FPN(Feature Pyramid Networks):特征金字塔网络,是用来提取不同尺度特征图的,提供给后面的网络执行预测任务。
为什么需要FPN呢?简要介绍一下,在目标检测的网络中,要识别不同大小的物体是该网络实现检测的基本的需要。最常见的方法就是对图像金字塔取特征图,但是该方法需要大量的算力和内存,后面又使用了其他几种方法,我们下面会介绍,最终作者提出了FPN的网络能够实现对小物体很好的检测效果。这是为什么呢?后面介绍。
FPN的论文链接: https://arxiv.org/abs/1612.03144
论文翻译:https://blog.csdn.net/itlilyer/article/details/108952700
几种金字塔方案
这里借用一下FPN论文里面的图:
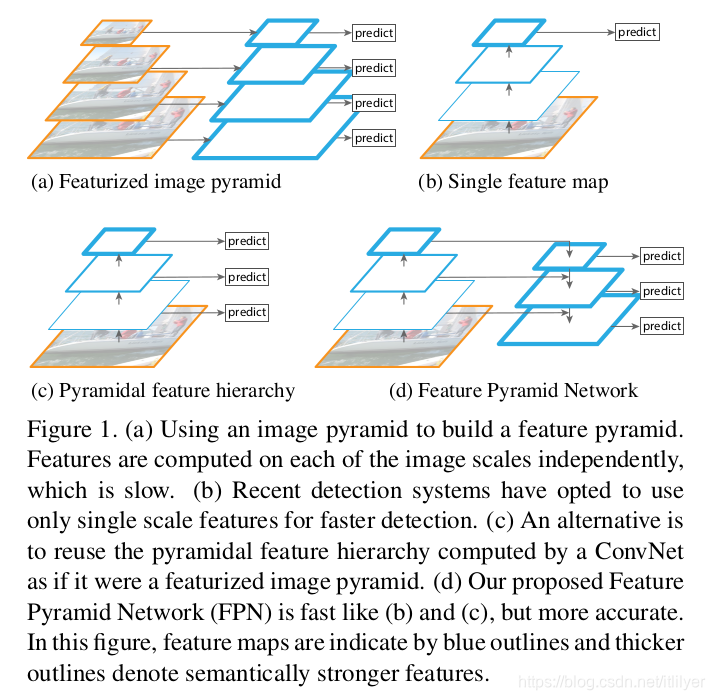 第一种金字塔: 也就是图中的a,翻译一下大概意思是使用图像金子塔来创建一个特征金字塔,每个尺度的图像分别计算其特征。也就是说要先使用原图来创建一个图像金字塔,然后再计算每个尺度图像的特征生成一个特征金字塔。这种金字塔大量用于手工创建特征,对最终的精度也起到了至关重要的作用,为了达到比较好的精度结果,每一个octave可能需要10种不同scale。(octave 在FPN的论文翻译中简单介绍了一下,这里就不再说了)。特征化图像金字塔的优点是它创建的多尺度特征的所有层次都包含很强的语义特征,包括高分辨率的层次。这种方法的优点是精度比较高;但是缺点也很明显,那就是需要大量的算力和内存空间。而且图像金字塔通常用于测试阶段,这就导致了训练和测试的不一致。
第一种金字塔: 也就是图中的a,翻译一下大概意思是使用图像金子塔来创建一个特征金字塔,每个尺度的图像分别计算其特征。也就是说要先使用原图来创建一个图像金字塔,然后再计算每个尺度图像的特征生成一个特征金字塔。这种金字塔大量用于手工创建特征,对最终的精度也起到了至关重要的作用,为了达到比较好的精度结果,每一个octave可能需要10种不同scale。(octave 在FPN的论文翻译中简单介绍了一下,这里就不再说了)。特征化图像金字塔的优点是它创建的多尺度特征的所有层次都包含很强的语义特征,包括高分辨率的层次。这种方法的优点是精度比较高;但是缺点也很明显,那就是需要大量的算力和内存空间。而且图像金字塔通常用于测试阶段,这就导致了训练和测试的不一致。
