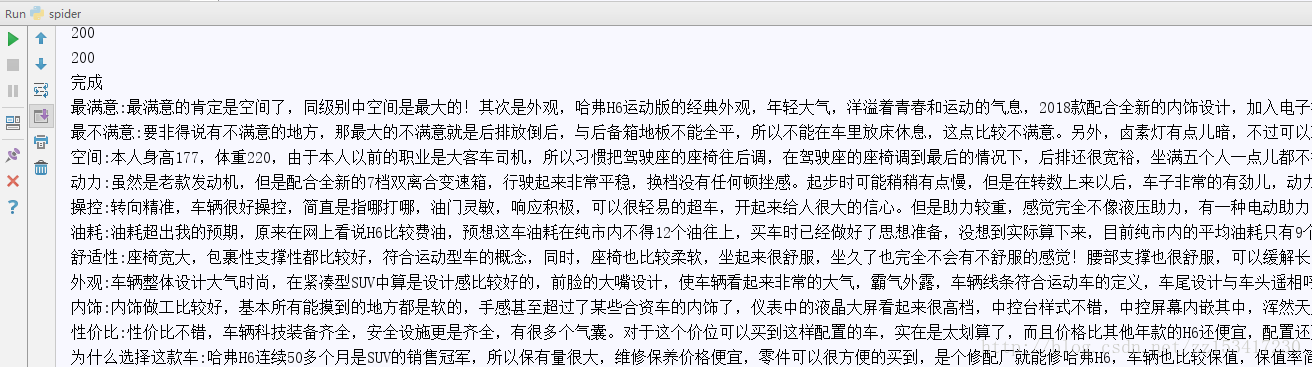
本人刚学Python没几天,代码可能比较丑陋, 大牛不要喷
用的Python2.7.2, 因为PyV8最高支持2.7.2, js混淆部分用的PyV8直接运行的js
原理已经写过一篇了,这里不再赘述了.可以看我的这篇
目录结构如下:
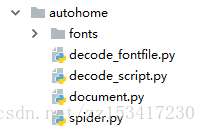
fonts文件夹负责存放下载的字体文件
decode_fontfile负责解析字体文件
decode_script负责解析js混淆
document负责模拟js中的document对象,因为PyV8中没有document对象,但是js混淆中用到了
spider是主要逻辑
下面贴一下代码:
spider.py
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
from decode_script import DecodeScript
from hero.proxy import proxy
from decode_fontfile import DecodeFontFile
import sys
reload(sys)
sys.setdefaultencoding('utf8')
class ParseHtml(object):
def __init__(self):
self.header = {"Host": "k.autohome.com.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"}
def get_html_doc(self, url):
"""根据传入的url,获得所有口碑页面的html代码"""
s = requests.Session()
resp = s.get(url, verify=False)
if resp.status_code != 200:
return 1
else:
return resp.content
def get_text_con(self, html_doc):
"""解析网页源代码,利用css属性,获得口碑内容部分的源代码"""
soup = BeautifulSoup(html_doc,'lxml')
mouth_item = soup.find_all(class_='mouth-item')[-1:][0]
text_con = mouth_item.find(class_="text-con")
return text_con
def get_font_url(self, html_doc):
"""利用正则获取字体文件链接"""
regex = r'\w+\.\w+\..*?ttf'
font_url = re.findall(regex, html_doc)[0]
return font_url
def run():
url = "https://k.autohome.com.cn/detail/view_01c16ytpa964w38c1s70v00000.html?st=2&piap=0|2123|0|0|1|0|0|0|0|0|1#pvareaid=2112108"
parse = ParseHtml()
html_doc = parse.get_text_con(url) # 获得网页源代码 ,如果状态码不是200,则返回404
if html_doc == 1:
run()
else:
# 获取字体文件链接, 并下载字体文件
font_url = parse.get_font_url(html_doc)
decode_fontfile = DecodeFontFile()
decode_fontfile.download_fontfile(font_url)
text_con = parse.get_text_con(html_doc)
decode_script = DecodeScript()
list_text = decode_script.get_text_con(text_con, decode_fontfile)
for text in list_text:
for key, value in text.items():
print(key+":"+value)
run()
decode_script.py
# -*- coding:utf-8 -*-
"""对混淆的js代码破解,获取想要的内容"""
from bs4 import BeautifulSoup
import re
import PyV8
from document import Global
from decode_fontfile import DecodeFontFile
import sys
reload(sys)
sys.setdefaultencoding('utf8')
class DecodeScript(object):
"""传入口碑的所有内容, 返回正常文本信息"""
def get_list_part(self, text_con):
"""传入口碑内容,返回拆分后的列表"""
return str(text_con).split('【')[1:]
def get_list_title_con_js(self, part_con):
"""获取标题和混淆的js代码"""
# 获取小标题
title = part_con.split("】")[0]
# 获取加密的文本
start = re.search('<!--@athm_BASE64@-->', part_con).span()[1]
end = re.search('<!--@athm_js@-->', part_con).span()[0]
part_base64 = part_con[start: end].decode("utf-8")
# 获取混淆的js代码
soup_part = BeautifulSoup(part_con, "lxml")
h_js = soup_part.find('script')
# 将标题和混淆的js存入一个列表
list_title_con_js = [title, part_base64, h_js]
return list_title_con_js
def put_js(self, js):
"""组装js代码"""
# 去掉多余字符,用切片也可以
# if '<script>' in js:
# js = js.replace('<script>', "")
# if '</script>' in js:
# js = js.replace('</script>', "")
js = str(js)[8:-9]
# 在开始处定义变量
def_var = "var result = "
js = def_var+js
# 在指定位置定义数组
first_point = js.index("{")
def_arr = "var arr = [];"
js = js[:first_point+1]+def_arr+js[first_point+1:]
# 在指定位置给数组赋值
regex = r"function\s*\w+\(\)\s*\{\s*(\w+)\s*=[\s\S]*?\);\s*(\w+)\s*=[\s\S]*?\);\s*(\w+)\s*=[\s\S]*?\);"
tuple_groups = re.search(regex, js).groups()
second_point = re.search(regex, js).span()[1]
set_arr = "arr = ["+str(tuple_groups[0])+", "+str(tuple_groups[1])+"];"
js = js[:second_point]+set_arr+js[second_point:]
# 在指定位置return数组
add_return = "return arr;"
