RegionServer Splitting 实现
HBase 中的写请求由 Region Server 处理,这些数据首先存储在 memstore (RegionServer 里的一个存储系统)里。一旦 memstore 满了后,它的内容会被写到磁盘,在磁盘上以文件的形式存储(HFile),这个事件被称为一个 memstore flush。随着这些文件的增加,RegionServer 会将它们compact为一些数量更少,但是内容更大的文件。在每次 flush 或 compaction 完成后,region里存储的数据量会变化。RegionServer 会参考 region split policy,并判断:
- region 是否是增长到了足够大的规模
- 此region由于某些特定policy的原因,需要进行split
如果符合split policy,则一个region split request 会被放入到请求队列中。
从逻辑上来说,region split的过程较为简单。我们会在region的keyspace中找到一个合适的点,将region分为两半,然后将此region的数据以那个点为依据,分配到两个新region中。然而,整个过程其实并不简单。当一个split发生时,新创建的 daughter regions不会立即将所有数据重写到新文件里。而是创建类似于 symbolic link 的小文件,名为 Reference files。References files 会根据 parent store file 的 split point,分别指向这个文件的两部分。第一部分为“bottom”,也就是从文件头,到分离点。第二部分为“top”,也就是分离点到文件末尾。Reference file使用起来基本就像一个正常的数据文件,但是仅仅会考虑其中一半的记录。一个region可以被split 的必要条件是:没有references 指向父region 的 immutable 数据文件。那些 reference files 会被compactions的机制逐渐地被清理掉,这样region就停止指向它的父文件,也就可以被进一步的split。
尽管splitting region是一个本地决策,由RegionServer 决定,但是split的过程必须要与其他很多因素协作完成。RegionServer在split前后,均会通知Master更新.META. 表,这样客户端可以找到新的子regions。在HDFS上的数据文件以及目录结构也会被rearranged。Splitting是一个多任务的过程。为了实现在遇到错误时回滚操作,RegionServer在内存里存了一个记录 execution state 的日志。RegionServer执行split 时的步骤如下图所示。每个步骤标有它的步骤号。RegionServers 或 Master 的操作标为红色,客户端的操作标为绿色:
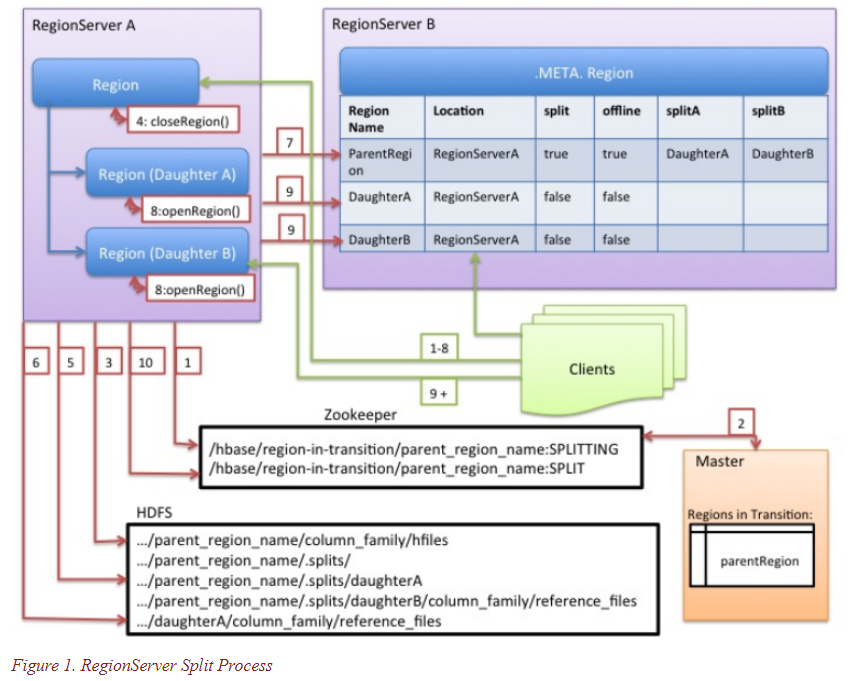
- RegionServer 本地决定做 split region,并开始着手准备。THE SPLIT TRANSACTION IS STARTED。首先第一步,RegionServer 获取一个 shared read lock on table,以防表的 schema 在splitting 过程中被修改。然后它创建一个 znode,在zookeeper 下的 /hbase/region-in-transition/region-name,并设置此znode的状态为SPLITTING
- Master感知到此znode,因为它有一个watcher监控region-in-transition的父znode
- RegionServer 创建一个子目录,名为.splits,在HDFS的父region目录下
- RegionServer close 父region,并在它本地的数据结构里将此region标注为 offline。THE SPLITTING REGION IS NOW OFFLINE。在此时,客户端的请求到父region时,会抛出 NotServingRegionException。客户端会以一些回退方法进行重试。正在closing的region会被flushed
- RegionServer在.splits 文件夹下,为两个子regions A 和 B 创建region文件夹,并且创建必要的数据结构。然后RegionServer开始对存储文件做分割,也就是说,它为父region的每个存储文件创建两个 Reference 文件。这些 reference 文件将指向父region的存储文件
- RegionServer在HDFS创建真正的子region文件夹,并且将references 文件移动到对应的子region目录
- RegionServer 发送一个 Put 请求到 .META. 表,将父region在.META.表里设置为offline,并且增加子region的信息。在这时候,.META. 表中不会有单独的子region的条目。客户端在 scan .META. 表时会看到父region在split,但是不会获取到子region的信息,直到它们在.META. 表中出现。同时,如果这个到 .META. 表的 Put 请求成功,则父region会实际上开始做split。如果在这个 RPC 成功前,RegionServer fail 掉了,则Master和下一个open这个父region的 RegionServer 会清理掉region split 的dirty state(脏状态)。在.META. 更新后,region split的信息会被Master做前滚(rolled-forward)
- RegionServer 同时 open 子region A 和 B
- RegionServer 将子Region A 和 B ,以及它们 host 的region信息一起添加到 .META. 表。THE SPLIT REGIONS(DAUGHTERS WITH REFERENCES TO PARENT)ARE NOW ONLINE。在此之后,客户端可以看到这些新region,并且向它们发送请求。客户端会缓存.META.条目在本地,但是当它们向RegionServer或.META.表发送请求时,他们的缓存会失效,并且需要从.META.表里获取新Region的信息
- RegionServer 更新ZooKeeper 里的znode /hbase/region-in-transition/region-name 的状态到 SPLIT,这样master可以感知到此。如有必要,balancer 也可以放心的将子region重新分配到其他RegionServer上。THE SPLIT TRANSACTION IS NOW FINISHED
- 在split过后,.META. 以及 HDFS会仍然保留指向父region的references。在子region做compactions时,会重写数据文件,这些references文件会被清除掉。Master上的垃圾回收任务会定期检查子regions是否仍然指向父region的文件。如果没有,则父region会被清除掉。
References:
http://hbase.apache.org/book.html#upgrade2.0.regions.on.master