本文介绍两种数据归一化方法:最值归一化 (Normallization)和均值方差归一化(Standardization)
什么是数据归一化方法,来一个百度百科艰苦的解释:归一化方法有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
简单的来说,就是把所有的数据映射到同一个尺度
最值归一化 (Normallization)
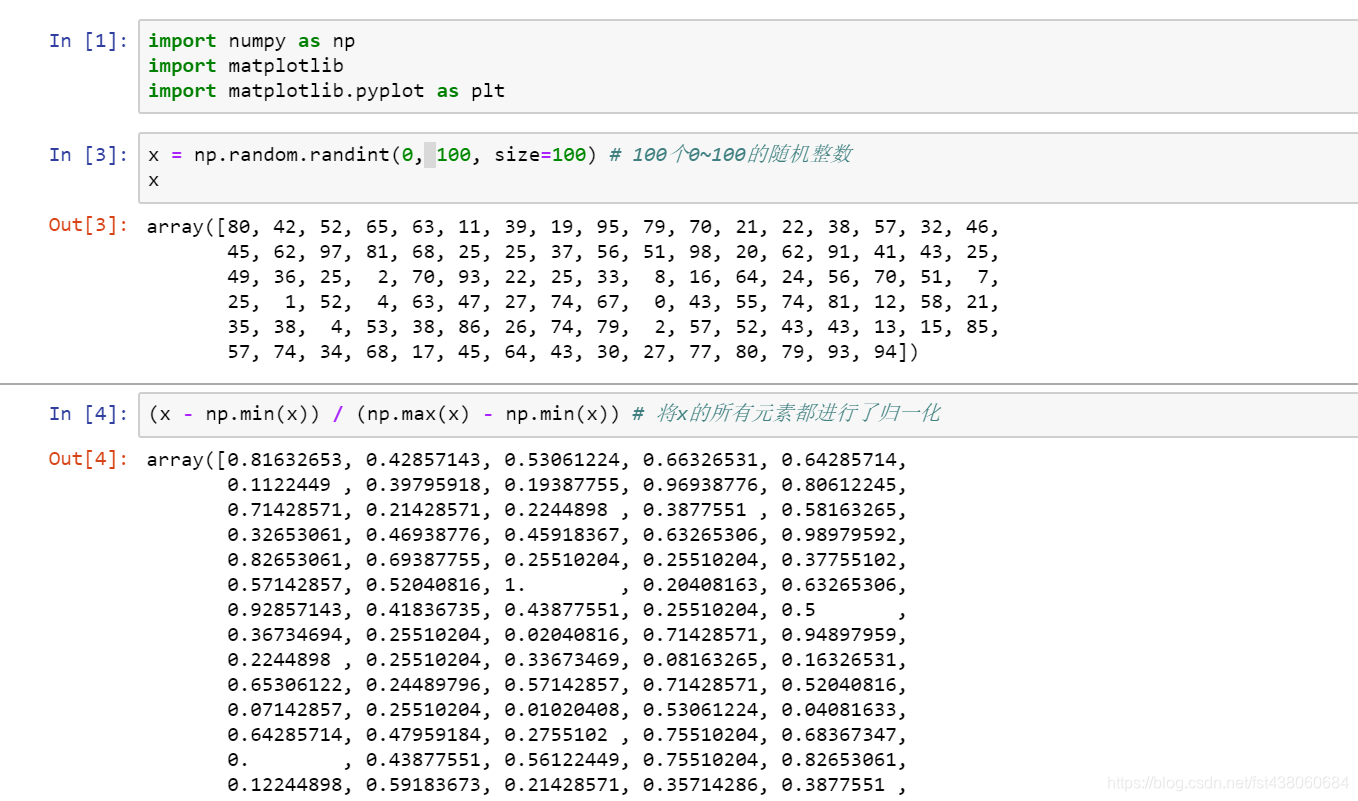
把所有的数据映射到0-1之间,公式:
对于怎么理解这个公式,把
变为0,理解起来就很容易,所有的数都不超过1。
首先看一个向量的归一化
然后看矩阵的:
