoolExecutor的shutdown方法用于关闭线程池,该方法在所有线程执行完毕后才会关闭线程池。shutdown方法的语法如下:
shutdown(wait=True)
其中,wait参数表示是否等待所有任务执行完毕后才关闭线程池,默认为True。
示例:
from concurrent.futures import ThreadPoolExecutor
import time
def task(num):
print("Task {} is running".format(num))
time.sleep(1)
return "Task {} is complete".format(num)
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(1, 4)]
executor.shutdown()
实例代码
from concurrent.futures import ThreadPoolExecutor
import threading
import time
# 定义一个准备作为线程任务的函数
def action(max):
my_sum = 0
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
my_sum += i
return my_sum
# 创建一个包含2条线程的线程池
pool = ThreadPoolExecutor(max_workers=2)
# 向线程池提交一个task, 20会作为action()函数的参数
future1 = pool.submit(action, 20)
# 向线程池再提交一个task, 30会作为action()函数的参数
future2 = pool.submit(action, 30)
# 判断future1代表的任务是否结束
print(future1.done())
time.sleep(3)
# 判断future2代表的任务是否结束
print(future2.done())
# 查看future1代表的任务返回的结果
print(future1.result())
# 查看future2代表的任务返回的结果
print(future2.result())
# 关闭线程池
pool.shutdown()
4、线程池Pool四种方法比较
多线程实现的四种方式分别是:
(1)multiprocessing下面有两种:
from multiprocessing.dummy import Pool as ThreadPool # 线程池
from multiprocessing.pool import ThreadPool # 线程池,用法无区别,唯一区别这个是线程池
(2)另外两种:
from concurrent.futures import ThreadPoolExecutor # python原生线程池,这个更主流
import threadpool # 线程池,需要 pip install threadpool,很早之前的
原文链接:https://blog.csdn.net/ye__mo/article/details/123664568
5、join 、setDaemon
(1)setDaemon守护线程
我们看下面这个例子,这里使用setDaemon(True)把所有的子线程都变成了主线程的守护线程,因此当主进程结束后,子线程也会随之结束。所以当主线程结束后,整个程序就退出了。
import threading
import time
def run(n):
print("task", n)
time.sleep(1) #此时子线程停1s
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
if __name__ == '__main__':
t = threading.Thread(target=run, args=("t1",))
t.setDaemon(True) #把子进程设置为守护线程,必须在start()之前设置
t.start()
print("end")
----------------------------------
>>> task t1
>>> end
我们可以发现,设置守护线程之后,当主线程结束时,子线程也将立即结束,不再执行。
(2)join主线程阻塞
主线程等待子线程结束
为了让守护线程执行结束之后,主线程再结束,我们可以使用join方法,让主线程等待子线程执行。
import threading
import time
def run(n):
print("task", n)
time.sleep(1) #此时子线程停1s
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
if __name__ == '__main__':
t = threading.Thread(target=run, args=("t1",))
t.setDaemon(True) #把子进程设置为守护线程,必须在start()之前设置
t.start()
t.join() # 设置主线程等待子线程结束
print("end")
----------------------------------
>>> task t1
>>> 3
>>> 2
>>> 1
>>> end
6、多线程共享全局变量
线程是进程的执行单元,进程是系统分配资源的最小单位,所以在同一个进程中的多线程是共享资源的。
import threading
import time
g_num = 100
def work1():
global g_num
for i in range(3):
g_num += 1
print("in work1 g_num is : %d" % g_num)
def work2():
global g_num
print("in work2 g_num is : %d" % g_num)
if __name__ == '__main__':
t1 = threading.Thread(target=work1)
t1.start()
time.sleep(1)
t2 = threading.Thread(target=work2)
t2.start()
----------------------------------
>>> in work1 g_num is : 103
>>> in work2 g_num is : 103
7、线程锁lock
(1)同步锁、互斥锁(Lock)
当多个线程同时修改同一条数据时可能会出现脏数据,所以,出现了线程锁,即同一时刻允许一个线程执行操作。锁通常被用来实现对共享资源的同步访问,为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁。由于线程之间是进行随机调度,如果有多个线程同时操作一个对象,如果没有很好地保护该对象,会造成程序结果的不可预期,我们也称此为“线程不安全”。python的同步锁了,也就是同一时间只能放一个线程来操作num变量。
import threading
import time
num = 100
def fun_sub():
global num
lock.acquire()
print('----加锁----')
print('现在操作共享资源的线程名字是:',t.name)
num2 = num
time.sleep(0.001)
num = num2-1
lock.release()
print('----释放锁----')
if __name__ == '__main__':
print('开始测试同步锁 at %s' % time.ctime())
lock = threading.Lock() #创建一把同步锁
thread_list = []
for thread in range(100):
t = threading.Thread(target=fun_sub)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('num is %d' % num)
print('结束测试同步锁 at %s' % time.ctime())
(2)死锁
python中在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。在这种情况下就是在同一线程中多次请求同一资源时候出现的问题。下面是一个死锁的例子:
import threading
