一、神经元的拟合原理
一个神经元由以下几个关键知识点组成:激活函数;损失函数;梯度下降。
单个神经元网络模型:
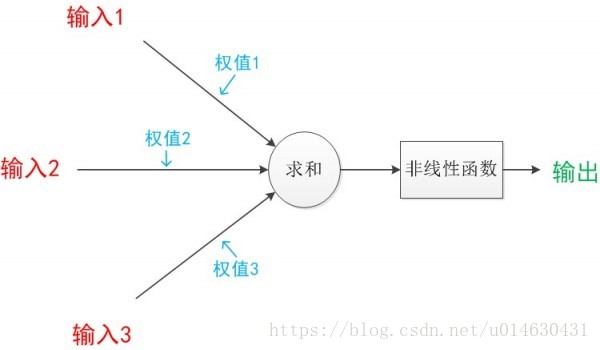
其计算公式: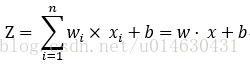
模型每次的学习都是为了调整w和b,从而得到一个合适的值,最终由这个值配合运算公式所形成的逻辑就是神经网络的模型。我们把w和b赋予合适的值时,再配合合适的激活函数,就会发现它可以产生很好的拟合效果。
1、正向传播:数据从输入到输出的流向传递过程为正向传播。它是在一个假设由合适的w和b的基础上,才可以实现对现实环境的正确拟合。但是在实际过程中,我们无法得知w和b的值具体是多少才算是正常的。于是加入了一个训练过程,通过反向误差传递的方法让模型自动来修正,最终产生一个合适的权重。
2、反向传播:反向传播的意义–告诉模型我们需要将w和b调整到多少。在刚开始没有得到合适的权重时,正向传播生成的结果与实际的标签是有误差的,反向传播就是要把这个误差传递给权重,让权重做适当的调整来达到一个合适的输出。BP算法又称“误差反向传播算法”。我们最终的目的,是要让正向传播的输出结果与标签间的误差最小化,这就是反向传播的核心思想。
为了让损失值(将输出值与标签直接相减,或是做平方差等运算)变得最小,我们运用数学知识,选择一个损失值的表达式让这个表达式有最小值,接着通过求导的方式,找到最小值时刻的函数切线斜率(也就是梯度),从而让w和b的值沿着这个梯度来调整。
至于每次调整多少,我们引入一个叫做“学习率”的参数来空值,这样通过不断的迭代,使误差逐步接近最小值,最终达到我们的目标。
二、激活函数
激活函数的主要作用就是用来加入非线性因素的,以解决线性模型表达能力不足的缺陷,在整个神经网络里起到至关重要的作用。
因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的。
在神经网络里常用的激活函数有Sigmoid、Tanh和relu等。
三、softmax算法
softmax基本上可以算是分类任务的标配。
现实生活中需要对某一问题进行多种分类,这时就需要使用soft max算法。如果判断输入属于某一个类的概率大于属于其他类的概率,那么这个类对应的值就逼近于1,其他类的值就逼近于0。该算法的主要应用就是多分类,而且时互斥的,即只能属于其中一个类。与sigmoid类的激活函数不同的是,一般的激活函数只能分两类,所以可以理解成soft max是Sigmoid类的激活函数的扩展,其算法式为:soft max = exp(logits)/reduce_sum(exp(logits), dim)
四、损失函数
损失函数用于描述模型预测值与真实值的差距大小。一般有两种比较常见的算法–均值平方差(MSE)和交叉熵。
五、梯度下降
梯度下降是一个最优化算法,通常也称为最速下降法,常用于机器学习和人工智能中递归性地逼近最小偏差模型,梯度下降地方向也就是用负梯度方向为搜索方向,沿着梯度下降地方向求极小值。
在训练过程中,每次的正向传播后都会得到输出值与真实值的损失值,这个损失值越小,代表模型越好,于是梯度下降的算法就用在这里,帮助寻找最小的那个损失值,从而可以反推出对应的学习参数w和b,达到优化模型的效果。
常用的梯度下降方法可以分为:批量梯度下降、随机梯度下降和小批量梯度下降。
1、退化学习率:在训练的速度与精度之间找到平衡
六、初始化学习参数
在定义学习参数时可以通过get_variable和Variable两个方式,对于一个网络模型,参数不同的初始化情况,对网络的影响会很大,所以在Tensor Flow提供了很多具有不同特性的初始化函数。
七、单个神经元的扩展-Maxout网络
Maxout网络可以理解为单个神经元的扩展,主要是扩展单个神经元里面的激活函数。
一个神经元的作用,类似人类的神经细胞,不同的神经元会因为输入的不同而产生不同的输出,即不同的细胞关心的信号不同。依赖于这个原理,现在的做法就是相当于同时使用多个神经元放在一起,哪个有效果就用哪个。所以这样的网络会有更好的效果。
Maxout是将激活函数变成一个网络选择器,原理就是将多个神经元并列地放在一起,从它们地输出结果中找到最大地那个,代表对特征响应最敏感,然后取这个神经元的结果参与后面的运算。
Maxout的拟合功能很强大,但是也会有节点过多、参数过多、训练过慢的缺点。
阅读笔记《深度学习之Tensor Flow入门、原理与进阶实战》–李金洪