快速排序是由东尼•霍尔所发展的一种排序算法。在平均状况下,排序n个项目要求(n log n)次比较。在最坏状态下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n)算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(分而治之)策略来把一个串行(列表)分为两个子串行(子列表)。
算法步骤:
1从数列中挑出一个元素,称为“基准” (pivot),
2重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(分区)操作。
递归
的最底部情(递归) 形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(迭代)中,它至少会把一个元素摆到它最后的位置去。
快速排序是基于分治模式处理的,对一个典型子数组A [p ... r]排序的分治过程为三个步骤:
1.分解:
A [p..r]被划分为俩个可能空)的子数组A [p .. q-1]和A [q + 1 ..r],使得
A [p .. q-1] <= A [q] <= A [q + 1。
.r ] 2.解决:通过递归调用快速排序,对子数组A [p .. q-1]和A [q + 1 ..r]排序
。
代码:
#include <iostream>
using namespace std;
//exchange the 2 items a and b
void swap(int &a, int &b)
{
if (a == b)
return;
a = a + b;
b = a - b;
a = a - b;
}
//ergodic the buf and print it
void print(int *p, int length)
{
for (int i = 0; i < length; i++)
{
cout << p[i] << " ";
}
}
/*
quitSort
*/
int getPartion(int *array, int low, int high)
{
int key = array[low];
while (low < high)
{
while (low < high && key <= array[high]) //如果array[high]大于键值,那么本就应该在键值右边
high--; //因此将high下标向前移动,直至找到比键值小的值,此时交换这两个值
swap(array[low], array[high]);
while (low < high && key >= array[low])
low++;
swap(array[low], array[high]);
}
return low;//返回key值的下标
}
void QuitSort(int *buf,int low,int high)
{
if (low < high)
{
int key = getPartion(buf, low, high);
QuitSort(buf, low, key - 1);
QuitSort(buf, key + 1, high);
}
}
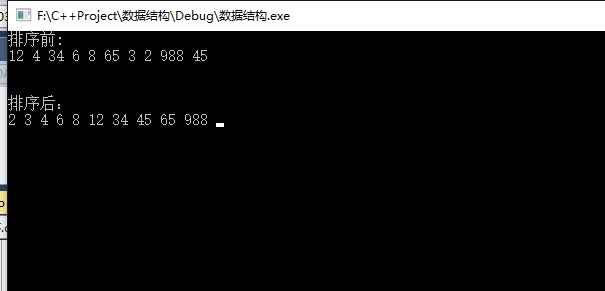
int main(int argc, char *args[])
{
int buf[10] = { 12, 4, 34, 6, 8, 65, 3, 2, 988, 45 };
int m = sizeof(buf);
cout << "排序前:" << endl;
print(buf, sizeof(buf) / sizeof(int));
QuitSort(buf, 0, sizeof(buf) / sizeof(int)-1);
cout << "\n\n\n排序后:" << endl;
print(buf, sizeof(buf) / sizeof(int));
getchar();
}运行结果:
这种实现方法便于理解,在算法导论中给了另一种分解方法
快速排序伪代码(来自算法导论)
QUICK_SORT(A,p,r)
if(p<r)
then q <—— PARTITION(A,p,r)
QUICK_SORT(A,p,q-1)
QUICK_SORT(A,q+1,r)
//核心函数,对数组A[p,r]进行就地重排,将小于A[r]的数移到数组前半部分,将大于A[r]的数移到数组后半部分。
PARTITION(A,p,r)
pivot <—— A[r]
i <—— p-1
for j <—— p to r-1
do if A[j] < pivot
i <—— i+1
exchange A[i]<——>A[j]
exchange A[i+1]<——>A[r]
return i+1 int getPartion2(int array[], int low, int high)
{
int pivot = array[high];
int i = low - 1;
int j, tmp;
for (j = low; j < high; ++j)
if (array[j] < pivot)
{
tmp = array[++i];
array[i] = array[j];
array[j] = tmp;
}
tmp = array[i + 1];
array[i + 1] = array[high];
array[high] = tmp;
return i + 1;
}最坏情况
无论哪适用一种方法来选择枢轴,由于我们不知道各个元素间的相对大小关系(若知道就已经排好序了),所以我们无法确定枢轴的选择对划分造成的影响。因此对各种枢轴选择法而言,最坏情况和最好情况都是相同的。
我们从直觉上可以判断出最坏情况发生在每次划分过程产生的两个区间分别包含n-1个个个元素和1个元素的时候(设输入的表有个元素)。下面我们暂时认为该猜测正确,在后文我们再详细证明该猜测。
对于有ñ个元素的表L [p..r由于函数分区的计算时间为θ(n),所以快速排序在序列情况下的复杂性有了递推式如下:
T(1)=θ(1),T(n)= T(n-1 )+ T 1)+θ(n)(1)
用迭代法可以解出上式的解为T(n)=θ(n2)。
最佳情况
如果每次划分过程产生的区间大小都为n / 2,则快速排序法运行就快得多了。这时有:
T(n)= 2T(n / 2)+θ(n), T(1)=θ(1)(3)
解得:T(N)=θ(nlogn)