这两天写了一个爬虫,爬取豆瓣中《流浪地球》的影评,并分析这些影评。这篇文章我不讲如何爬取的,来说一说我在爬取的过程中遇到的反爬虫。
必要的请求头的字段
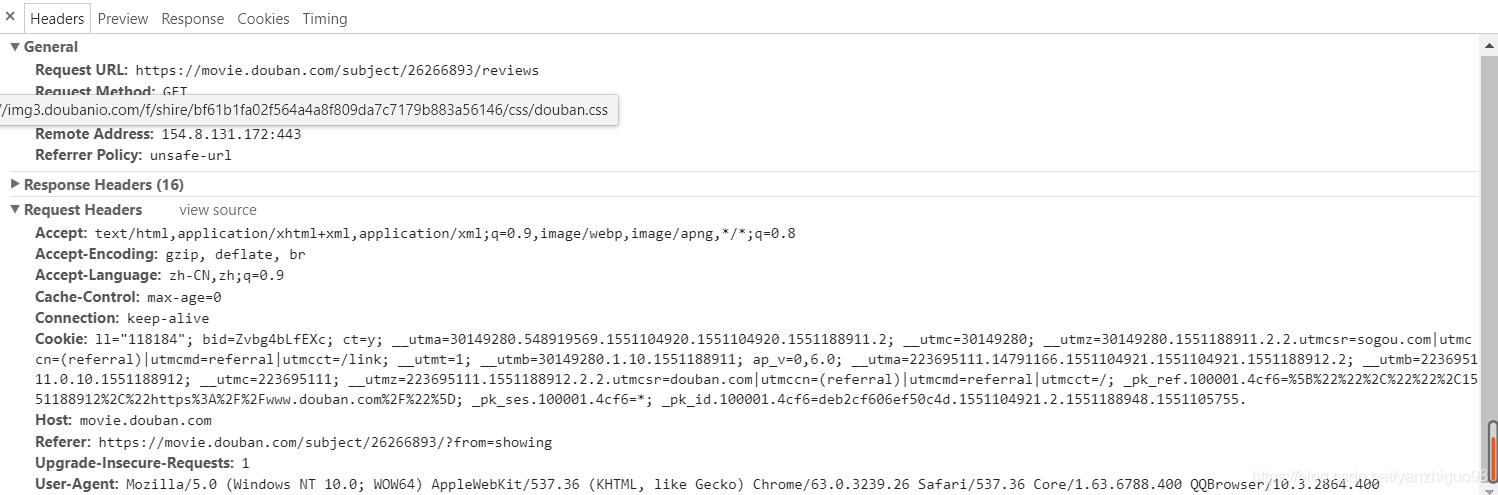
对于上面的每一个请求字段,把必要的加在请求头上,比如:referer,user-agent等。
用户登陆问题
刚开始,我认为豆瓣不需要登陆就能看到所有的评论,但是,在实际的操作过程中,如果你不登陆豆瓣网,那么每一页第10个影评你点击去必定是下面这样的:
 会出现一个登陆界面,让你登陆。然后我就用自己的微信登陆,然后又把cookie加在了请求头里,我认为这样总该可以了吧!结果(并不是自己所以为的样子)
会出现一个登陆界面,让你登陆。然后我就用自己的微信登陆,然后又把cookie加在了请求头里,我认为这样总该可以了吧!结果(并不是自己所以为的样子)
并不是每个影评的前端样式都一样
当我把自己登陆的cookie放到请求头里,我心想这次总该可以了吧。但是,爬到第二页就出了问题,我认为每一页的评论的前端样式都应该是一样的,豆瓣这个网站就是让你难受,我本来是想爬取用户的评分的,在第二页中,居然有用户没有评分,导致我的爬虫找不到那个节点,从而报错!!!!

然后我采用if条件过滤掉这种情况,我的爬虫才正常运行。可是又出问题了!!!
IP访问频率太高,把我的账号给封了
在我认为万事大吉的时候,意外又出现了,刚爬取一千多条数据,结果豆瓣因为我的爬虫访问频率太高,把我的账号都给封了,结果也爬不了了,然后我也不知道怎么办了(高手可以给小弟指点一二!!!)
总结
总而言之,这次爬取还是有收获的,知道了这些反爬虫的措施,下次在遇到自己心里就有信息来处理了。还有就是书上讲的毕竟是理论,并不是实际运行的效果,实践出真知,这句话一点没错,我们从实践中知道了自己掌握不好的地方,这条道路还长,继续努力!!!