版权声明:本文为博主原创文章,欢迎转载,转载请注明出处。 https://blog.csdn.net/cjh_jinduoxia/article/details/84995156
概述
变分自编码器(Variational auto-encoder,VAE) 是一类重要的生成模型(generative model),它于2013年由Diederik P.Kingma和Max Welling提出。2016年Carl Doersch写了一篇VAEs的tutorial,对VAEs做了更详细的介绍,比文献更易懂(墙裂推荐)。
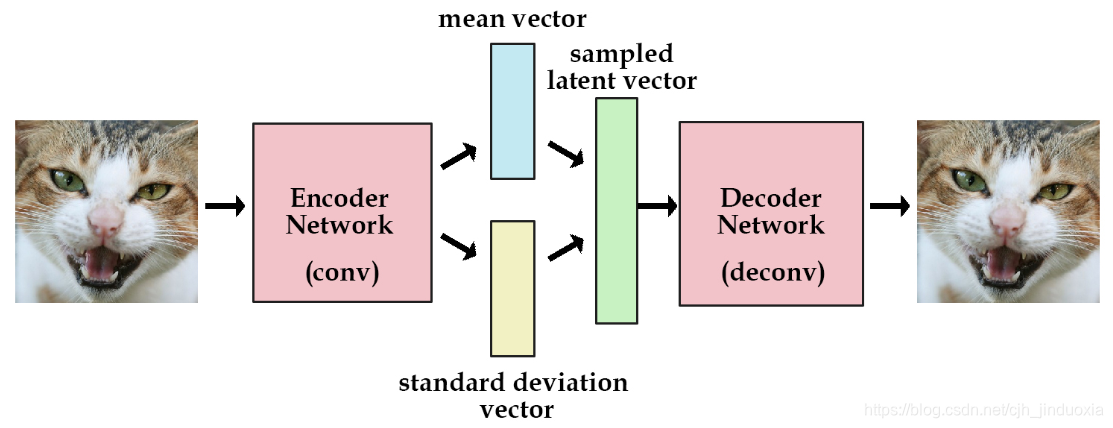
vae是什么:vae就是通过Encoder对输入(我们这里以图片为输入)进行高效编码,然后由Decoder使用编码还原出图片,在理想情况下,还原输出的图片应该与原图片极相近。
vae网络结构组成:可以大致分成Encoder和Decoder两部分(如下图)。对于输入图片,Encoder将提取得到编码:一个mean vector和一个deviation vector,然后将这个编码(两个vector)作为Decoder的输入,最终输出一张和原图相近的图片。
VAE公式推算
定义函数: 由上面可知,vae想要还原输出的图片与原图片尽量相似。对于这个目标,我们也可以换一个角度想:只看decode,其输入是从一个固定分布中抽取的编码,只要decode最后输出的图片与我们训练的数据库中的图片尽量相似就好。那么如何衡量这个相似程度呢,如果还原输出的图片集中出现训练集中的原图的概率越大,那么我们也可以认为输出与原图片越相似了,即:相似度=原图出现的概率。也即通过训练使得下式最大化。
max L=x∑logP(x)while P(x)=∫zP(z)P(x∣z)dz
上式中假设整个系统产生某张图片
x的概率是
P(x);编码器Encoder使用
q(z∣x)来表示,表示当输入图片
x时,Encoder输出编码
z的概率;
P(z)表示从某一固定分布(常用标准正态分布)中随机采样得到编码z的概率;解码器Decoder使用