js = js.strip()
js = js[:-13]+add_return+js[-13:]
return js
def run_js(self, js):
"""在v8中运行js,获得16进制数字和对应数字"""
glob = Global()
list_num16 = []
list_index = []
with PyV8.JSContext(glob) as ctext:
ctext.eval(js)
vars = ctext.locals
js_array = vars.result
for num16 in js_array[0]:
list_num16.append(num16)
for index in js_array[1]:
list_index.append(index)
return [list_num16, list_index]
def replace_span(self, part_con, decode_fontfile):
"""用16进制数字替换掉段落中的span"""
list_title_con_js = self.get_list_title_con_js(part_con)
title = list_title_con_js[0] #获取标题
con = list_title_con_js[1] #获取加密后段落
js = self.put_js(list_title_con_js[2]) #获取js后重新组装js
list_num16_index = self.run_js(js) #利用v8运行js,获得16进制数字和对应关系
list_num16 = list_num16_index[0]
list_num16 = list_num16[0].split(",")
list_index = list_num16_index[1]
regex = r"<span\s*class[\s\S]*?hs_kw(\d+)[\s\S]*?</span>"
list_span = re.finditer(regex, con)
for span in list_span:
tag_span = span.group().encode('unicode_escape').decode('string_escape')
index = list_index[int(span.group(1))]
num16 = list_num16[int(index)]
glyph = "uni"+num16.upper()
decode = DecodeFontFile()
font = decode_fontfile.get_font(glyph)
con = con.replace(tag_span, font)
return {title: str(con)}
def get_text_con(self, text_con, decode_fontfile):
# 传入完成口碑加密内容, 返回按标题分割的片断列表
list_part = self.get_list_part(text_con)
content = []
for part_con in list_part:
part_text = self.replace_span(part_con, decode_fontfile)
content.append(part_text)
return contentdecode_fontfile.py
# -*- coding:utf-8 -*-
"""解析字体文件"""
from fontTools.ttLib import TTFont
import requests
import re
import os
list_font = [ ' ', '一', '七', '三', '上', '下', '不', '中', '档', '比', '油', '泥', '灯', '九', '了', '二', '五',
'低', '保', '光', '八', '公', '六', '养', '内', '冷', '副', '加', '动', '十', '电', '的', '皮', '盘', '真', '着', '路', '身',
'软', '过', '近', '远', '里', '量', '长', '门', '问', '只', '右', '启', '呢', '味', '和', '响', '四', '地', '坏', '坐', '外',
'多', '大', '好', '孩', '实', '小', '少', '短', '矮', '硬', '空', '级', '耗', '雨', '音', '高', '左', '开', '当', '很', '得',
'性', '自', '手', '排', '控', '无', '是', '更', '有', '机', '来' ]
class DecodeFontFile(object):
def __init__(self):
self.file_path = ""
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
}
def download_fontfile(self, font_url):
font_url = "http://"+font_url
cont = requests.get(font_url, headers=self.headers).content
file_name = re.findall(r'\w{20,}[\s\S]*?ttf', font_url)[0]
self.file_path = "./fonts/"+file_name
with open(self.file_path, "wb") as f:
f.write(cont)
# 创建 self.font 属性
def get_glyph_id(self, glyph):
ttf = TTFont(self.file_path)
# gly_list = ttf.getGlyphOrder() # 获取 GlyphOrder 字段的值
index = ttf.getGlyphID(glyph)
# os.remove(self.file_path)
return index
def get_font(self, glyph):
id = self.get_glyph_id(glyph)
return list_font[id]
document.py
# -*- coding:utf-8 -*-
"""模拟Document对象和window对象"""
import PyV8
class Element():
def __init__(self):
self.sheet = ""
class Head(object):
def appendChild(self, *args, **kwargs):
return "sheet"
class v8Doc(PyV8.JSClass):
def createElement(self, *args, **kwargs):
return Element()
def getElementsByTagName(self, *args, **kwargs):
head = Head()
list = [head]
return list
def getComputedStyle(self, *args, **kwargs):
return None
def decodeURIComponent(self, *args, **kwargs):
return args
def querySelectorAll(self, *args, **kwargs):
return None
class Global(PyV8.JSClass):
def __init__(self):
self.document = v8Doc()
self.window = v8Doc()
输出结果