机器学习公开课第五讲
这篇笔记对应的是公开课视频的第五个,讲到的内容有生成学习算法(generative learning algorithm)、高斯判别分析法(Gaussian Discriminant Analysis)、朴素贝叶斯(naive Bayes)和拉普拉斯平滑(Laplace Smoothing).






算法实现(python代码):
import xlrd
import numpy as np
import math
# 加载数据,返回的特征集是数组,标签集是列表
def load_data(filename):
workbook = xlrd.open_workbook(filename)
boyinfo = workbook.sheet_by_index(0)
col_num = boyinfo.ncols
row_num = boyinfo.nrows
# 定义特征集和标签集
dataset = []
labelset = []
for i in range(1, row_num):
row = boyinfo.row_values(i)[0:]
dataset.append([row[0], row[1]])
labelset.append(row[2])
return np.array(dataset),np.array(labelset)
# 定义一个 plotData 函数,输入参数是 数据 X 和标志 flag: y,返回作图操作 plt, p1, p2 , 目的是为了画图
def plotData(X, y):
# 找到标签为1和0的索引组成数组赋给pos 和 neg
pos = np.where(y==1)
neg = np.where(y==0)
pos_num = len(pos[0])
neg_num = len(neg[0])
pos_dataset = []
neg_dataset = []
for i in pos[0]:
pos_dataset.append(X[i].tolist())
for i in neg[0]:
neg_dataset.append(X[i].tolist())
return pos_num,neg_num,np.array(pos_dataset),np.array(neg_dataset)
# 归一化数据
def normalization(X):
Xmin = np.min(X, axis=0)
Xmax = np.max(X, axis=0)
Xmu = np.mean(X, axis=0)
X_norm = (X-Xmu)/(Xmax-Xmin)
return X_norm
# 计算fai,miu0,miu1,sigma
def calculate_para(X_norm,y,pos_data,neg_data,pos_num,neg_num):
m = pos_num+neg_num
fai = pos_num/m
print("fai:", fai)
miu1 = np.sum(pos_data, axis=0)/pos_num
miu0 = np.sum(neg_data, axis=0)/neg_num
print("miu1:", miu1)
print("miu0:", miu0)
sum = np.array(np.zeros((2, 2),dtype=float))
X_normmat = np.mat(X_norm)
for i in range(m):
if(y[i]==0):
sum += (X_normmat[i]-miu0).T * (X_normmat[i]-miu0)
else:
sum += (X_normmat[i]-miu1).T * (X_normmat[i]-miu1)
sigma = sum/m
print("sigma:", sigma)
return fai,miu0,miu1,sigma
def norm_distribution(x,y,miu1,miu0,sigma,fai):
n = len(miu1)
miu_mat1 = np.mat(miu1)
miu_mat0 = np.mat(miu0)
sigma_mat = np.mat(sigma)
delta = np.linalg.det(sigma)
px_y0 = 1/(math.pi**(n/2)) * np.exp(-(1/2)*(x-miu_mat0)*sigma_mat.I*(x-miu_mat0).T)/delta**(1/2)
px_y1 = 1/(math.pi**(n/2)) * np.exp(-(1/2)*(x-miu_mat1)*sigma_mat.I*(x-miu_mat1).T)/delta**(1/2)
px = px_y1[0, 0]*fai + px_y0[0, 0]*(1-fai)
py1_x = fai * px_y1[0, 0] / px
return py1_x
if __name__ == '__main__':
dataset,labelset = load_data("data.xls")
m,n = dataset.shape
# 对输入x进行归一化处理
X_norm = normalization(dataset)
pos_num, neg_num, pos_dataset, neg_dataset = plotData(X_norm,labelset)
print("正样本数:", pos_num)
print("负样本数:", neg_num)
fai,miu0,miu1,sigma = calculate_para(X_norm, labelset.tolist(), pos_dataset, neg_dataset, pos_num, neg_num)
py1_x = []
for i in range(50):
py1_x.append(norm_distribution(X_norm[i], labelset.tolist(), miu1, miu0, sigma, fai))
# 验证高斯判别分析法的准确率
for i in range(m):
if(py1_x[i] > 0.5):
py1_x[i] = 1.0
else:
py1_x[i] = 0.0
y = labelset.tolist()
cnt = 0
for i in range(m):
if(y[i]==py1_x[i]):
cnt += 1