import time
lock_apple = threading.Lock()
lock_banana = threading.Lock()
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
self.fun1()
self.fun2()
def fun1(self):
lock_apple.acquire() # 如果锁被占用,则阻塞在这里,等待锁的释放
print ("线程 %s , 想拿: %s--%s" %(self.name, "苹果",time.ctime()))
lock_banana.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "香蕉",time.ctime()))
lock_banana.release()
lock_apple.release()
def fun2(self):
lock_banana.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "香蕉",time.ctime()))
time.sleep(0.1)
lock_apple.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "苹果",time.ctime()))
lock_apple.release()
lock_banana.release()
if __name__ == "__main__":
for i in range(0, 10): #建立10个线程
my_thread = MyThread() #类继承法是python多线程的另外一种实现方式
my_thread.start()
(3) 重入锁(递归锁) RLock
为了支持在同一线程中多次请求同一资源,python提供了"递归锁":threading.RLock。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
import threading
import time
lock = threading.RLock() #递归锁
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
self.fun1()
self.fun2()
def fun1(self):
lock.acquire() # 如果锁被占用,则阻塞在这里,等待锁的释放
print ("线程 %s , 想拿: %s--%s" %(self.name, "苹果",time.ctime()))
lock.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "香蕉",time.ctime()))
lock.release()
lock.release()
def fun2(self):
lock.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "香蕉",time.ctime()))
time.sleep(0.1)
lock.acquire()
print ("线程 %s , 想拿: %s--%s" %(self.name, "苹果",time.ctime()))
lock.release()
lock.release()
if __name__ == "__main__":
for i in range(0, 10): #建立10个线程
my_thread = MyThread() #类继承法是python多线程的另外一种实现方式
my_thread.start()
(4)with语句加锁Lock
Python Threading中的Lock模块有acquire()和release()两种方法,这两种方法与with语句的搭配相当于,进入with语句块时候会先执行acquire()方法,语句块结束后会执行release方法。
举个例子:
from threading import Lock
temp_lock = Lock()
with temp_lock:
print(temp_lock)
# 输出是 <locked _thread.lock object at 0x10e304870> 说明temp_lock上锁了
print(temp_lock)
# 输出是<unlocked _thread.lock object at 0x10e304870> 说明temp_lock被释放了
现在来解析一下with语句:
with temp_lock:
# do something...
相当于以下代码:
temp_lock.acquire()
try:
# do something...
finally:
temp_lock.release()
参考:https://zhuanlan.zhihu.com/p/64086821
8、信号量(BoundedSemaphore类)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading
import time
def run(n, semaphore):
semaphore.acquire() #加锁
time.sleep(1)
print("run the thread:%s\n" % n)
semaphore.release() #释放
if __name__ == '__main__':
num = 0
semaphore = threading.BoundedSemaphore(5) # 最多允许5个线程同时运行
for i in range(22):
t = threading.Thread(target=run, args=("t-%s" % i, semaphore))
t.start()
while threading.active_count() != 1:
pass # print threading.active_count()
else:
print('-----all threads done-----')
9、通信
线程中通信方法大致有如下三种:
threading.Event
threading.Condition
queue.Queue
Queue日常开发中最使用频率最高的。从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。创建一个被多个线程共享的 Queue 对象,这些线程通过使用put() 和 get() 操作来向队列中发送和获取元素。
示例:生产 消费模式
import threading, time
import queue
# 最多存入10个
q = queue.PriorityQueue(10)
def producer(name):
''' 生产者 '''
count = 1
while True:
# 生产袜子
q.put("袜子 %s" % count) # 将生产的袜子方法队列
print(name, "---生产了袜子", count)
count += 1
time.sleep(0.2)
def consumer(name):
''' 消费者 '''
while True:
print("%s ***卖掉了[%s]" % (name, q.get())) # 消费生产的袜子
time.sleep(1)
q.task_done() # 告知这个任务执行完了
# 生产线程
z = threading.Thread(target=producer, args=("张三",))
# 消费线程
l = threading.Thread(target=consumer, args=("李四",))
w = threading.Thread(target=consumer, args=("王五",))
# 执行线程
z.start()
l.start()
w.start()
10、事件Event
事件用于线程之间的通信。一个线程发出一个信号,其他一个或者多个线程等待,调用Event对象的wait方法,线程则会阻塞等待,直到别的线程set之后才会被唤醒
import threading, time
class Boy(threading.Thread):
def __init__(self, cond, name):
super(Boy, self).__init__()
self.cond = cond
self.name = name
def run(self):
print(self.name + ": 嫁给我吧!?")