P(x∣z)来表示,表示当输入编码
z时,输出图片
x的概率。
公式推导: 对于上述公式,并没有出现编码器Encoder,所以下面通过将
q(z∣x)加入式子中,然后通过推导,以解释训练的过程及损失函数的定义。
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧logP(x)=∫zq(z∣x)logP(x)dz=∫zq(z∣x)log(P(z∣x)P(z,x))dz=∫zq(z∣x)log(q(z∣x)P(z,x)P(z∣x)q(z∣x))dz=lower bound Lb
∫zq(z∣x)log(q(z∣x)P(z,x))dz+KL(q(z∣x)∣∣P(z∣x)≥0
∫zq(z∣x)log(P(z∣x)q(z∣x))dz≥lower bound Lb
∫zq(z∣x)log(q(z∣x)P(x∣z)P(z))dz
于是得到下面的式子:
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧logP(x)={Lb+KL(q(z∣x)∣∣P(z∣x))}≤0KL(q(z∣x)∣∣P(z∣x))≥0Lb=∫zq(z∣x)log(q(z∣x)P(x∣z)P(z))dz≤0
对于
Lb,可以再次进行分解如下:
⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧Lb=∫q(z∣x)log(q(z∣x)P(z,x))dz=∫q(z∣x)log(q(z∣x)P(x∣z)P(z))dz=−KL(q(z∣x)∣∣P(z))
∫q(z∣x)log(q(z∣x)P(z))dz+∫q(z∣x)logP(x∣z)dz
VAE训练过程
训练的最终目标
max L=x∑logP(x)=x∑log∫zP(z)P(x∣z)dz
其中
x表示从真实图片数据中随机抽取的图片。实际上,要最大化上式,也就是最大化每张真实图片
x出现的概率,也就是说对于某一张图片
x,上式等同于:
max L=x∑logP(x) ⟹each xmax logP(x)
