因为要去抓取部分经过JavaScript渲染的网页数据,所以使用scrapy中的Request返回的是没有经过渲染的网页代码,
因此我们就要运用Scrapy中的 splash 中的 SplashRequest 来进行操作。
首先我们要使用安装scrapy-splash:
1、利用pip 安装 scrapy-splash
pip install scrapy-splash
2、安装docker
安装docker比较繁琐,首先要去官网下载docker工具 由于又是Windows7版本 所以下载的是DockerToolbox, 然后手动安装即可。
然后安装过程中,会出现如下情况:(该图是网上找的)
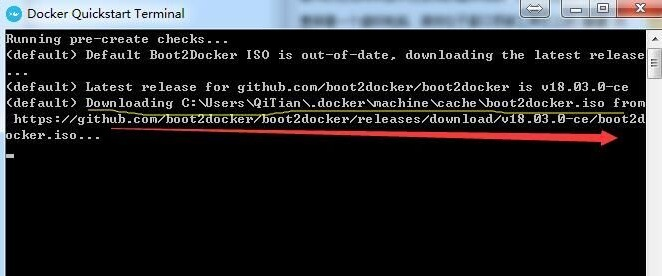
这种时候就要去GitHub里面下载boot2docker-18.03.0-ce文件并放到黄色线条路径处(每个人的路径可能不同),
红色箭头是下载地址 https://github.com/boot2docker/boot2docker/releases/tag/v18.03.0-ce ,
然后将下载到的文件放到指定地址后 等待运行(时间较长)
安装好之后 运行 Docker Quickstart Terminal,
然后输入 docker pull scrapinghub/splash
然后在输入 docker run -p 8050:8050 scrapinghub/splash
这样便开启了 docker 。
然后就可以开始运用 python中的 scrapy-splash 中的 SplashRequest
3、设定python中的 setting文件
SPLASH_URL = 'http://192.168.99.100:8050' #(很重要写错了会出目标电脑积极拒绝)
添加Splash中间件,指定优先级:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
设置Splash自己的去重过滤器 :
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
缓存后台存储介质:
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # 以上两条必加
4、运用SplashRequest:
这个运用方面 有一个需要特别注意 就是:
yield SplashRequest(url=news_url, callback=self.down_load,args={"wait": 3})
上面是使用 splashrequest的一个例子,其中一定要添加args={"wait": 3} 这一个标识延迟多久以后再将网页信息传送过来。