self.cond.set() # 唤醒一个挂起的线程,让hanmeimei表态
time.sleep(0.5)
self.cond.wait()
print(self.name + ": 我单下跪,送上戒指!")
self.cond.set()
time.sleep(0.5)
self.cond.wait()
self.cond.clear()
print(self.name + ": Li太太,你的选择太明智了。")
class Girl(threading.Thread):
def __init__(self, cond, name):
super(Girl, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.wait() # 等待Lilei求婚
self.cond.clear()
print(self.name + ": 没有情调,不够浪漫,不答应")
self.cond.set()
time.sleep(0.5)
self.cond.wait()
print(self.name + ": 好吧,答应你了")
self.cond.set()
cond = threading.Event()
boy = Boy(cond, "LiLei")
girl = Girl(cond, "HanMeiMei")
boy.start()
girl.start()
11、多线程同步之Condition
条件对象能让一个线程A停下来,等待其他线程B,线程B满足某个条件后通知线程B继续运行。
Condition 条件变量通常与一个锁相关联。需要在多个Condition 条件中共享一个锁时,可以传递一个Lock/RLock实例给构造方法,否则他将自己产生一个RLock实例。
import threading
class Boy(threading.Thread):
def __init__(self, cond, name):
super(Boy, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
print(self.name + ": 嫁给我吧!?")
self.cond.notify() # 唤醒一个挂起的线程,让hanmeimei表态
self.cond.wait() # 释放内部所占用的琐,同时线程被挂起,直至接收到通知被唤醒或超时,等待hanmeimei回答
print(self.name + ": 我单下跪,送上戒指!")
self.cond.notify()
self.cond.wait()
print(self.name + ": Li太太,你的选择太明智了。")
self.cond.release()
class Girl(threading.Thread):
def __init__(self, cond, name):
super(Girl, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
self.cond.wait() # 等待Lilei求婚
print(self.name + ": 没有情调,不够浪漫,不答应")
self.cond.notify()
self.cond.wait()
print(self.name + ": 好吧,答应你了")
self.cond.notify()
self.cond.release()
cond = threading.Condition()
boy = Boy(cond, "LiLei")
girl = Girl(cond, "HanMeiMei")
girl.start()
boy.start()
上面程序先启动了girl线程,gitl虽然获取到了条件变量锁cond, 但又执行了wait并释放条件变量锁,自身进入阻塞状态。boy线程启动后,就获得了条件变量锁cond并发出了消息,之后通过notify唤醒一个挂起的线程。
最后通过release程序释放资源。
12、GIL(Global Interpreter Lock)全局解释器锁
在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少核,同时只能执行一个线程。究其原因,这就是由于GIL的存在导致的。
GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,只能利用GIL保证同一时间只能有一个线程拿到数据。而在pypy和jpython中是没有GIL的。https://www.cnblogs.com/luyuze95/p/11289143.html#%E5%A4%9A%E7%BA%BF%E7%A8%8B%E5%85%B1%E4%BA%AB%E5%85%A8%E5%B1%80%E5%8F%98%E9%87%8F
多线程参考:
https://blog.csdn.net/cui_yonghua/article/details/119917182
https://www.cnblogs.com/luyuze95/p/11289143.html
https://zhuanlan.zhihu.com/p/90180209
https://zhuanlan.zhihu.com/p/94909455
https://zhuanlan.zhihu.com/p/64702600
https://blog.csdn.net/ye__mo/article/details/123664568
三、应用
1、共享内存
一个核心,我们多线程处理时,可以使用全局变量来共享数据。但是多进程之间是不行的,那我们多进程之间应该如何共享数据呢?那就得用到共享内存了!
2、
多线程:python多线程适用在I/O密集型的任务中。对于I/O密集型任务来说,较少的时间用在cpu计算上,较多的时间用在I/O上,如文件读写,web请求,数据库请求等;
多进程:对于计算密集型任务,应该使用多进程。
python针对不同类型的代码执行效率也是不同的:
1、CPU密集型代码(各种循环处理、计算等等),在这种情况下,由于计算工作多,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。
2、IO密集型代码(文件处理、网络爬虫等涉及文件读写的操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。
对比参考:https://blog.csdn.net/cui_yonghua/article/details/119917182