机器学习进阶之(四)XGBoost-LightGBM
1. 回顾XGboost
XGBoost在竞赛与工业界都使用频繁。XGBoost是决策树的一种,那么要使用决策树过程,下面有两个弱分类器,一个以年龄性别,另一个以是否使用电脑,这是一种集成的思想,我们利用叶子节点与权值来表示预测值。
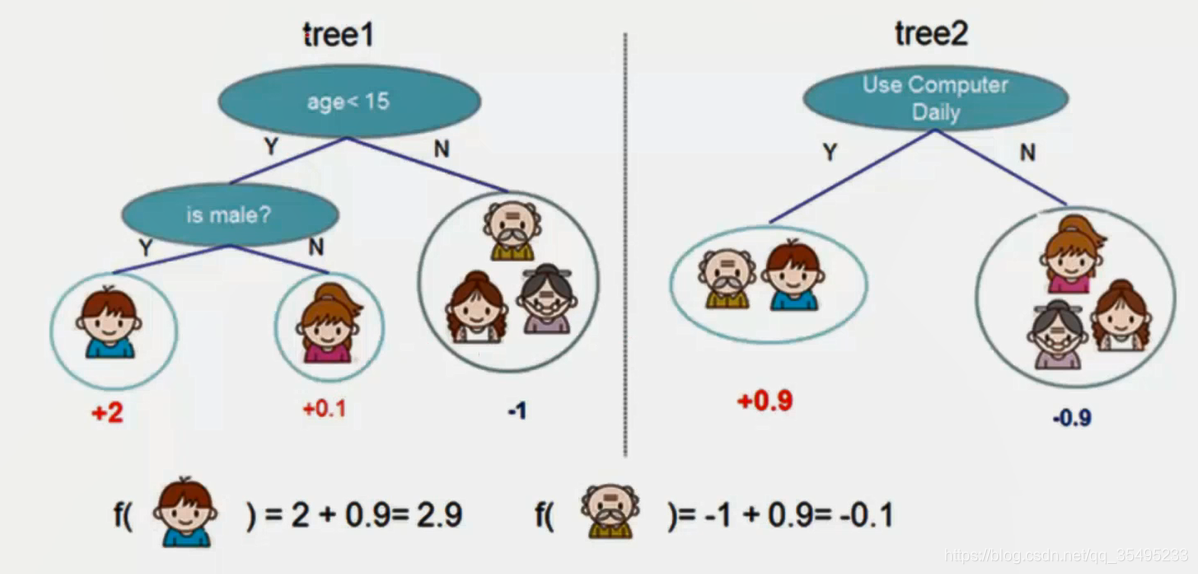
1.1 Boosting思想
Boosting是一个加法模型,从常数开始迭代,每一轮迭代增加一个函数,每次新添加的函数是基于以往所有的学习结果的和与真实值之间的残差上学习模型。
y
i(0)=0
y
i(1)=f1(xi)=y
i(0)+f1(xi)
y
i(2)=f1(xi)+f2(xi)=y
i(1)+f2(xi)
...
y
i(t)=k=1∑tfk(xi)=y
i(t−1)+ft(xi)
1.2 XGBoost损失函数
XGBoost需要对每棵树都进行综合考虑,优化目标是一个损失函数。
我们的目标函数是:
l(yi,yi)=(yi−yi)2,那么我们如何求 最优函数呢?
F∗(x
)=argminE(x,y)[L(y,F(x
))]集成算法表示:
y
i=∑k=1Kfk(xi),f∈F
XGBoost其最核心最本质的解决思路:我们构建一棵树,再构建一棵树,是有一个明显的提升的,所以在每加一棵树时,效果都有明显的提升。
y
i(0)=0
y
i(1)=f1(xi)=y
i(0)+f1(xi)
y
i(2)=f1(xi)+f2(xi)=y
i(1)+f2(xi)
...
y
i(t)=k=1∑tfk(xi)=y
i(t−1)+ft(xi)
其中,
y
i(t)是第
t轮模型预测,
y
i(t−1)保留前面
t−1轮模型预测,
ft(xi)为加入的一个新函数,那么没加入一棵树都有一定的损失函数,我们可以将
fx(xi)看成是一棵树,每加入一棵新的树所构造出来的模型。
1.3 正则化构建公式
根据决策树来构建树,那么我们需要限制叶子结点的个数,那么我们在做损失函数(也就是目标函数)时,考虑加入正则化项来防止过拟合。这里采用L2正则化,需要重新定义
Ω(ft)=γT+21j=1∑Tωj2

