MySQL别名
- 为表取别名:查询数据时,如果表名很长,使用起来不方便,此时,就可以为表取一个别名,用这个别名来代替表的名称
SELECT * FROM 表名 [AS] 别名; - 为字段取别名:在查询数据时,为了使显示的查询结果更加直观,可以为字段取一个别名
SELECT 字段名 [AS] 别名 [,字段名 [AS] 别名,……] FROM 表名;
注意:AS关键字在指定别名的时候可以省略不写
INNER JOIN
内连接(inner join)是使用最多的一种连接类型。在连接的两表中只有满足连接条件的元组,才作为结果输出。
- 一般格式
select[distinct/all]<目标列表达式[别名]清单>
from<关系名1[别名1]>inner join<关系名2[别名2]>
on<连接条件表达式>;
LEFT JOIN
- 左外连接(Left join)属于外连接的一种,另外还有右外连接(Right Join),全外连接(Full Join);
- 左外连接(Left join):除了返回两表中满足条件的元组以外,还返回左侧表中不匹配元组,右侧表中以空值(NULL)替代;
- 格式就是将上面inner join 改为left join即可。
CROSS JOIN
- CROSS JOIN子句从连接的表返回行的笛卡儿乘积。假设使用CROSS JOIN连接两个表。 结果集将包括两个表中的所有行,其中结果集中的每一行都是第一个表中的行与第二个表中的行的组合。 当连接的表之间没有关系时,会使用这种情况。要特别注意的是,如果每个表有1000行,那么结果集中就有1000 x 1000 = 1,000,000行,那么数据量是非常巨大的。
- 如果添加了WHERE子句,如果T1和T2有关系,则CROSS JOIN的工作方式与INNER JOIN子句类似
- 具体例子见链接:MySQL交叉连接(cross join)
自连接
有时,一些特殊的查询需要对同一个关系进行连接查询,成为表的自身连接: 即一张表看成是两张表。
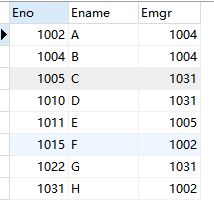
例:要找到某人的间接负责人,则要先找到他的直接负责人,然后通过找他直接负责人的负责人找到某人的间接负责人。
例表emp01:
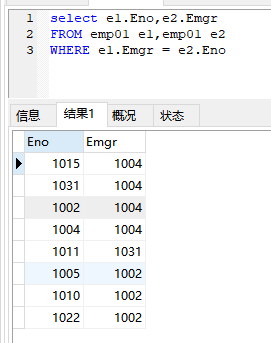
自连接后的结果:
UNION
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
语法格式:
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];
参数:
- expression1, expression2, … expression_n: 要检索的列。
- tables: 要检索的数据表。
- WHERE conditions: 可选, 检索条件。
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
注:UNION语句用于将不同表中相同列中查询的数据展示出来(不包括重复数据),UNION ALL语句包括重复数据。
区别
INNER JOIN产生的结果是两张表的交集,LEFT JOIN产生左表的完全集,右表中若没有匹配则以null值取代。CROSS JOIN将两张表数据进行一个N*M组合,即笛卡尔积。自连接是对于自身的操作,将自己当成两张表操作来提取需要的信息。UNION操作符是用于连接两个以上的SELECT语句,它和INNER JOIN的区别是一个是连接两张表,另一个是连接两个SELECT语句。
作业
项目五:组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person
| 列名 | 类型 |
|---|---|
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
PersonId 是上表主键
表2: Address
| 列名 | 类型 |
|---|---|
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State。
作业代码:
-- 项目五(组合两张表)
-- 创建表Person
CREATE TABLE Person(
PersonId INT NOT NULL,
FirstName VARCHAR(30) NOT NULL,
LastName VARCHAR(30) NOT NULL
);
ALTER TABLE Person MODIFY PersonId INT PRIMARY KEY;
-- 插入数据
INSERT INTO Person VALUES(1,"Alfonso","Carlos");
INSERT INTO Person VALUES(2,"Antonio","Julio");
INSERT INTO Person VALUES(3,"Belen","Sonia");
-- 创建表Address
CREATE TABLE Address(
AddressId INT PRIMARY KEY,
PersonId INT,
City VARCHAR(20),
State VARCHAR(20)
);
-- 插入数据
INSERT INTO Address VALUES(1,1,"Hangzhou","China");
INSERT INTO Address(AddressId,PersonId) VALUES(2,2);
INSERT INTO Address VALUES(3,3,"NewYork","American");
-- 作业解答
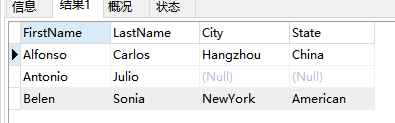
SELECT p.FirstName,p.LastName,a.City,a.State
FROM Person p LEFT JOIN Address a
ON p.PersonId = a.PersonId
运行结果:
项目六:删除重复的邮箱(难度:简单)
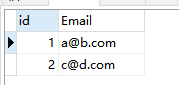
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Email表应返回以下几行:
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
作业代码:
-- 项目六:删除重复的邮箱
-- 创建表email
CREATE TABLE email(
id INT PRIMARY KEY,
Email VARCHAR(50) NOT NULL
);
-- 插入数据
INSERT INTO email VALUES(1,"[email protected]");
INSERT INTO email VALUES(2,"[email protected]");
INSERT INTO email VALUES(3,"[email protected]");
-- 自连接
DELETE e1
FROM email e1,email e2
WHERE e1.Email = e2.Email
AND e1.id > e2.id;
-- 查询结果
select * from email;
运行结果: