对于一个爬虫学习者来说,只懂得爬虫实现而不懂得反爬虫原理那恐怕只是半吊子水平。最近,博主就在研究反爬虫。爬虫和反爬虫相当于矛和盾的关系,二者针锋相对,共同发展。
在本次反爬虫测试中,我主要用到Nginx+Postman+Pycharm。其中,Nginx是通过阿里云服务器使用宝塔Linux面板创建个人博客时内置的,本次问题的重点就是这个Nginx服务器。因为博主一直习惯Tomcat,Nginx也是随用随学的,所以对其内部构造并不太了解,因此在钻研使用Nginx进行反爬虫测试时在Nginx的辅助配置文件测试中耗费了大量的时间。
User-Agent反爬虫原理分析
User-Agent反爬虫指的是服务器端通过校验请求头中的User-Agent值来区分正常用户和爬虫程序的手段。
User-Agent是请求头域之一,服务器能够从User-Agent对应的值中识别客户端使用的操作系统、CPU类型、浏览器、浏览器引擎、操作系统语言等。浏览器User-Agent头域值的格式为:
浏览器标识 (操作系统标识;加密等级标识;浏览器语言) 渲染引擎标识 版本信息
在网络请求中,User-Agent是客户端用于表明身份的一种标识,服务器通常通过该头域的值来判断客户端类型。注意:User-Agent头域并非不可缺少,而且其值可以被更改。