这个
Ω表示对于这个XGboost来说,这个正则化惩罚项是如何表示的,目标函数为:
Obj(t)=i=1∑n(yi−(y
i(t−1)+ft(xi)))
=i=1∑n[2(y
i(t−1)+ft(xi)+ft(xi)2)]+Ω(ft)+constant,也就是不断修正我们全部要预测的残差达到模型最准确的值。
1.4 泰勒展开公式
泰勒公式是一个用函数在某点的的信息描述其附近取值的公式,局部有效性。
f(x)=n=0∑∞n!f(x0)(n)(x−x0)n
一阶泰勒展开:
f(x)≈f(x0)+f′(x0)(x−x0)
二阶泰勒展开:
f(x)≈f′(x0)(x−x0)+21f′′(x0)(x−x0)2
假设第
t次迭代的为
x(t),则
t+1次迭代为:
x(t+1)=x(t)+Δx,那么,在
x(t+1)处进行泰勒展开,结果为:
f(x(t+1))≈f(x(t))+f′(x(t))Δx+21f′′(x(t))(Δx)2

将样本上的遍历转换为叶子节点上的遍历:

1.5 寻找最优分裂点
对于一个叶子节点,如何进行分裂?
Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
公式中每个点如下:
-
HL+λGL2:左子树分数
-
HR+λGR2:右子树分数
是右节点的得分值
-
HL+HR+λ(GL+GR)2 不可分隔的叶子节点的分数
-
−γ:是通过引入额外叶子节点所降低复杂度
若
Gain>0,那么节点应该分裂,若小于0,则不分裂。
1.6 算法流程
对于上述公式:
Obj(t)≈i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)+const
=j=1∑T[(i∈j∑gi)wi+21(i∈Ij∑hi+λ)wj2]
其中,关于一阶导数,二阶导数有如下定义,其中
i为训练集中的第
i个样本,
Ij为模型中第
j个叶子节点中所有的训练样本。
Gi=i∈Ij∑gi,Hj=i∈Ij∑hi
对于一元二次函数:
argminxGx+21Hx2=−HG,H>0
minxGx+21Hx2=−21HG2因此,对于目标函数进行最小化的时候,即二次函数在对称轴时,取得最值。
minObj(t)=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT=21j=1∑THj+λGj2+γT对于正则化项,
wi为第
i个叶子节点的值。
Ω(ft)=γT+21γj=1∑Twj2
-
T:叶子节点的数量
-
∑j=1Twj2:L2正则化叶子的得分值。
其中,在遍历每个叶子节点的过程时,每次遍历都是一个查看变换的过程。
1.7 实例分析
Obj代表了我们指定一棵树的时候,我们在目标上最多减多少分数
structurescore,可以认为这类似于吉尼系数一样增加对于树结构进行打分的函数,下面是一个具体的打分函数实例:
G是一阶导,
H是二阶导。

2. 回顾LightGBM
2.1 LightGBM模型实例
2.2 LightGBM参数实例
markdown公式参考:
(1). https://www.cnblogs.com/peaceWang/p/Markdown-tian-jia-Latex-shu-xue-gong-shi.html
(2). https://jzqt.github.io/2015/06/30/Markdown中写数学公式/