下面的过程中,仅仅是以一张图片
x作为讨论对象,通过训练达到:
max logP(x)
训练步骤,两步走
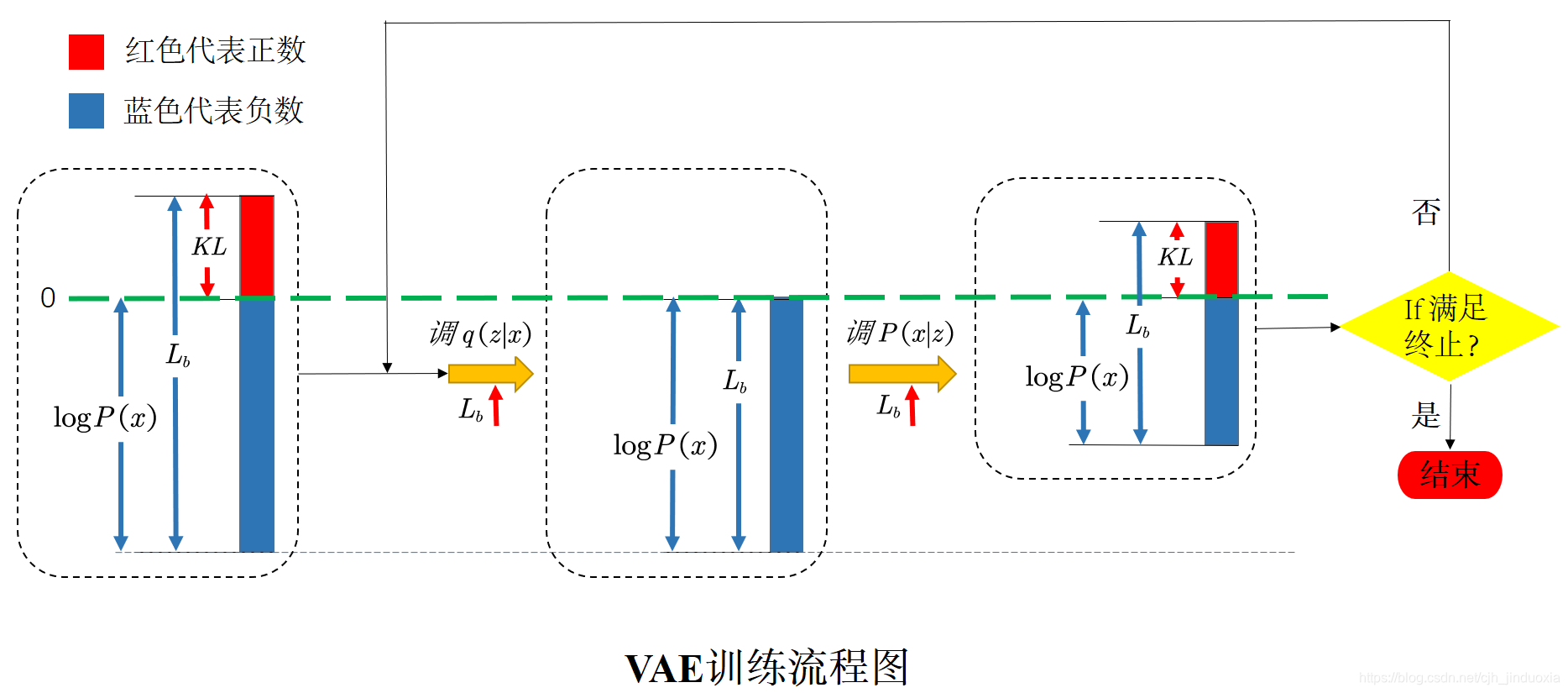
VAE的训练过程中,我认为实际上就是如同EM 算法,实际也是分为两步,然后两个步骤不断迭代进行(你拍一我拍一),最终使得目标函数不断变大,迭代步骤大致如上面的流程图所示(图中对于
≥0的数使用红色表示,对于
<0的数使用蓝色表示)。下面便是两个步骤的具体介绍。
1、调整Encoder( 即
q(z∣x) )增大
Lb :
由上面的推算易知,调整
q(z∣x) 不会影响到
logP(x) 值,但是能改变
Lb,又因为
logP(x)=Lb+KL(q(z∣x)∣∣P(z∣x)), 所以可以调整
q(z∣x) 使得
Lb 不断增大,在理想情况下,最终使得:
Lb=logP(x),
KL=0,如上图流程图中的第一个黄色箭头所示(注意:因为
Lb≤0,所以
Lb↑ 时其在图中的长度会变短)。
至于如何调整
q(z∣x) 使得
Lb↑ ,我们不妨看公式
Lb=−KL(q(z∣x)∣∣P(z))
∫q(z∣x)log(q(z∣x)P(z))dz+∫q(z∣x)logP(x∣z)dz,公式中右边一共有两项,那么我们如果能调整
q(z∣x) 使得两项都增大,那便能达到目标。但是可能因为第二项不好量化训练(我是这样理解的),所以在VAE的训练中,都只是使得第一项(即
−KL(q(z∣x)∣∣P(z)))不断增大,也即是不断减小
KL(q(z∣x)∣∣P(z)),实际也是让
q(z∣x)接近于
P(z)(一般将
P(z)设置为标准正态分布)。
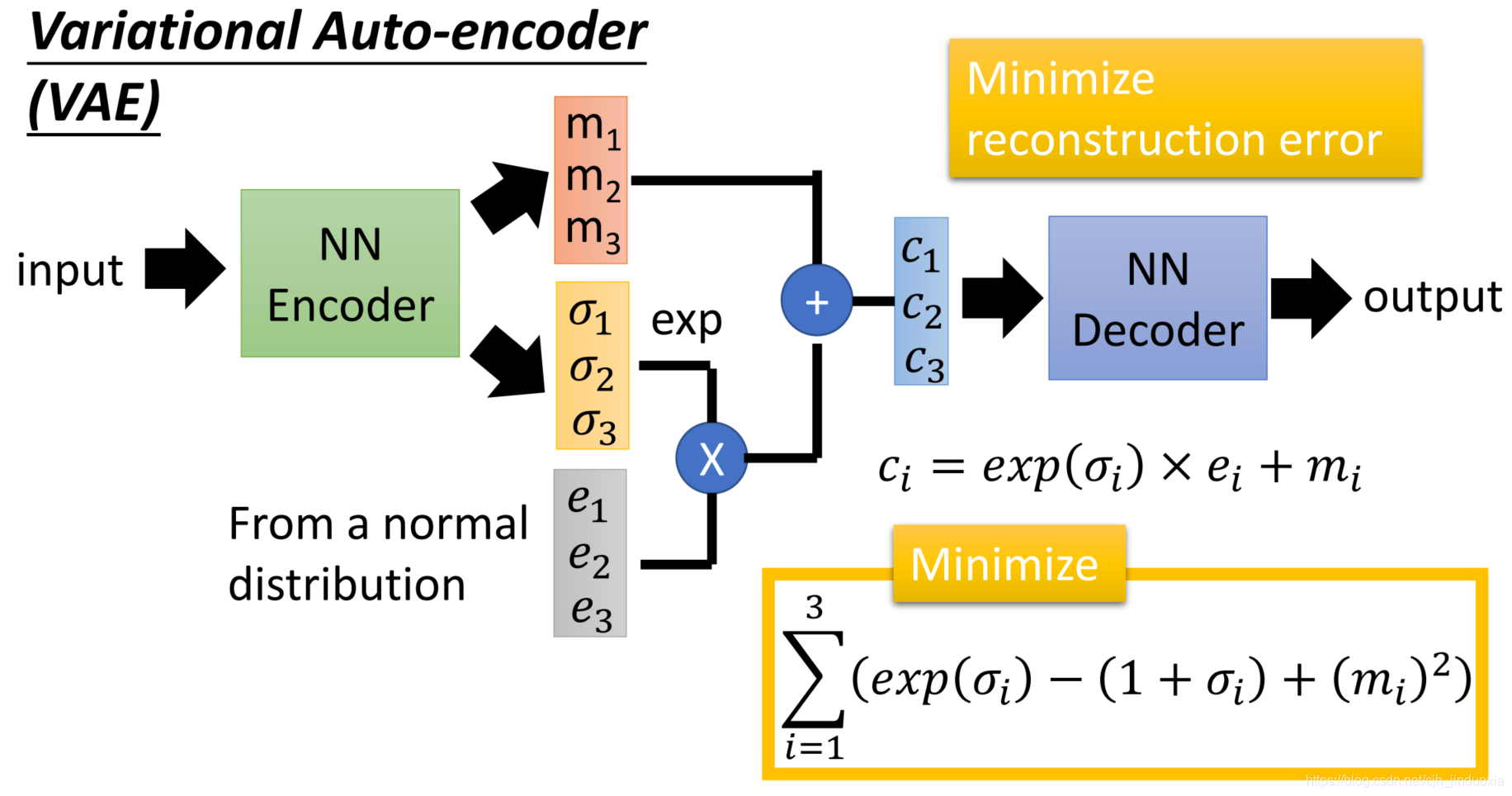
上图(图来自李宏毅老师的课件)说明了如何设置损失函数进行训练,以使得
q(z∣x)接近于
P(z)(其中
P(z)设置为标准正态分布)。其中损失函数为:
min loss1=i=1∑3(exp(σi)−(1+σi)+(mi)2)
显然可以推算,当损失函数达到最小值的时候,会有
σi=0,mi=0,实际上这个时候也就会有
zi=exp(σi)×ei+mi服从标准的正态分布,因此有
q(z∣x)=P(z)。
2、调整Decoder( 即
P(x∣z) )增大
Lb :
由推导可知,调整
P(x∣z) 不仅能改变
logP(x),也能改变
Lb。在理想情况下,经过上面一步后,会出现
KL=0,这时我们再调整
P(x∣z)使得
Lb增大,同时一定会有
KL≥0也随之变大,这样便会
logP(x)↑=Lb↑+KL(q(z∣x)∣∣P(z∣x))↑,于是
logP(x)也在变大,如前面流程图中的第二个黄色箭头所示(注意:因为
Lb≤0,所以
Lb↑ 时其在图中的长度会变短)。
至于如何调整
P(x∣z) 使得
Lb↑ ,我们不妨看公式
Lb=−KL(q(z∣x)∣∣P(z))
∫q(z∣x)log(q(z∣x)P(z))dz+∫q(z∣x)logP(x∣z)dz。显然,调整
P(x∣z) 对右边第一项是没有影响的,只会影响到第二项
∫q(z∣x)logP(x∣z)dz,由蒙特卡罗方法可以得到损失函数为:
max loss2=∫q(z∣x)logP(x∣z)dz=Eq(z∣x)[logP(x∣z)]≃L1l=1∑LlogP(x(i)∣z(i,l))
其中
x(i)是从真实数据中采样得到的第
i个数据;以
x(i)作为Encoder的输入,随后从编码器
q(z∣x(i))中抽取
L个数据
z(i,l)。实际上就是调整Decoder( 即
P(x∣z) ),使得以
x(i)作为Encoder的输入,编码采样得到多个
z(i,l),最后能用Decoder最大概率地从
z(i,l)中恢复出
x(i)。
实际训练的损失函数
在实际训练中,通常不是将上面两步分开迭代进行,而是将两步结合起来同时训练,所以最终的损失函数为:
⎩⎪⎨⎪⎧max loss=−loss1+loss2=−KL(q(z∣x)∣∣P(z))+∫q(z∣x)logP(x∣z)dz≃∑i=13(exp(σi)−(1+σi)+(mi)2)+L1∑l=1LlogP(x(i)∣z(i,l))
训练结果
上图 显示了使用MNIST数据集进行训练,最后从训练好的VAE中采样得到的图片。