之所以选择User-Agent头域作为校验对象,是因为很多编程语言和软件都具有默认的标识。在发起网络请求时,这个标识会作为请求头参数中的User-Agent头域值被发送到服务器。比如在使用Python的requests库向服务器发送HTTP请求时,服务器读取的User-Agent值为:
python-requests/2.21.0
这相当于明明白白的告诉服务器“我是爬虫”。因此想要进行User-Agent反爬虫还是十分简单的,只需要在服务器端对User-Agent头域值进行校验即可。利用黑名单策略,将非正常客户端的关键字加入黑名单中,再利用nginx的条件判断语句即可实现这个最简单的反爬虫。
User-Agent反爬虫测试分析
如果只是在自己搭建的nginx进行User-Agent反爬虫实战测试的话,基本是没有什么问题的。因此,这里不进行阐述。接下来我们主要来说说在在阿里云服务器所搭建的个人博客中,使用宝塔Linux面板进行Nginx的反爬虫测试。
经过大量的测试,我发现在宝塔Linux面板中,最为重要的nginx配置文件路径有两个:
1.主配置文件路径(/www/server/nginx/conf):在这个路径中,nginx.conf即为主配置文件,其他.conf的文件即为辅助配置文件。
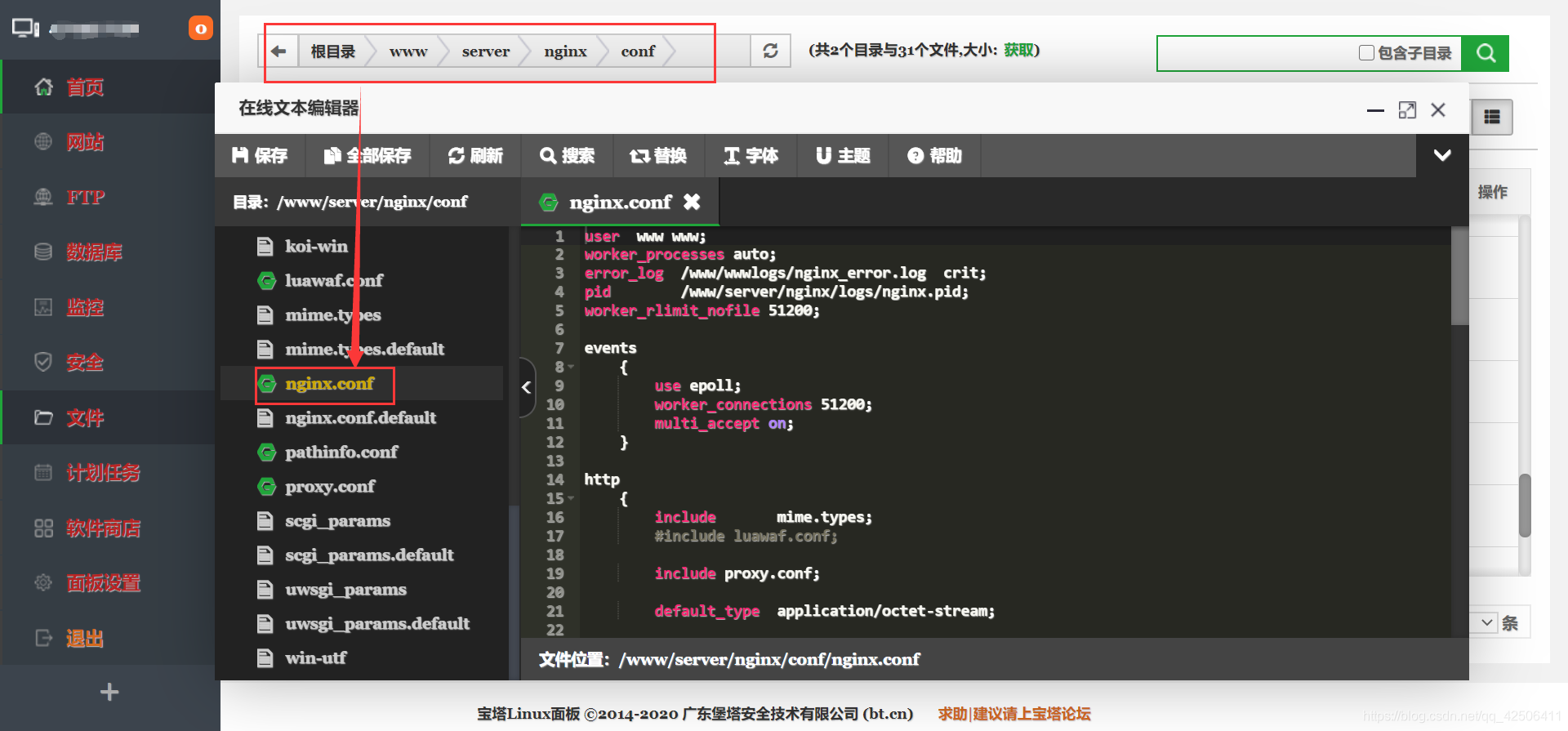
2.网站名配置文件路径(/www/server/panel/vhost/nginx):在这个路径中,我所打的马赛克即为网站名,也是客户端的远程ip地址。在经过大量的测试后,我发现只有对这个网站名配置文件进行修改,才能成功完成反爬虫。因此本次实战中,网站名配置文件便是重点。
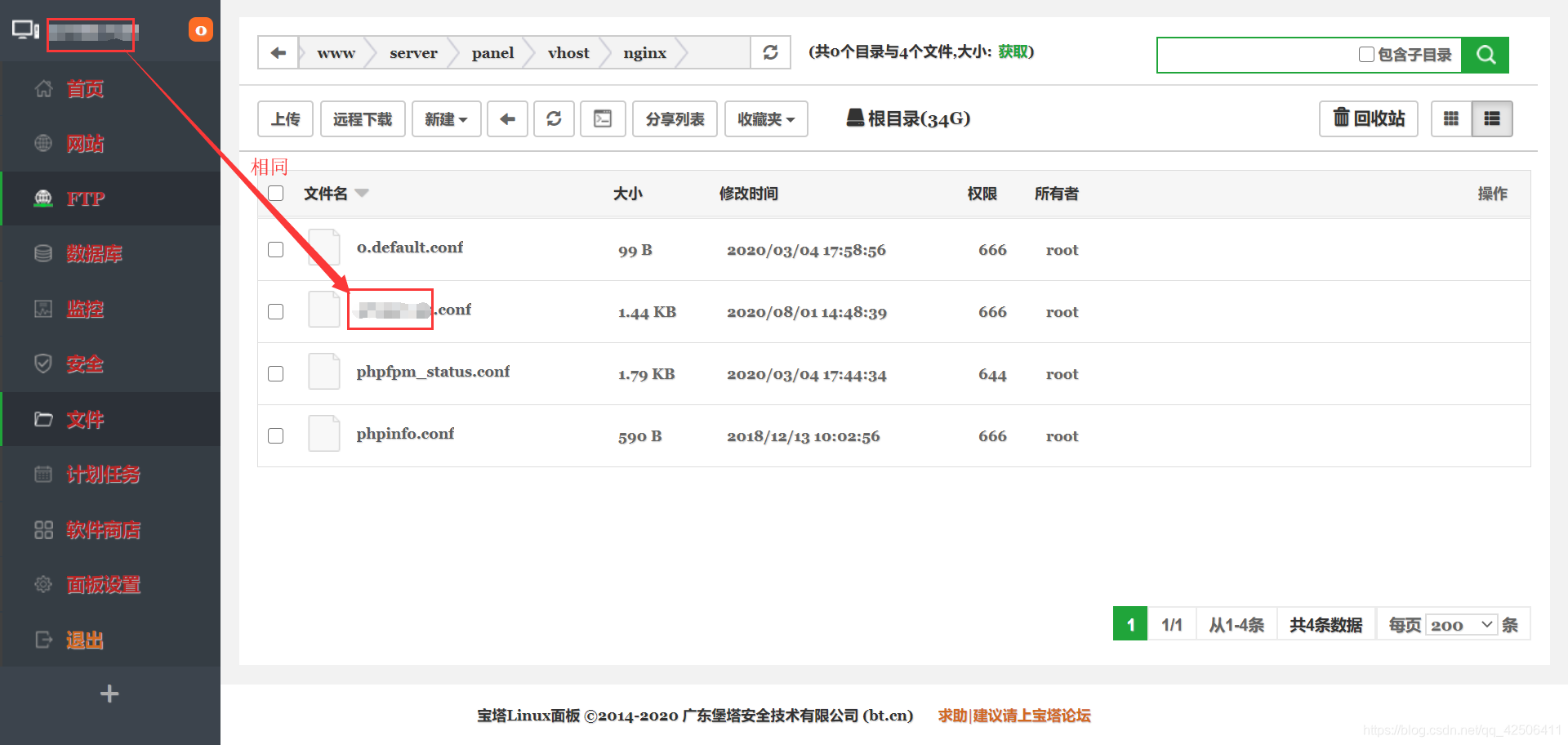
因此,明确了本次实战的重点之后,我们只需要打开网站名配置文件进行代码添加即可。在代码添加之前,我们可以先尝试通过python的requests库进行爬虫测试:
import requests
url = "http://www.hakutaku.club"
response = requests.get(url)
print(response.status_code)
if response.status_code == 200:
print(response.text)
else:
print("反爬虫测试成功!")