print("accurancy rate: {0}".format(cnt/m))
运行代码,可以看到:
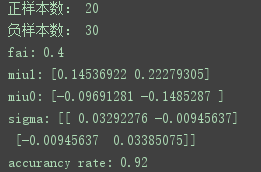
它的分类准确率到达了92%,而前面的logistic回归的模型准确率可以达到94%,两者使用的是同一个数据集;至于为什么逻辑斯蒂回归的准确率更高,我认为是使用的数据集本身可能不是很符合高斯分布,所以在模型准确率上不如logistic回归。





算法实现(python代码):
import numpy as np
import re
# 将文本内容转换为列表形式
def text2list(filename):
rows = open(filename).read()
lists = re.split(r'\W*', rows)
return [list.lower() for list in lists if len(list) > 2]
# 从文件夹中读取50封邮件及其标签,将内容转换为列表形式
def get_trainset():
trainemails = []
trainlabels = []
for i in range(1, 21):
wordlist1 = text2list("email/ham/%d.txt" % i)
trainemails.append(wordlist1)
trainlabels.append(1)
wordlist0 = text2list("email/spam/%d.txt" % i)
trainemails.append(wordlist0)
trainlabels.append(0)
return trainemails,trainlabels
# 构建词向量
def createvocab(trainemails):
vocabulary = set([])
for email in trainemails:
vocabulary = vocabulary | set(email)
return list(vocabulary)
# 将每一个列表转换为一个向量
def list2vector(email,vocabulary):
vector = [0]*len(vocabulary)
for words in email:
if words in vocabulary:
vector[vocabulary.index(words)] += 1
else:
print("words is not in my vocabulary")
return vector
# 计算条件概率和p(y)
def naivebayes(trainemail_array,trainlabels):
num_email = len(trainemail_array)
num_character = len(trainemail_array[0])
print(num_character,num_email)
# 计算P(y=1)
pAbusive = sum(trainlabels)/num_email
print("pAbusive= {0}".format(pAbusive))
# 定义P(xi|y=1)和P(xi|y=0)
p1_vec = np.ones(num_character)
p0_vec = np.ones(num_character)
# 初始化分母
p1Num = num_character
p0Num = num_character
for i in range(num_email):
if(trainlabels[i] == 1):
p1_vec += trainemail_array[i]
p1Num += sum(trainemail_array[i])
else:
p0_vec += trainemail_array[i]
p0Num += sum(trainemail_array[i])
p1_vec = np.log(p1_vec/p1Num)
p0_vec = np.log(p0_vec/p0Num)
return p1_vec,p0_vec,pAbusive
# 分类函数
def classify(myemail,p1_vec,p0_vec,pAbusive):
# 将得到的条件概率和要预测的邮件输入关联起来
p1 = sum(myemail * p1_vec) + np.log(pAbusive)
p0 = sum(myemail * p0_vec) + np.log(1-pAbusive)
if(p1 > p0):
return 1
else:
return 0
if __name__ == "__main__":
trainemails, trainlabels = get_trainset()
myvocab = createvocab(trainemails)
# 将所有邮件有转换到向量形式
trainemail_array = []
for i in range(len(trainlabels)):
trainemail_array.append(list2vector(trainemails[i], myvocab))
p1_vec, p0_vec, pAbusive = naivebayes(trainemail_array, trainlabels)
# 测试
testemails = []
testlabels = []
for i in range(1, 11):
wordlist1 = text2list("email/test/%d.txt" % i)
testemails.append(wordlist1)
if(i<6):
testlabels.append(1)
else:
testlabels.append(0)
testemail_array = []
for i in range(len(testlabels)):
testemail_array.append(list2vector(testemails[i], myvocab))
cnt = 0
for i in range(len(testlabels)):
y = classify(testemail_array[i], p1_vec, p0_vec, pAbusive)
if(y == testlabels[i]):
cnt += 1
print("accurancy rate: {0}".format(cnt/len(testlabels)))
运行代码:可以看到我们对邮件实现了准确分类。