这段时间在做毕业设计,实现对大文件的爬取,在编写的过程中遇到了一系列的问题和技术难点,本想着可以问问某度,结果发现开源精神有点匮乏呀,没办法,只能自己踩坑试错去写了!!!
对大文件爬取的知识
首先应该认识到的是,对大文件进行爬取,因为内存的原因,必须用到一项技术,什么技术呢?那就是断点续传
我们平常爬取小的文件的时候是不需要的,因为电脑的内存足够我们挥霍,但是大文件就不行了。
断点续传:就是对待下载的大文件进行片段式存储,我们平时下载文件时,不管文件多大,电脑都会等文件都接收完,然后再写到硬盘,
只写一次。如果文件太大内存就会吃不消,所以进行片段式存储势在必行,所谓片段式存储,就是预先定义好一个片段的大小,然后电脑接收的数据等于这个片段的大小时就会把这个片段写到硬盘,一个大文件进行若干次的去写,大大减轻了内存的压力。
下面是自己用python代码实现的断点续传:
import requests
header = {
'Range': 'bytes=%d-%d' % (start,end),
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'content-type': 'application/json',
'x-requested-with': 'XMLHttpRequest',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
response=requests.get(url=url,headers=header,stream=True)
if response.status_code==200:
with open(file_name,mode) as f:
for data in response.iter_content(chunk_size=1024):
f.write(data)
#注意
#1.header中的参数'Range'就是告诉服务器,你要爬去哪段的数据,start是开始点,end是结束点
#2.get中的参数必须设置stream=True,这是告诉服务器要进行流存储,也就是断点存储
#3.response.iter_content(chunk_size=1024)中的chunk_size就是当接收的文件数据满1K时就往硬盘写一次,可根据实际情况自行定义
爬取过程中进行暂停,继续,取消一系列动作
如果我们对一个文件进行爬取,想给爬取的过程增加一些动作,比如暂停,继续,取消,怎样才能让这些功能实现呢?
下面是经过博主不断踩坑试错得到的可以实现这些功能的代码(可能不是最优秀的代码,望大家多多指教!!!)
from dlpackage import model_download as dm
from dlpackage import requests_header
from dlpackage import setting
from dlpackage import share
import threading
import time
import os
# 定义的全局变量
pause_flag = False #暂停标志
cancel_flag = False #取消下载标志
length = None #用来保存已经下载文件的长度
mode = None #用来保存文件的存储模式
file_status = False #用来保存文件的打开或关闭状态
