前言
继续
实例--------->爬取简书
用普通selenium方式抓取数据
首先打开网站
发现需要点击展开更多才能获取想要的信息,只能通过selelnium来实现
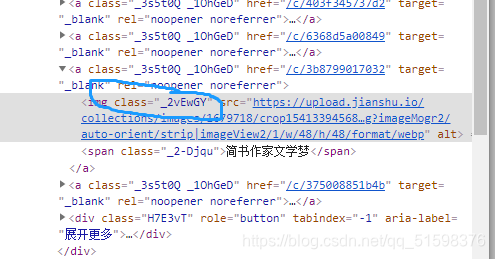
可以看到,目标元素的class的值是经过压缩加密的,这是一种反爬措施。每一次重新更新网站结构时,这个class的名称都会发生改变
所以可以通过结构来找到这个元素,这个网站的元素经常变化,需要有可靠定位方法这样爬虫会存活久一点
代码如下
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from scrapy.http.response.html import HtmlResponse
class JianshuDownloaderMiddleware:
def __init__(self):
self.driver = webdriver.Chrome()
def process_request(self, request, spider):
# 然后用selenium去请求
self.driver.get(request.url)
next_btn_xpath = "//div[@role='main']/div[position()=1]/section[last()]/div[position()=1]/div"
WebDriverWait(self.driver, 5).until(
EC.element_to_be_clickable((By.XPATH, next_btn_xpath))
)
while True:
try:
next_btn = self.driver.find_element_by_xpath(next_btn_xpath)
self.driver.execute_script("arguments[0].click();", next_btn)
except Exception as e:
break
# 把selenium获得的网页数据,创建一个Response对象返回给spider
response = HtmlResponse(request.url,body=self.driver.page_source,request=request,encoding='utf-8')
return response
有些东西不会用没事,目前能看懂就可以
主要要知道这里在中间件构造了一个类,包含selenium方法,返回response给spider
对一些难的地方还是比较抗拒,但是也有挑战性的刺激感
接着还要在settings.py中打开中间件
DOWNLOADER_MIDDLEWARES = {
'jianshu.middlewares.JianshuDownloaderMiddleware': 543,
}
总结
1.这次scrapy 集成selenium的案例难点在元素定位,网站的反爬技术使得定位比较困难,出错不要紧,重点是能找到并解决出错的原因
这里常见的timeout错误就是未找到元素出现的
2.遇到直接断出且没有明显出错提示时的情况 时,原因难以判断,这种情况比较打击信心。为了帮助自己调试,需要写代码时注意用try except Exception as e,另外尝试点击小虫子调试
自动化爬取网页过程中可能就卡在某一个网页上面,这种情况只要用调试的方法找到错误,有可能就是因为某个地方元素定位失败,陷入死循环
3.scrapy框架优越性在这里已经有所体现,写好中间件以后,中间件自动爬取并返回response,便于集中精力在spider里编写解析、提取代码,这样分工明确,令人愉快
4.后续的存储任务可以通过,item,pipeline来实现有关这个自己应当主动练习,不练则不会
后续及下一步
进一步编写代码试图打印解析内容失败,控制台没有内容,存储没有尝试
强行学习下去可能效率不会高,scrapy的selenium先到这里
初步想法是,下一步学习论文网站项目构建的同时利用scrapy为微信公众号搜集素材,图片音乐,熟悉框架文件下载