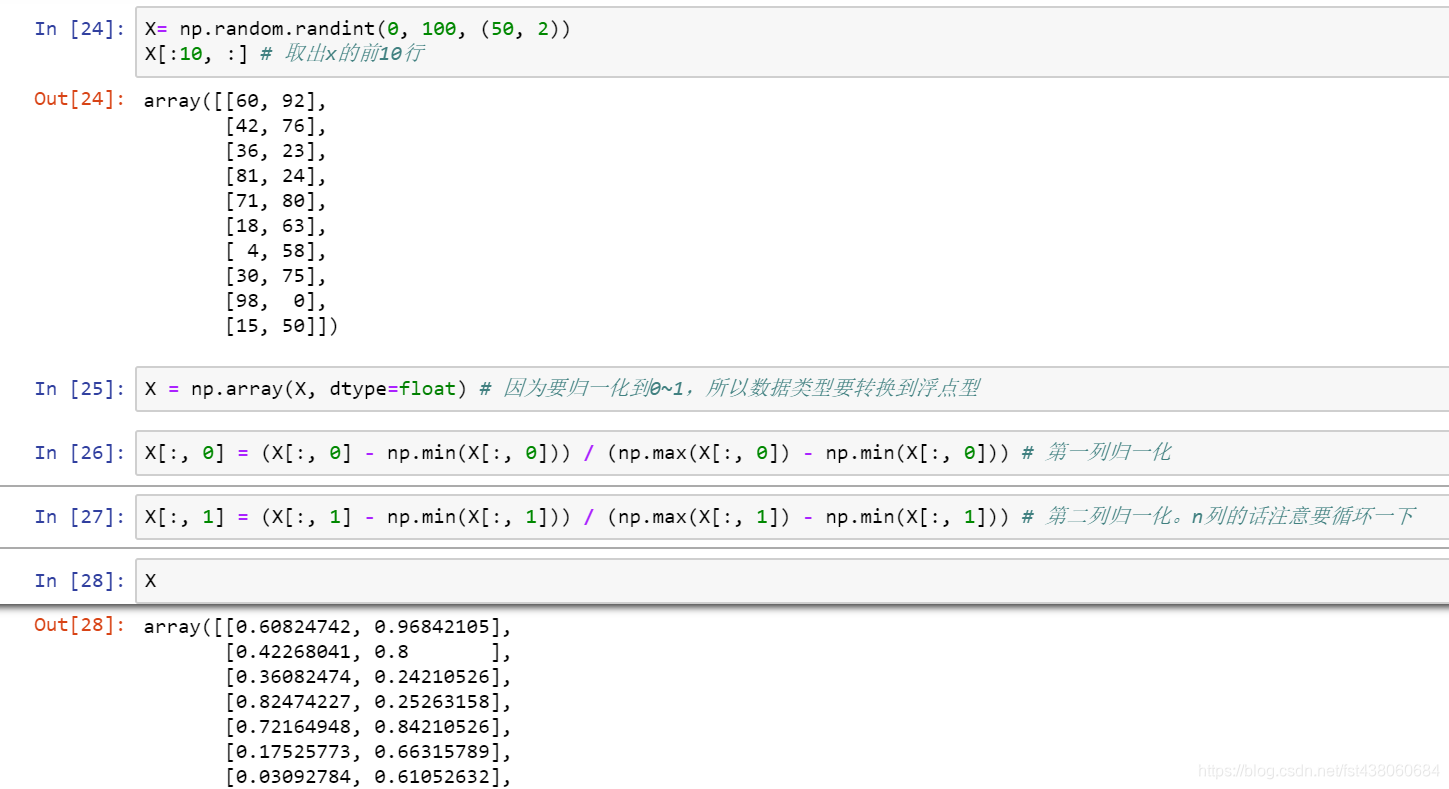
最后看他们的一些统计情况:
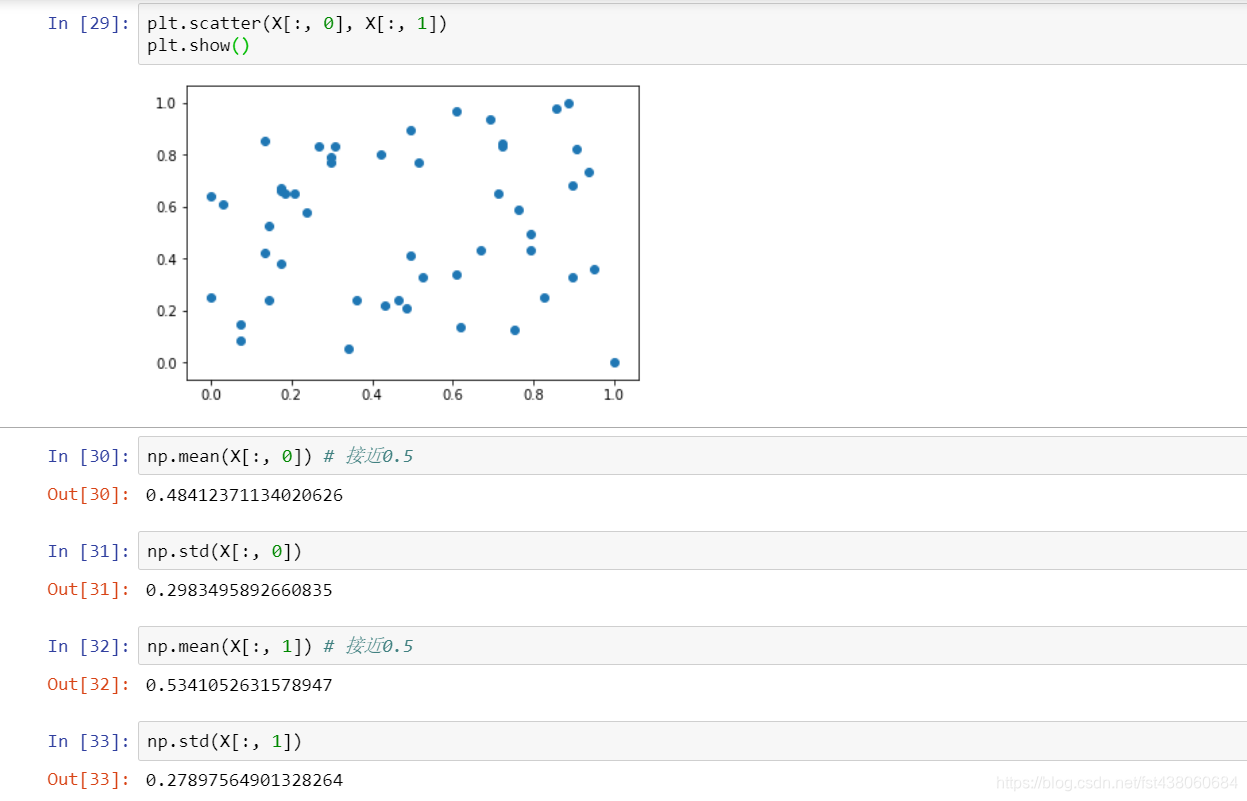
适用于分布有明显边界的情况:受边界影响比较大。如果存在极端数据,那这种方式不合适,就要用下面的方式。