第二种金字塔: 由于种种的原因,在Fast R-CNN和Faster R-CNN中默认的配置没有使用图像金字塔,使用了图中第二种金字塔,但只取了最后一层特征。在到后来人工特征就被通过深度卷积网络计算特征替代了。深度卷积网络不仅可以表示更高层次的语义,对尺度的变化也有更好的鲁棒性,因此可以使用一个尺度的输入计算的特征来进行识别任务。第二种金字塔中只使用了最后卷积层的结果,卷积网络中的不同层次会产生不同空间分辨率的特征图,但是不同的卷积层得到的特征图会有很大的语义鸿沟。高分辨率具有很好的低层次特征,但是不利于识别物体,低分辨率的特征具有很好的高层次特征,但是不利于识别小物体。
第三种金字塔: SSD网络中使用的是第三种金字塔,SSD中将卷积网络中不同层计算出的特征图组成了一个特征金字塔。但是为了避免使用低层次的特征,在构建特征金子塔的时候是从后面的层次开始,并且又追加了几个新层。这样就损失了高分辨率的特征图,对检测小目标是不利的。
第四种金字塔: 也就是主角FPN,目的是只使用一个尺度的输入创建一个所有层次都具有很强语义特征的特征金字塔。主要分了自下向上的一条路径和自上到下的一条路径。自下向上就是深度卷积网络的前向提取特征的过程,自上而下则是对最后卷积层的特征图进行上采样的过程,横向的连接则是融合深层的卷积层特征和浅层卷积特征的过程。这也就是为什么对小物体也有很好的检测效果,它融合了深层卷积层的高级别特征和浅层卷积层的低级别特征。
FPN的计算过程
再贴一张论文中的图:
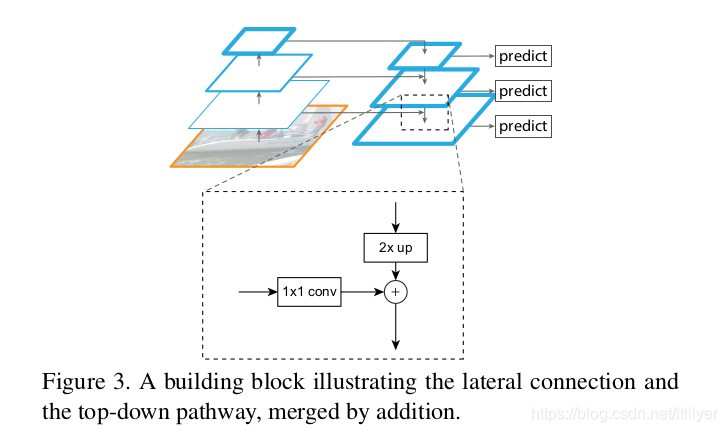
前面也简单介绍了整个的过程,下面我们再分步说一下:
第一步: 自下而上的路径。取深度卷积网络,也就是backbone网络中每个stage的输出作为我们金字塔的一个层,例如以resnet作为backbone,我们取conv2,conv3,conv4,conv5这几个残差块的最后输出组成特征金字塔,也就是上图中左边的金字塔。我们记为{C2 , C3 , C4 , C5},对应的stride为{4, 8, 16, 32}。因为会占用大量的内存,没有取第一个残差块的输出。
第二步: 自上而下的路径。将空间信息少但是语义信息强的最深层卷积层的输出,也就是上面的C5进行2倍的上采样,我们分别记为{T2 , T3 , T4 , T5},首先将C5执行1x1的卷积得到T5,T4等于T5的上采样,一次类推。这样T3 , T4 , T5分别和C3 , C4 , C5对应。
第三步: 利用横向连接将第一步和第二步的结果merge到一起。首先将{C2 , C3 , C4 , C5}执行1x1的卷积来降低通道的维度,使其与{T2 , T3 , T4 , T5}对应。
第四步: 在merge得到的结果后面接一个3x3的卷积来减轻上采样的混叠效应(aliasing effect)。