file_path_name = None #用来保存文件的存储路径
# 暂停/继续下载
def pause_or_continue():
global pause_flag
if share.m3.m.get() == '暂停下载':
share.m3.m.set('继续下载')
pause_flag = True
else:
share.m3.m.set('暂停下载')
pause_flag = False
m3u8_href = share.m3.button_url.get().rstrip()
video_name = share.m3.button_video_name.get().rstrip()
t = threading.Thread(
target=download_mp4, args=(
m3u8_href, video_name,))
# 设置守护线程,进程退出不用等待子线程完成
t.setDaemon(True)
t.start()
#取消下载的线程
def cancel_thread():
t = threading.Thread(
target=cancel)
# 设置守护线程,进程退出不用等待子线程完成
t.setDaemon(True)
t.start()
# 取消下载
def cancel():
global pause_flag
global cancel_flag
global file_status
global file_path_name
if not pause_flag:
cancel_flag = True
# 判断download_mp4()中打开的文件是否关闭,file_path_name是否被赋值,如果没有就再给它一点时间
while file_status == False or file_path_name == None:
time.sleep(1)
#移除已经下载完成的部分文件
os.remove(file_path_name)
#进度条归零
share.set_progress(0)
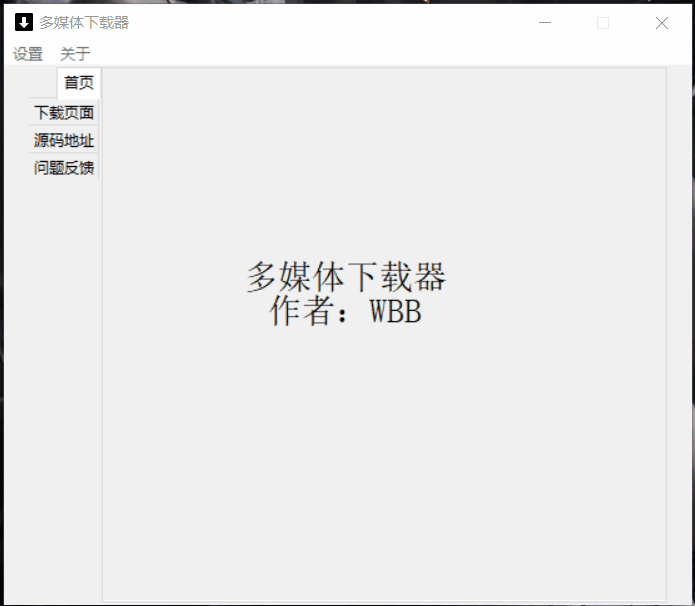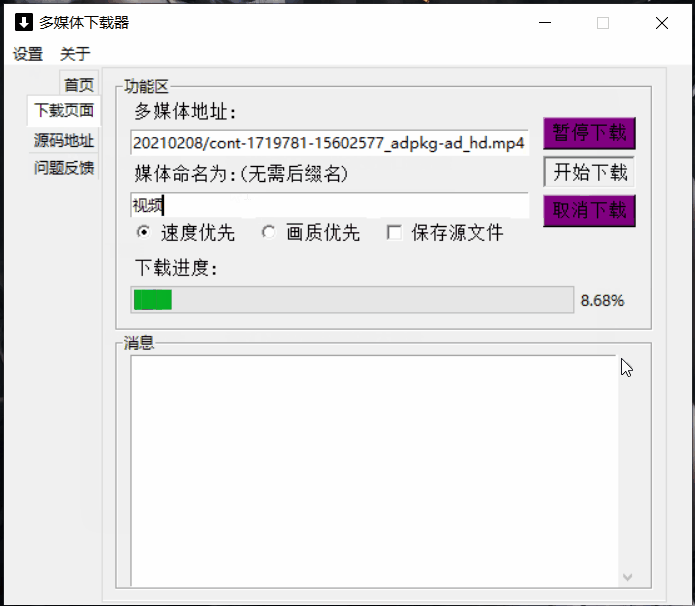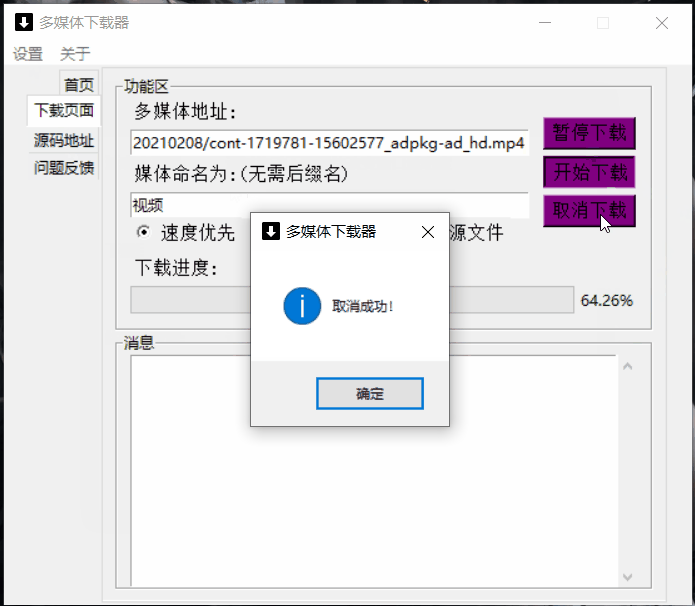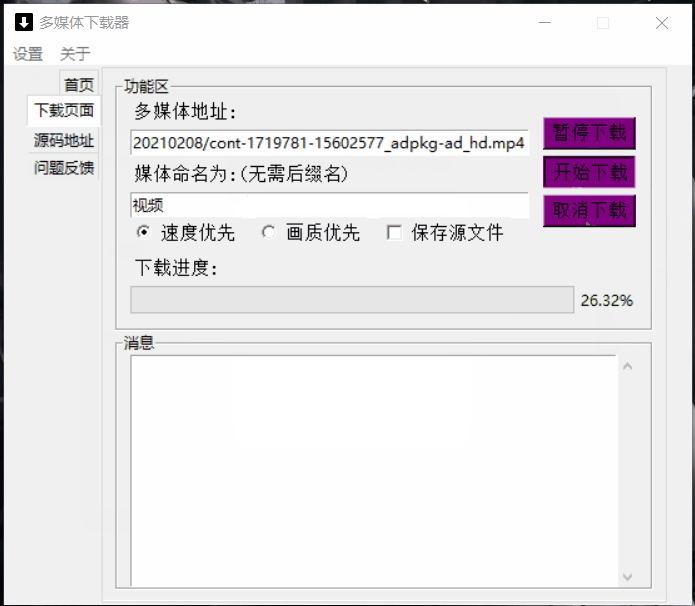
share.m3.show_info("取消成功!")
cancel_flag = False
file_status = False
file_path_name = None
else:
os.remove(file_path_name)
share.set_progress(0)
share.m3.m.set('暂停下载')
pause_flag = False
share.m3.show_info("取消成功!")
#对文件进行下载
def download_file(m3u8_href, video_name):
global length
global cancel_flag
global mode
global file_path_name
global file_status
share.m3.clear_alert()
video_name = share.check_video_name(video_name)
video_name = setting.path + "/" + video_name # 将保存路径与文件名称进行拼接
video_name = video_name + share.m3.button_url.get()[share.m3.button_url.get(
).rfind('.'):share.m3.button_url.get().rfind('.') + 4] # 将文件的后缀与整体路径进行拼接
chunk_size = 512
# 当这个文件已经下载过
if os.path.exists(
video_name):
response = dm.easy_download(
url=m3u8_href,
stream=True,
#请求头中加入'Range': 'bytes'参数实现断点续传
header=requests_header.get_user_agent1(
os.path.getsize(video_name)))
mode = 'ab'
size = os.path.getsize(video_name)
content_size = length
else:
response = dm.easy_download(
url=m3u8_href,
stream=True,
header=requests_header.get_user_agent())
mode = 'wb'
size = 0
content_size = int(response.headers['content-length'])
share.m3.alert('[文件大小]:%0.2f MB' % (content_size / 1024 / 1024))
with open(video_name, mode) as f:
for data in response.iter_content(chunk_size=chunk_size):
try:
#如果既没有暂停也没有取消下载就正常下载
if pause_flag == False and cancel_flag == False:
f.write(data)
size = size + len(data)
p = (size / content_size) * 100
share.set_progress(p)
share.m3.str.set('%.2f%%' % p)
#如果取消下载
elif cancel_flag:
f.close()
file_status = f.closed
file_path_name = video_name
break
#如果暂停下载
elif pause_flag:
f.close()
length = content_size
file_path_name = video_name
break
except BaseException:
share.m3.show_info("下载出现异常!")
if size == content_size:
share.m3.alert('下载完成!')
share.m3.show_info("下载完成!")
share.set_progress(0)
share.m3.str.set('')
以上代码是从博主的毕业设计中截取的,有部分导入的包是博主自己定义的,不过不影响对暂停,继续,取消这些功能代码的观看,理解噢!
动图演示
好了,这次的分享与总结就到这里了,如果大家有什么疑问可以在评论区留言,喜欢博主的文章的话记得点赞加关注噢!!!