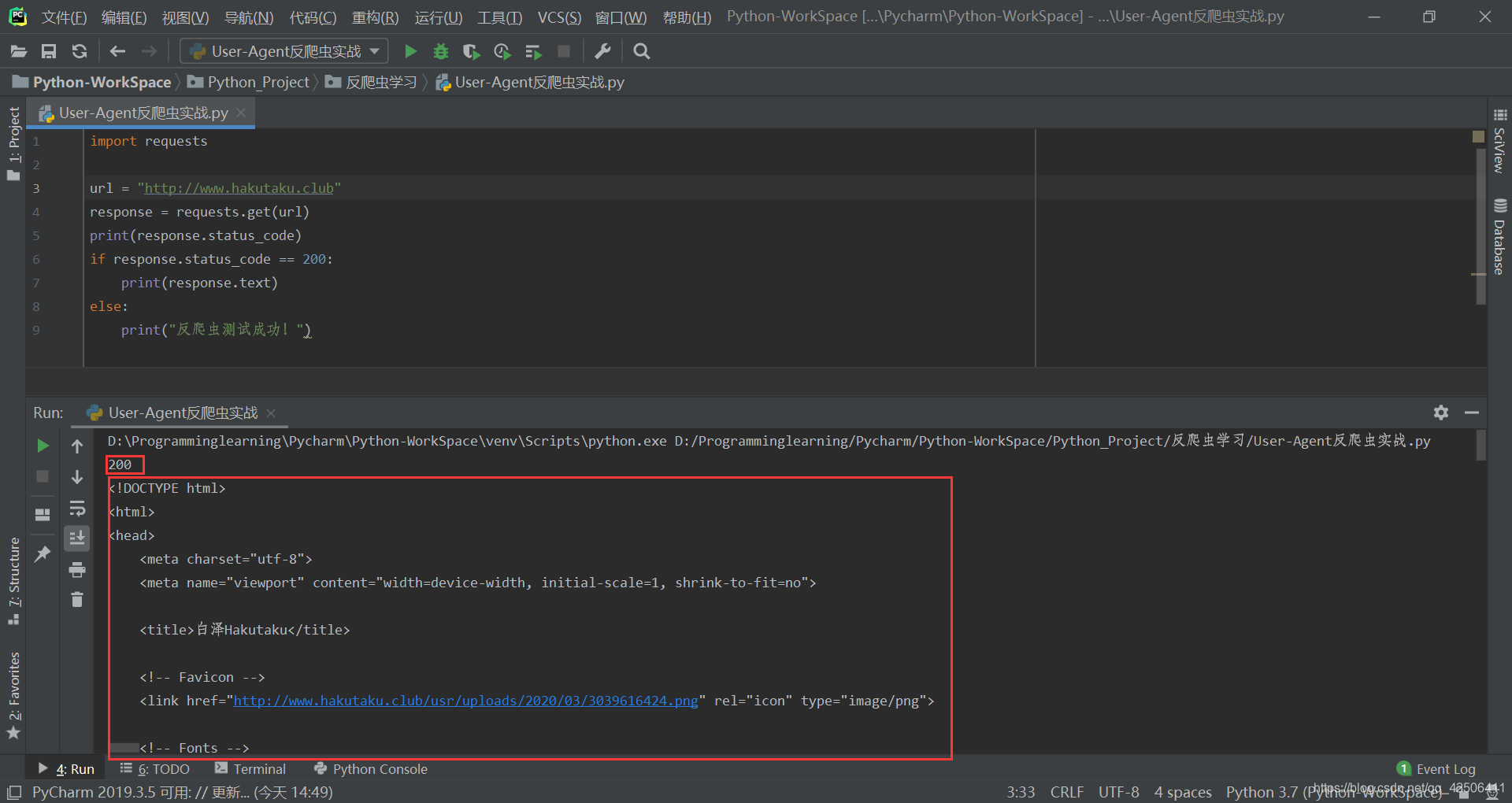
测试可发现,使用Python爬虫访问我的个人博客:http://www.hakutaku.club所返回的状态码是200,并且可以轻而易举的获取到我的个人博客源代码。
User-Agent反爬虫实战
接下来,我们开始正式的反爬虫实战分析。
上面测试分析说过,网站名配置文件是本次测试的重点。因此我们通过宝塔Linux面板进入并找到网站名配置文件,将下列代码复制粘贴进去:
# 禁止python爬虫访问
if ($http_user_agent ~* (python)){
return 403;
}
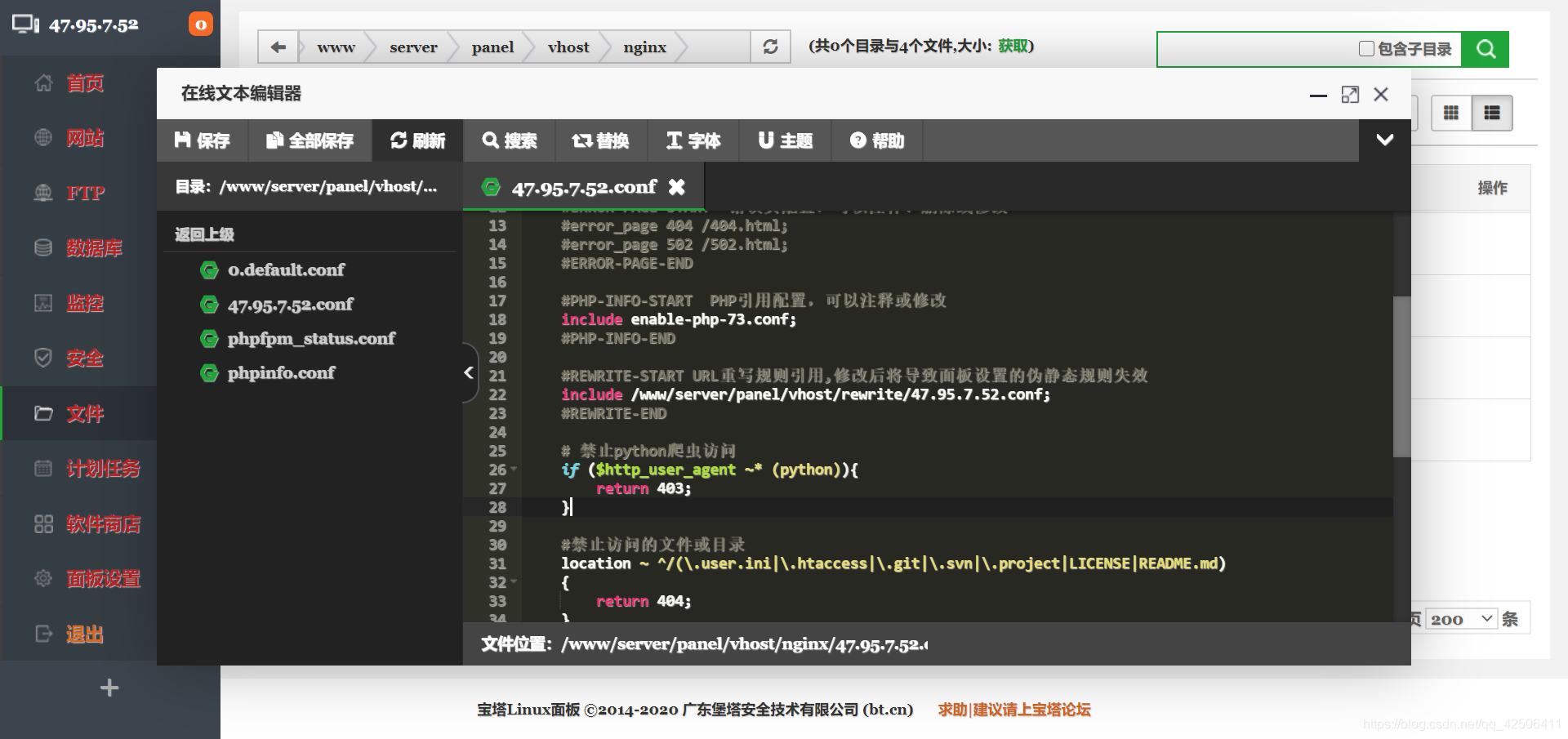
使用Ctrl+S保存,接下来我们再打开Pycharm运行同样的Python代码进行反爬虫测试:

测试成功!我们这次再运行Python代码时获取到的状态码便是403,即User-Agent反爬虫可以有效防范Python爬虫直接爬取我的个人博客!
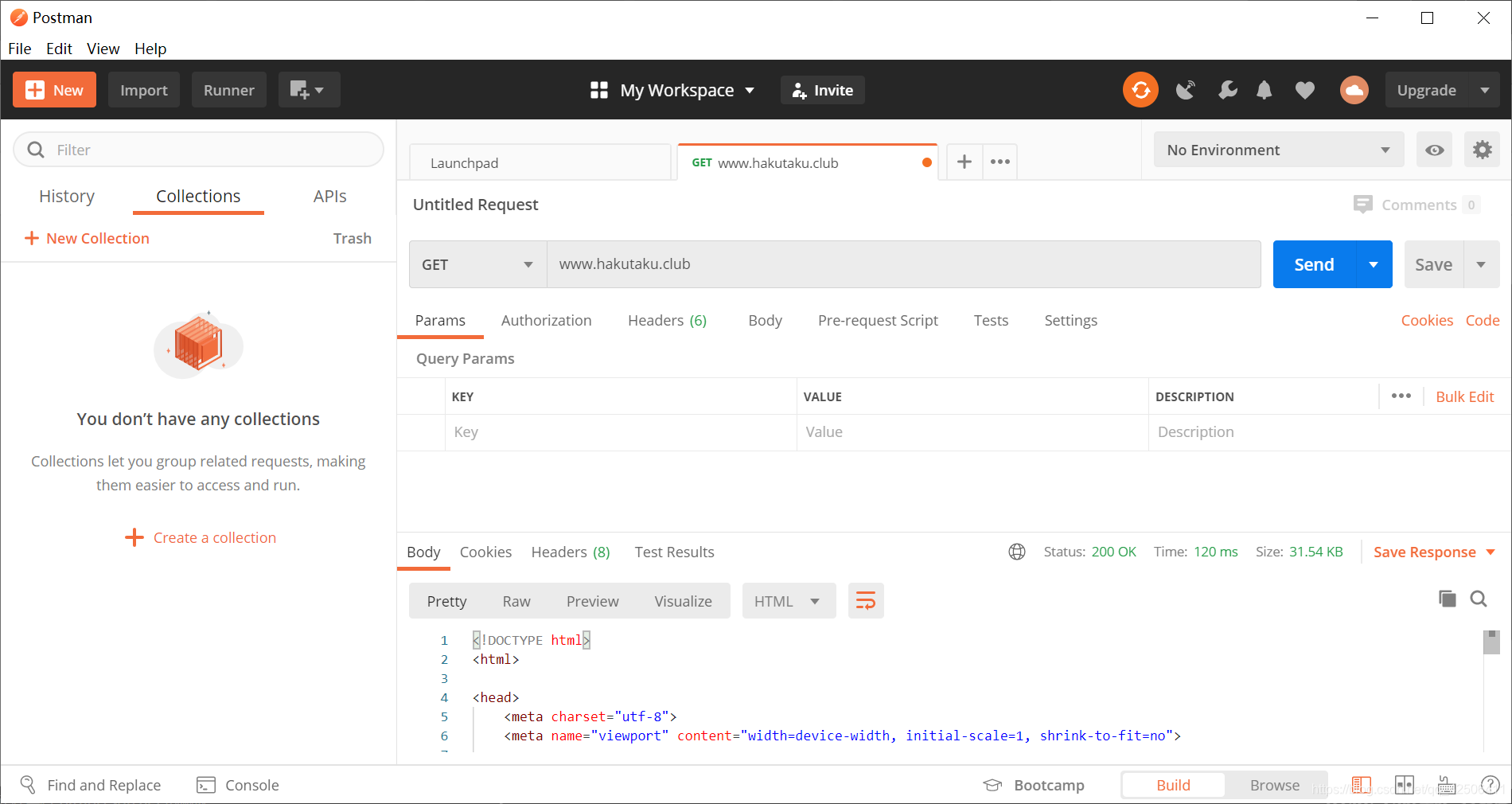
我们打开Postman创建一个request并输入www.hakutaku.club测试,可发现能正常获取到个人博客源代码,证明只是对Python爬虫进行了拦截过滤。
总结
信息校验型反爬虫——User-Agent反爬虫只是我在反爬虫学习中的第一步。在经历了大量的失败尝试后迈出的这第一步尤为重要。虽然User-Agent反爬虫只能防一些刚刚接触爬虫没多久的新手玩家,只要伪造User-Agent请求头就能够轻易的破解。但…这只是第一步而已。
附录:User-Agent收集
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