版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wcandy001/article/details/79704514
(代码使用python3.6)
1.广度优先搜索算法
用途:求得通过节点最少的路径
问题:找出名字以m结尾的人,并求出you到这个人的最短路径
数据

代码实现:
from collections import deque
#无权最短路径算法:广度优先搜索算法,求得通过点最少的路径
graph={}
graph["you"]=["alice","bob","claire"]
graph["bob"]=["anuj","peggy"]
graph["alice"]=["peggy"]
graph["claire"]=["anuj","jonny"]
graph["anuj"]=["thom"]
graph["peggy"]=[]
graph["thom"]=[]
graph["jonny"]=[]
filter={}
sign=""
def test(query):
global sign
if(len(query)==0):
print("没有找到这个人")
else:
person=query.popleft()
#取出的人加入过滤器,避免重复
filter[person]=0
# 判断是否为m结尾
if(person[-1]=='m'):
print( person+": now you see me !")
sign=person
return person
else:
# 把这个人的邻居加入队列中,使用过滤器做判断,避免把拿出的人在放进去
for i in graph[person]:
if not i in filter:
query.append(i)
temp=test(query)
if(sign in graph[person]):
sign=person
return person+"->"+temp
else:
return temp
#定义队列,python deque表示一个可以前后入队出队的队列
search_query = deque()
# 先把起点的邻居加进队列
search_query += graph["you"]
print(test(search_query))结果:
thom: now you see me !
claire->anuj->thom2.狄克斯特拉算法
用途:正加权边最短路径算法
思想:遍历图,每次找出节点开销表(此开销表示为当前位置,起点到各节点的开销)中开销最小的点,然后走一步,继续迭代,注意此开销为起点到该节点,而不是当前邻居节点的开销(这是贪婪算法,时刻走当前开销最小点)
问题:从start走到end的开销最小的路径
数据:
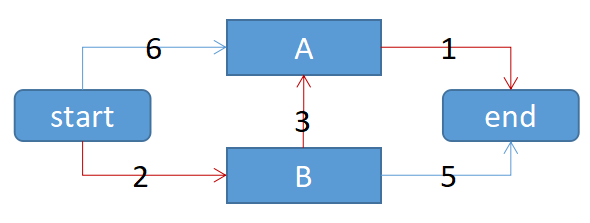
代码:
#正加权最短路径算法,狄克斯特拉算法,求得正加权当中权重最小的路径,适用范围:DAG有向无环图
#记录图信息,用途:数据遍历
graph1={}
graph1["start"]={}
graph1["start"]["A"]=6
graph1["start"]["B"]=5
graph1["A"]={}
graph1["A"]["END"]=1
graph1["B"]={}
graph1["B"]["A"]=3
graph1["B"]["END"]=5
graph1["END"]={}
#记录节点开销,即起点到该节点需要的时间,用途:迪克斯特拉算法核心,每一步都要走当前(起点到该节点)开销最小的一步
costs={}
infinity=float("inf")
costs["A"]=6
costs["B"]=2
costs["END"]=infinity
#存储父节点信息,用途:当计算结束后反推整个路线
parent={}
parent["A"]="start"
parent["B"]="start"
parent["END"]=None
filter1=[]
#获取当前节点开销中,开销最小的节点
def find_lowest_cost_node(cost):
lowest_cost=float("inf") #定义个最大值
lowest_node=None
for node in costs:
cost=costs[node]
if(cost<lowest_cost and node not in filter1):
lowest_cost=cost
lowest_node=node
return lowest_node
node=find_lowest_cost_node(costs)
while node is not None:
cost=costs[node] #获得最小开销
neighbors=graph1[node]#获得最小开销的邻居节点
for n in neighbors.keys():
new_cost=cost+neighbors[n] #走向该节点的开销
if(costs[n]>new_cost):#判断从起点走到n节点的开销是否比直接从起点到n的开销小
costs[n]=new_cost#如果小,更新节点最小开销表
parent[n]=node#更新流程 start->node->n,即记录父节点
filter1.append(node) #已经判断过node了,加入过滤器,在选择当前开销表最小开销时过滤这个点,否则会无限循环
node=find_lowest_cost_node(cost)
#递归获得整个行进流程
def get_course(sign):
if(sign!="start"):
return get_course(parent[sign])+"->"+sign
else:
return sign
print(get_course("END"))
计算结果:
start->B->A->END可自行导入自己的数据进行测试