均值方差归一化(Standardization)
把所有数据归一到均值为0方差为1的分布中
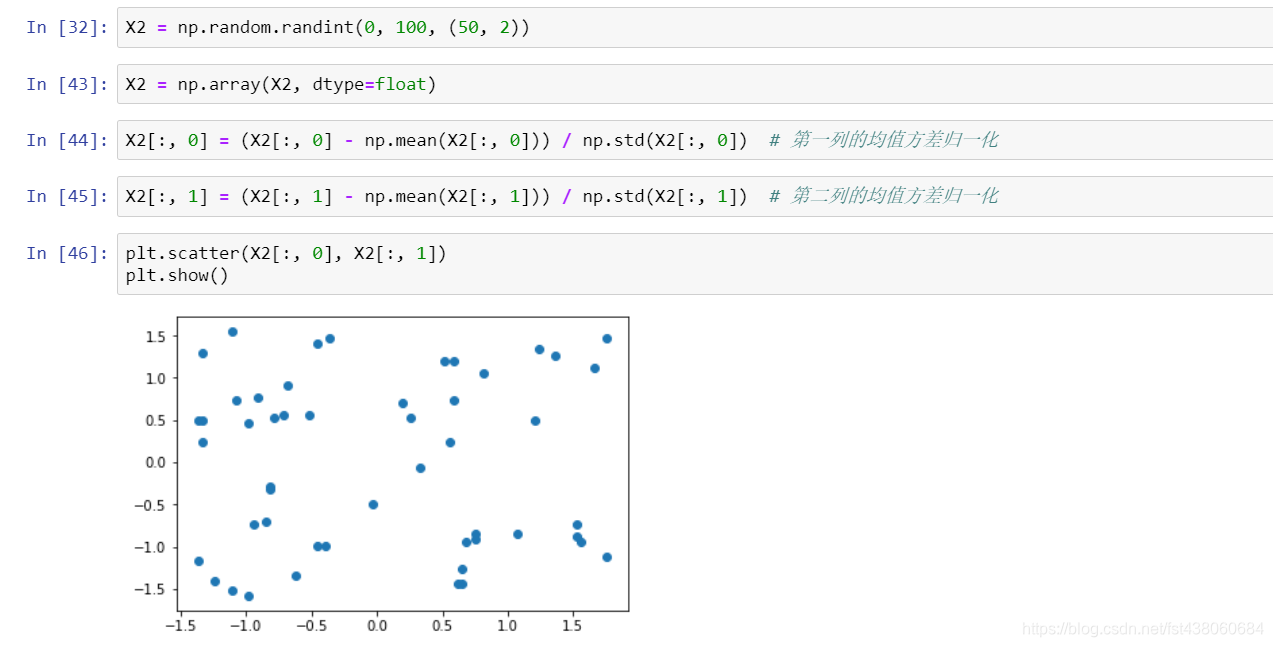
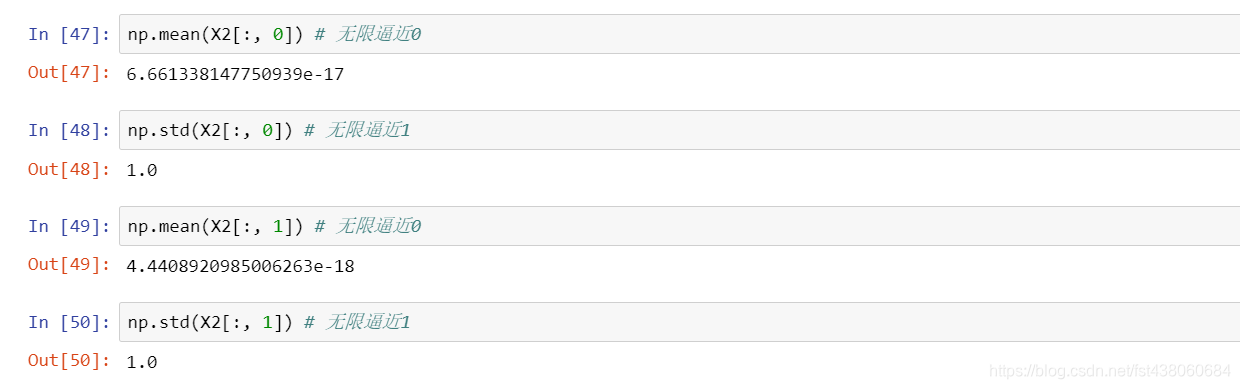
适用于数据分布没有明显边界;有可能存在极端数据的情况。