引入
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器进行url请求发送则会加载出对应的动态加载的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1,案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链接进入对应页面时,会发现当前页面展示的新闻数据是被动态加载出来的。需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的数据。
2,selenium在scrapy中使用的原理分析:
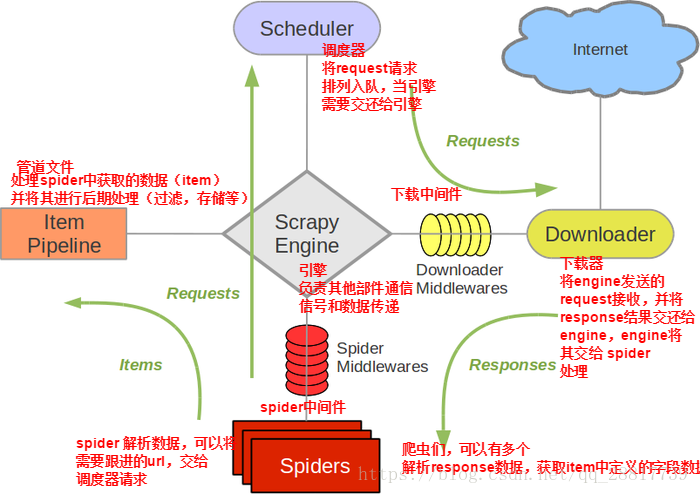
当引擎将国内板块url对应的请求提交给下载器后,下载进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接收到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获得动态数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,且对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3,selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件中的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启中间件
4,代码展示: