归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为标量。 在多种计算中都经常用到这种方法。在对数据进行算法训练时,由于数据的问题可能导致算法的效果并不理想,这时候可以考虑一下对数据进行归一化方法。
比较常用的又线性归一化,0均值归一化,以及其他数学函数演变而来的归一化方法。下面列出我所用过的归一化方法。
- 线性归一化—Min-Max归一化。公式如下
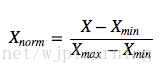
Xnorm是归一化后的值,Xmax,Xmin为归一化前数据的最大值和最小值。该方法把数据压缩到区间[0, 1]之间,是原数据的等比缩放。如果最大值和最小值相等需要注意是没法归一化的。所有的值相等没有区别。
例子:元数据:DataFrame

归一化代码:
def my_max_min(x):
return (x-min(x))/(max(x)-min(x))
df = df.agg(my_max_min)
Sklearn库实现Max-Min归一化:
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
Xnorm = min_max_scaler.fit_transform(df)
print(Xnorm)# <class 'numpy.ndarray'>

可以看到和上面自己写的函数一模一样,只是输出的格式是ndarray格式。
注:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以尝试这种归一化方法。
- 0均值归一化:公式如下
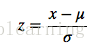
x是原始数据, u是原始数据的均值,σ原始数据的标准差。0均值归一化方法将原始数据集归一化为均值为0、方差1的数据集.
例子:
def my_mean_norm(x):
return (x-np.mean(x))/np.std(x)
df = df.agg(my_mean_norm)
print(df)
min_max_scaler = preprocessing.StandardScaler()
Xnorm = min_max_scaler.fit_transform(df)
print(Xnorm)

注:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
- Atan()归一化:公式如下:
y=atan(x)*2/PI
画出曲线如下图:
X = np.linspace(-10, 10, 100)
y = [math.atan(x)*2/math.pi for x in X]# math.atan(x) x不能是数组只能是一个值
plt.plot(X, y)
plt.show()
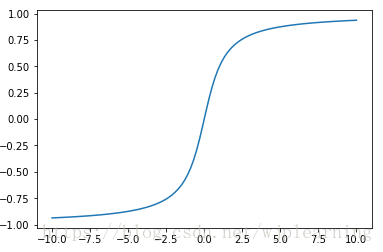
可以看到此函数把数据压缩有(-1, 1)之内了。
- Log10()压缩数据,公式如下:(或者对应其他数为底的数据压缩都可以)

def my_log(x):
return np.log10(x) / np.log10(max(x))
df = df.agg(my_log)
print(df)

注意:除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1,这样才能保证归一化后的数据在[0-1]之间,适用范围有限。
- 模糊量化模式,公式如下:
1/2+1/2*sin(pi/(max-min)*(x-(max-min)/2))
归一化:
def my_mohu(x):
return 1/2.0+np.sin((math.pi**(x-(max(x)-min(x))/2.0))/(max(x)-min(x)))/2.0
df = df.agg(my_mohu)
print(df)

下面几个在神经网络里面用的激活函数,是为了增加非线性因素,有时候也可以考虑一下对数据的压缩转换。
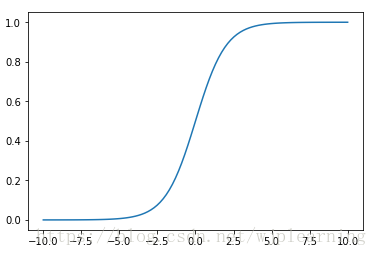
- Logistics转换,也就是sigmod激活函数。

函数图形:
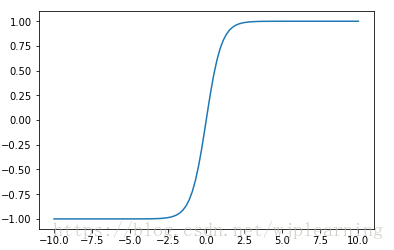
- tanh函数
公式如下:
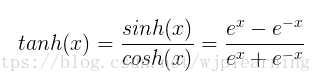
函数图形:
- ReLU函数,公式如下:
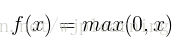
函数图形: