1. 前言
当Hbase集群中某个RegionServer挂掉之后,Hbase是如何把这台server上的regions迁移到其它的RegionServer上的呢?要弄清楚这个问题,首先要了解Hbase中Region的寻址机制,在此基础上来理解regions在RegionServer之间迁移的原理。
2. Region 寻址机制
在Hbase中,读写操作都在 RegionServer 上发生,每个 RegionSever 为一定数量的 Region 服务,那么Client 要对某一行数据做读写的时候如何能知道具体要去访问哪个 RegionServer 呢?
2.1 旧的Region寻址方式
在 HBase-0.96 版本以前,HBase 有两个特殊的表,分别是-ROOT-表和.META.表,其中-ROOT-的位置存储在 ZooKeeper 中,-ROOT-本身存储了.META. 表的 RegionInfo 信息,并且-ROOT-不会分裂,只有一个 Region。而.META.表可以被切分成多个Region。读取的流程如下图所示:
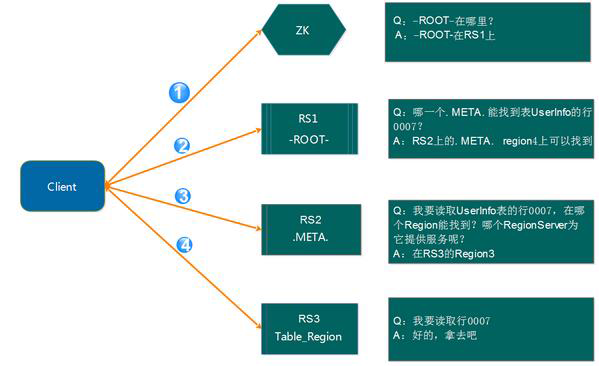
详细步骤:
第 1 步:Client 请求 ZooKeeper 获得
-ROOT-所在的 RegionServer 地址;
第 2 步:Client 请求-ROOT-所在的 RS 地址,获取.META.表的地址,Client 会将-ROOT-的相关 信息 cache 下来,以便下一次快速访问;
第 3 步:Client 请求.META.表的 RegionServer 地址,获取访问数据所在 RegionServer 的地址, Client 会将.META.的相关信息 cache 下来,以便下一次快速访问;
第 4 步:Client 请求访问数据所在 RegionServer 的地址,获取对应的数据。
从上面的路径我们可以看出,用户需要 3 次请求才能直到用户 Table 真正的位置,这在一定 程序带来了性能的下降。在0.96之前使用 3 层设计的主要原因是考虑到元数据可能需要很 大。但是真正集群运行,元数据的大小其实很容易计算出来。在 BigTable 的论文中,每行 METADATA 数据存储大小为 1KB 左右,如果按照一个 Region 为 128M 的计算,3 层设计可以支持的 Region 个数为 2^34 个,采用 2 层设计可以支持 2^17(131072)。那么 2 层设计的情 况下一个集群可以存储 4P 的数据。这仅仅是一个 Region 只有 128M 的情况下。如果是 10G 呢? 因此,通过计算,其实 2 层设计就可以满足集群的需求。因此在 0.96 版本以后就去掉 了-ROOT-表了。
2.2 新的Region寻址方式
如上面的计算,2 层结构其实完全能满足业务的需求,因此 0.96 版本以后将-ROOT-表去掉了。 如下图所示:
寻址变成了3步:
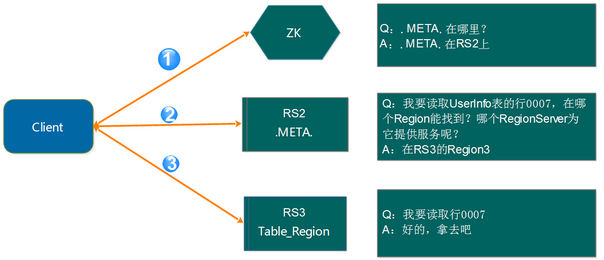
第 1 步:Client 请求 ZooKeeper 获取
.META.所在的 RegionServer 的地址;
第 2 步:Client 请求.META.所在的 RegionServer 获取访问数据所在的 RegionServer 地址,Client 会将.META.的相关信息 cache 下来,以便下一次快速访问;
第 3 步:Client 请求数据所在的 RegionServer,获取所需要的数据。
2.3 去掉-ROOT-的原因
-
其一:提高性能
-
其二:2 层结构已经足以满足集群的需求
这里还有一个问题需要说明,那就是 Client 会缓存.META.的数据,用来加快访问,既然有缓 存,那它什么时候更新?如果.META.更新了,比如 Region1 不在 RerverServer2 上了,被转移 到了 RerverServer3 上。Client 的缓存没有更新会有什么情况?

其实,Client 的元数据缓存不更新,当.META.的数据发生更新。如上面的例子,由于 Region1 的位置发生了变化,Client 再次根据缓存去访问的时候,会出现错误,当出现异常达到重试次数后就会去.META.所在的 RegionServer 获取最新的数据,如果.META.所在的 RegionServer 也变了,Client 就会去 ZooKeeper 上获取.META.所在的 RegionServer 的最新地址。
3. Regions迁移原理
HBase基于Hadoop,RegionServer中的数据保存在HDFS上,默认情况下HDFS保存3份,会尽量放在3台机器上。所以当一台机器挂掉的情况下,HDFS层面会检查到这部分数据的复制份数不够,再复制一份出来到其它机器上去的。
3.1 RegionServer 宕机时重新分配Region
RegionServer上的HFile和WAL都存储在HDFS上,当RegionServer 宕机的时候,数据是不会丢失的,丢失的只是Memstore中尚没有写入HFile的部分。RegionServer宕机后,该RegionServer所负责的Region就会变成不可用,HMaster就会根据集群的负载状况,将这些Region分配给其他RegionServer。
接手的RegionServer从zookeeper上的-ROOT-表(0.96之前版本Hbase)和.META.表上可以找到充分的元数据信息,那么RegionServer只需要根据这些信息组织起内存结构,并获取WAL文件进行重放,就可以最大程度的恢复到原来那台RegionServer宕机前的状态。
当然由于RegionServer通常和DataNode在一台服务器上,在写入时,也会调用本地的DFSClient写入,数据块会在本机有一个副本,在另外的机架上有一个副本,还有另外一个随机分配的副本,这样在读写时可以保证Data Locality。如果RegionServer接手了一个Region,那么大多数数据块不在本地的NameNode上,读写性能会有下降,但会在后续的Compact过程中逐渐将文件写入本地的DataNode,从而恢复Data Locality。当然由于HDFS少了一个DataNode,改DataNode上的数据块都少了一个副本,HDFS也会在其他的DataNode上重新建立这些副本,以保证可靠性。
4. 总结
通过Hbase的寻址机制,可以知道Hbase找到RegionServer是向zookeeper请求-ROOT-表(0.96之前版本Hbase),然后找到-META-表,然后在-META-表里找到RegionServer信息。如果RegionServer挂了,它把这个元数据,转移到其它活着的RegionServer上,然后把WAL日志分到其它RegionServer上去重新加载。记住这里是元数据,数据本身是在hdfs上的,所以数据本身不会挂。元数据可以理解成对文件的索引,是放在内存中的。