文章目录
神经元
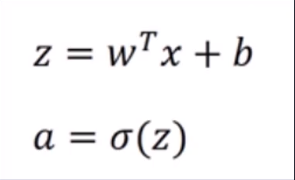
简单来说,给出权重 w 1 w_1 w1, w 2 w_2 w2, 偏差 b b b等参数,再输入数据 x 1 x_1 x1, x 2 x_2 x2等,经过非线性变化得到 z,再经过变化 σ 得到 a,最后计算损失函数 L(a, y)
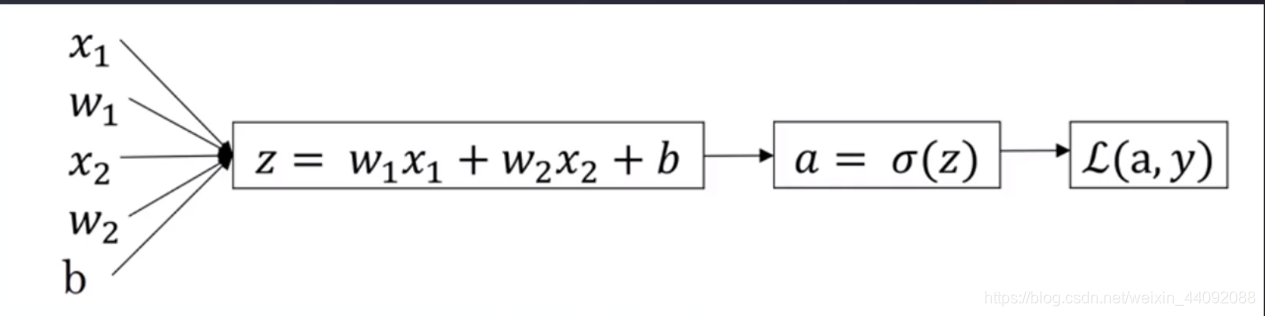
其中 σ 变化常见的有如下三种:
Sigmoid
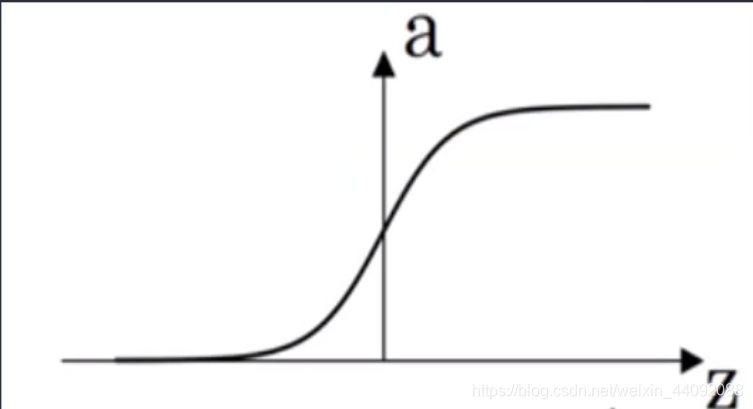
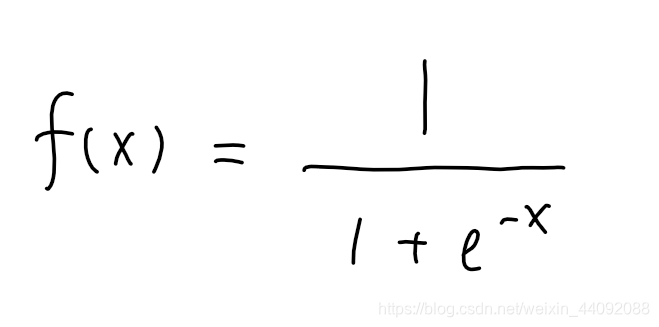
f(x) 值域为 (0, 1)
Tanh
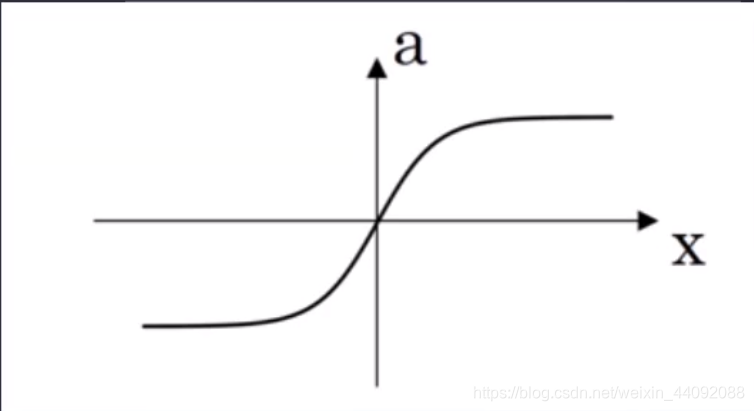
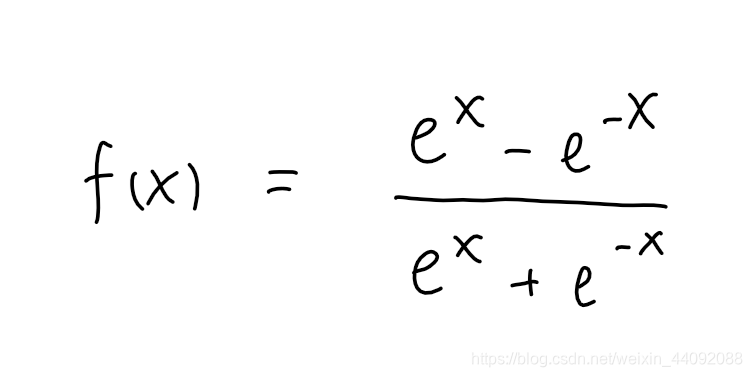
值域为 (-1, 1),和 Sigmoid 相比,多了负数部分。
Relu
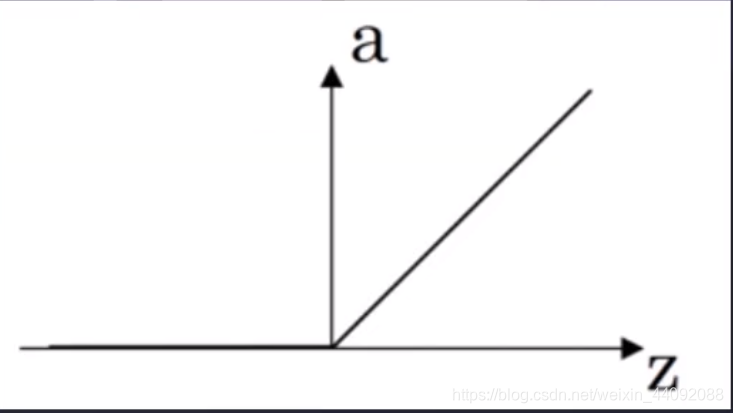
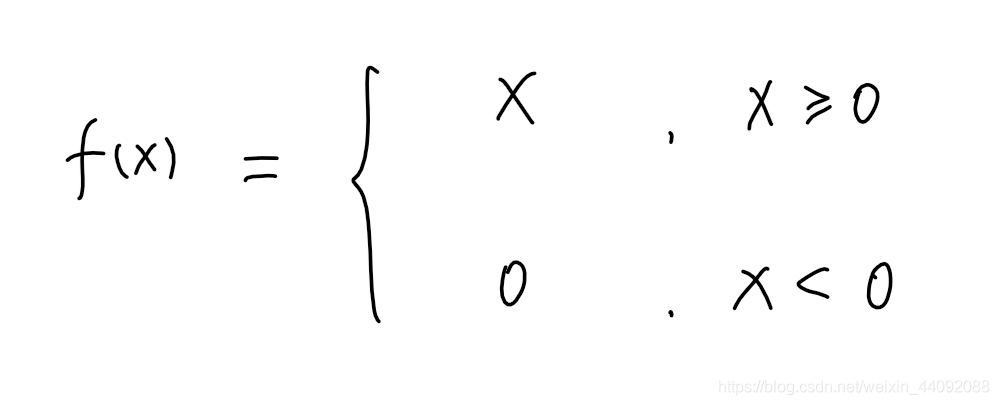
值域为 [0, +∞)
损失函数
loss 函数,我们想要的就是这个 loss 越小越好。
L1
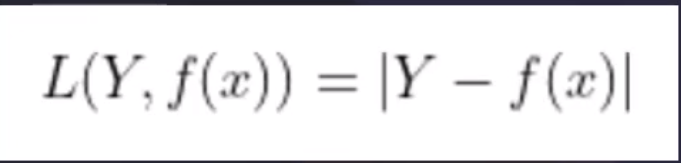
L2
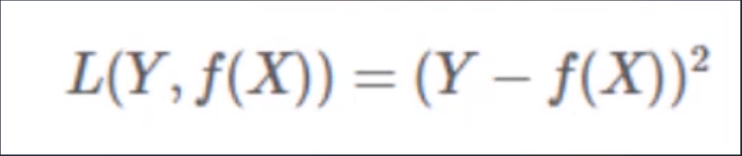
交叉熵
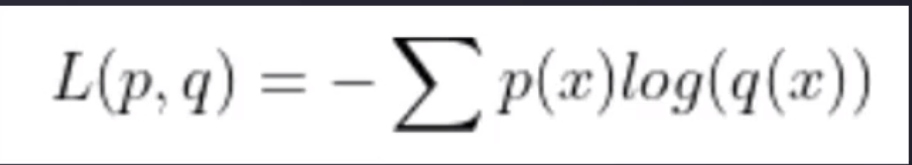
梯度下降
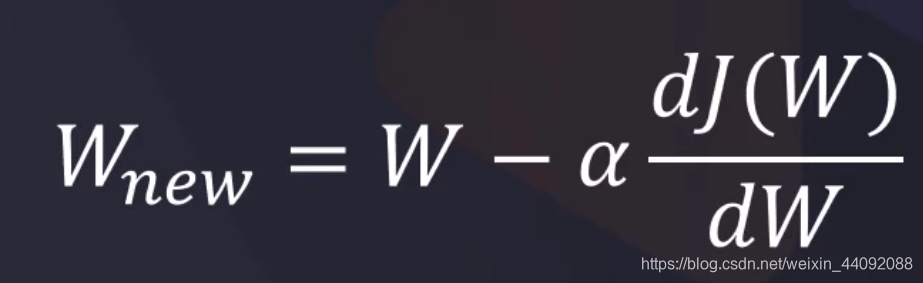
是损失函数 L 对 W 的导数,因为我们希望 Loss 越小越好,所以希望这个导数是负数,那么这时用原来的 W 减去它会使得 W 变化,说明我们更加重视它,并希望一直下去,别忘了 W 是权重,那么计算加权平均时会更有效果。(解释为什么梯度下降中那个别扭的负号)
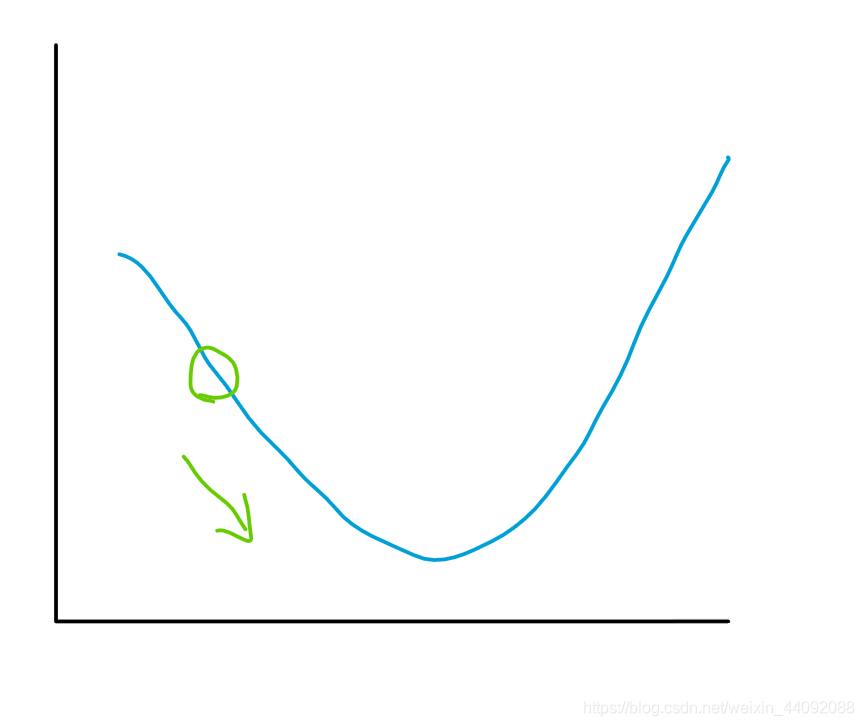
简单地说,就照着梯度的方向前进,拿函数图像说明会更直观,现在以二维函数图像为例子:
朝着凹下去的方向走就好啦
反向传播
经过多次大量的计算得到一个近似的全局最优解。
卷积神经网络

卷积层:边缘检测
输入数据
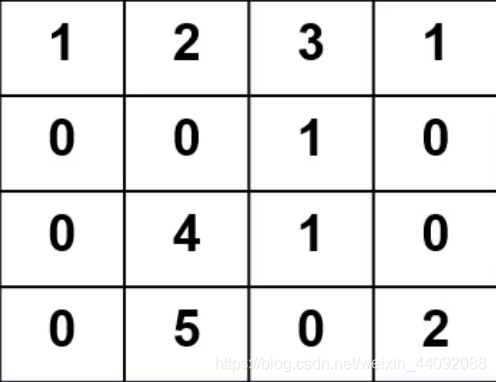
卷积算子
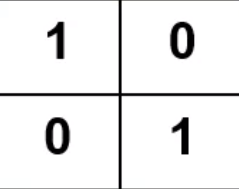
卷积算子是通过计算来不断调整的,
其中每一个值相当于是一个神经元,数值就是权重 W
卷积运算
卷积算子就是一个小的矩阵,把算子放到输入数据上,将算子每个数值当作输入数据相同位置上数值的权值求加权平均,
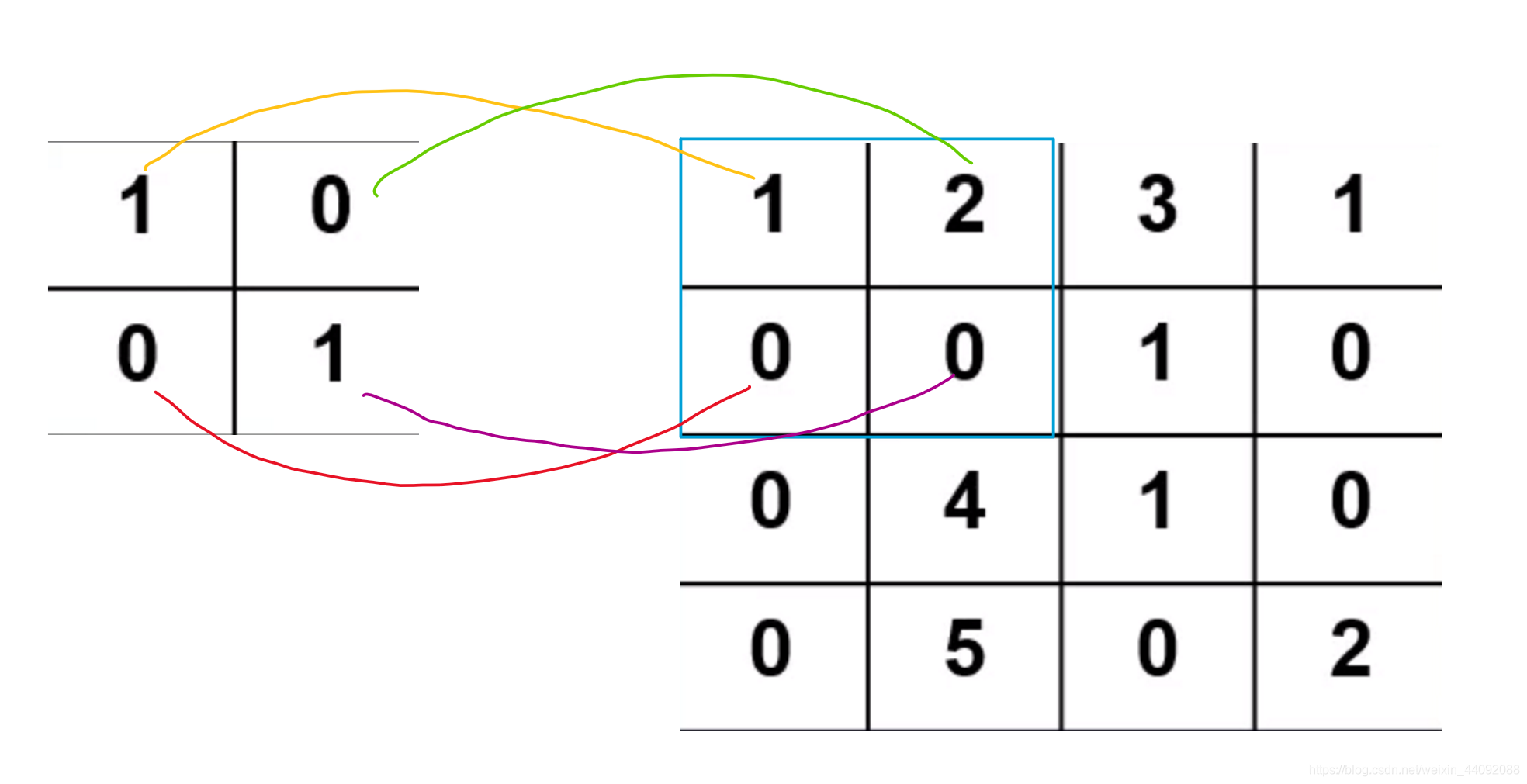
这样,计算 1 ∗ 1 + 2 ∗ 0 + 0 ∗ 0 + 0 ∗ 1 1 * 1 + 2 * 0 + 0 * 0 + 0 * 1 1∗1+2∗0+0∗0+0∗1,得到结果 1,存入另一个矩阵,接着将卷积算子平移到下一个位置,
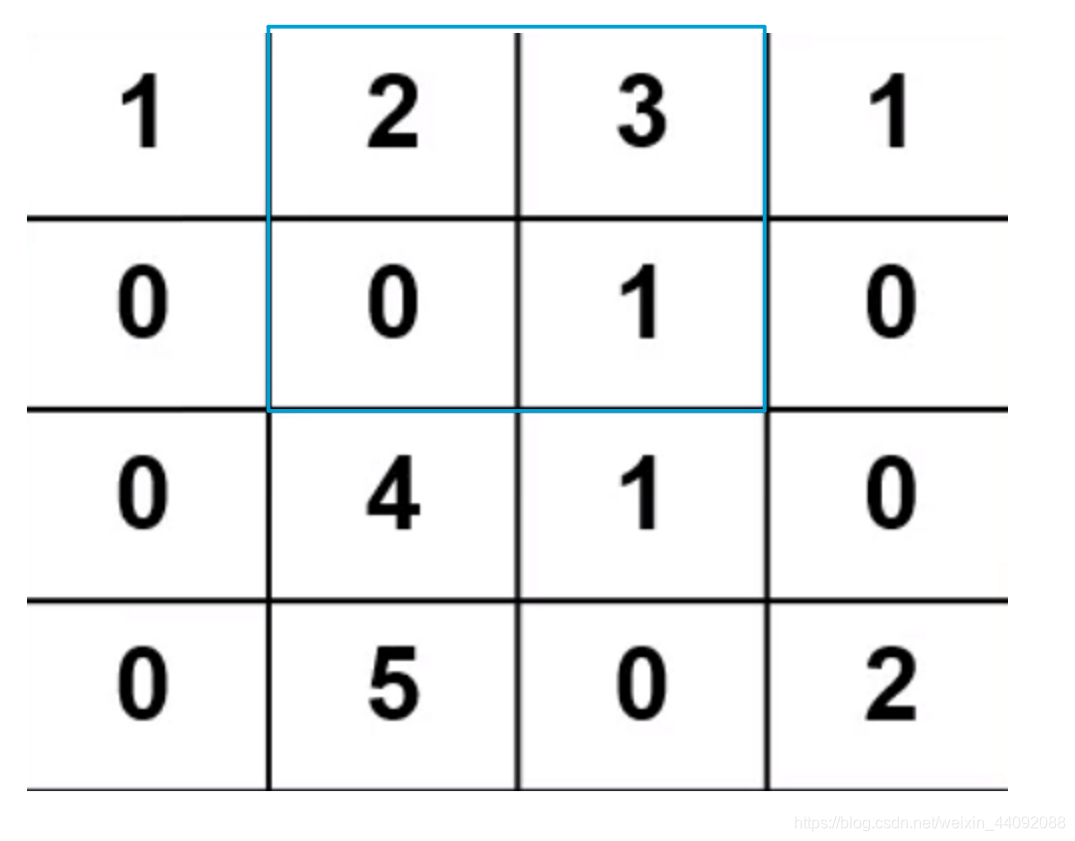
继续计算直到遍历完所有输入数据。
这里默认步长,也就是卷积算子每一次平移的距离,为 1
最后得到卷积结果,是一个 3 * 3 的矩阵
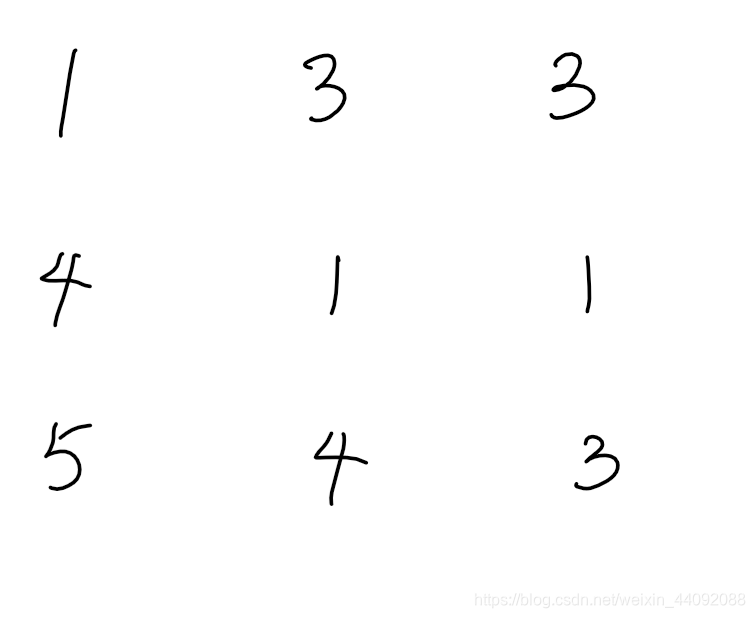
进阶
这个卷积算子还可以有很多很多层,长这样:
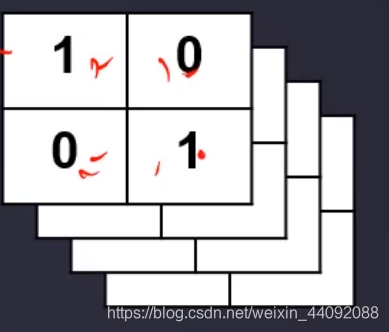
那么得到的卷积结果也就可以有很多很多层:

每一层卷积算子的工作不同,我把它们理解为检测图片不同的特征。
这样经过卷积操作,之前大小为 M ∗ N ∗ 3 M * N * 3 M∗N∗3,就会变得很深,最后一个数字有可能变成 32, 64 之类的。
注意,输入数据也可以有很多层,理解好单层数据怎么变化的,多层数据叠加起来就好了。
卷积步长stride 和 padding
步长
卷积算子每一次移动的距离,假如 stride = 2,
那么移动就是这样子的:
-
第一步:
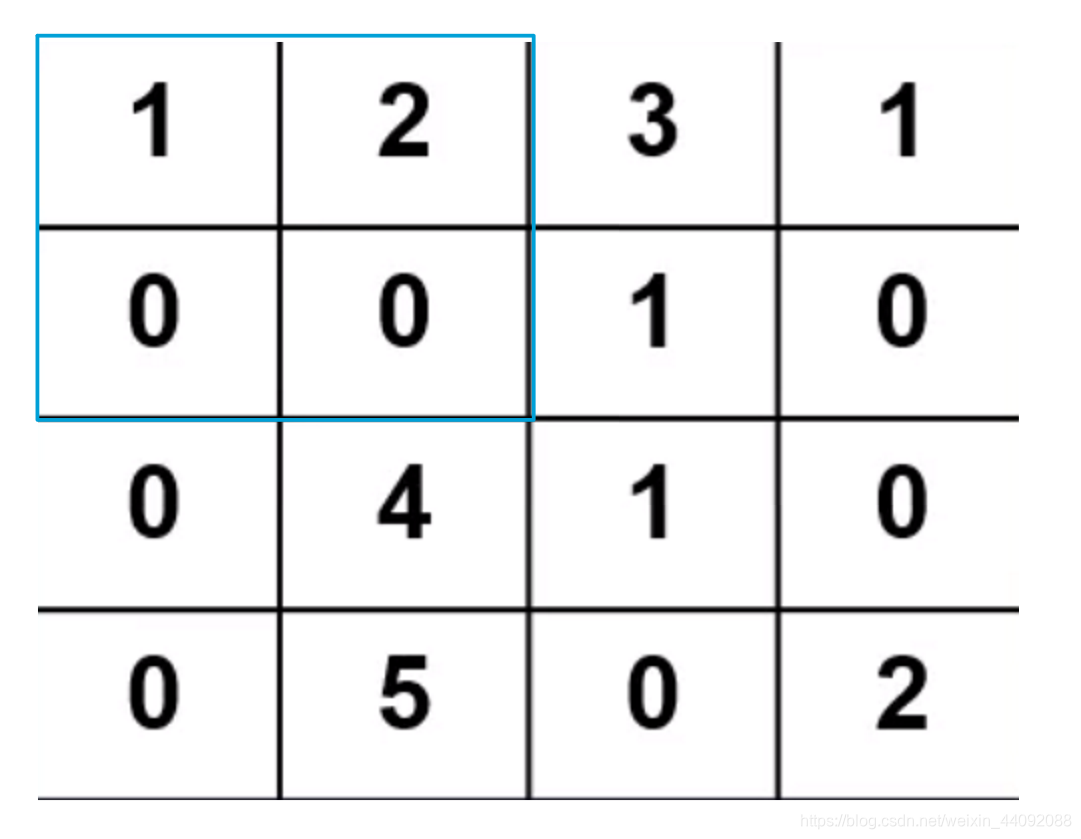
-
第二步:
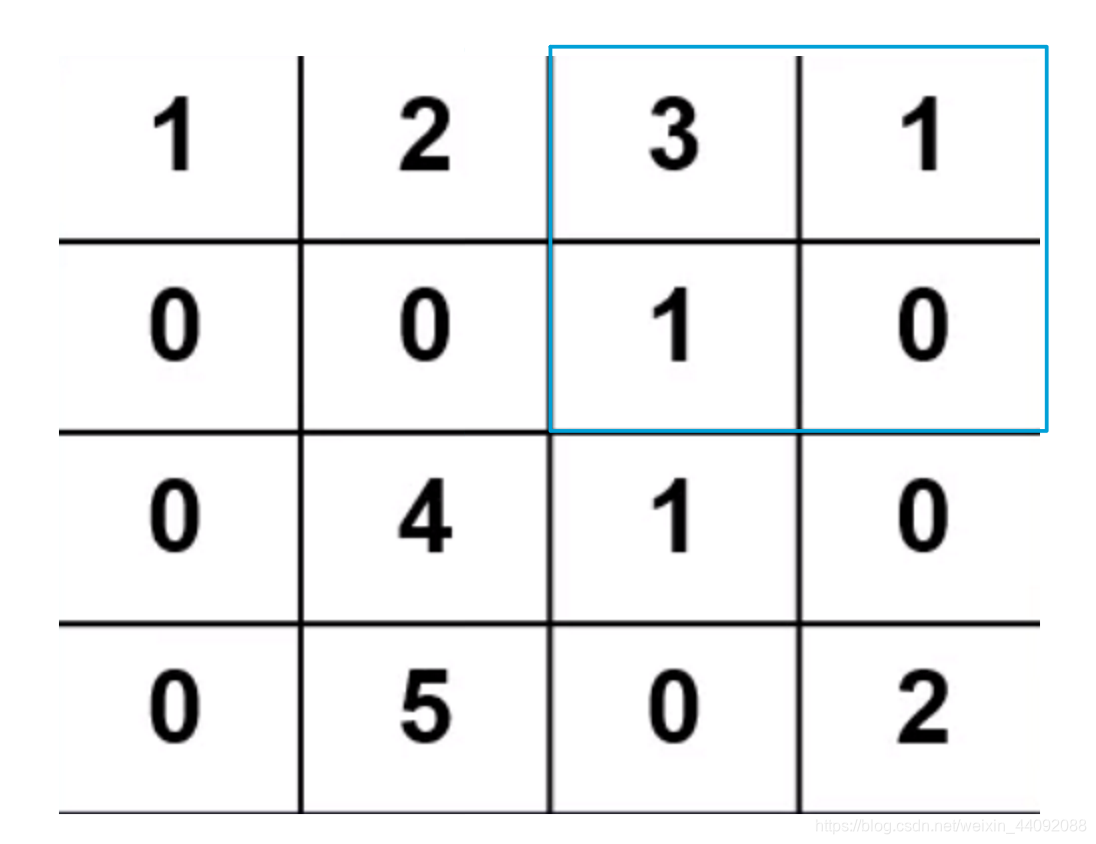
-
第三步:
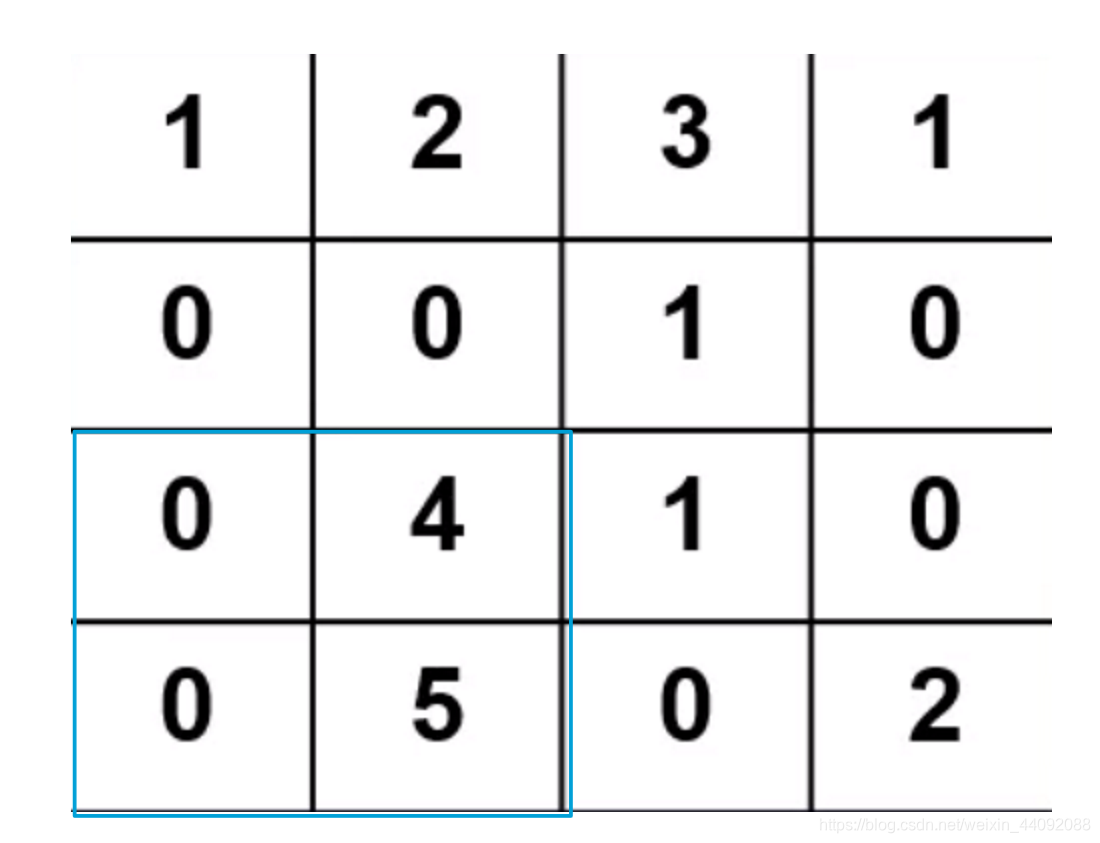
最后得到一个 2 * 2 的矩阵
padding
简单来说,嫌最后卷积结果矩阵太小了,把它周围一圈填充起来,
假设 padding = 1, 在结果周围增加一圈:
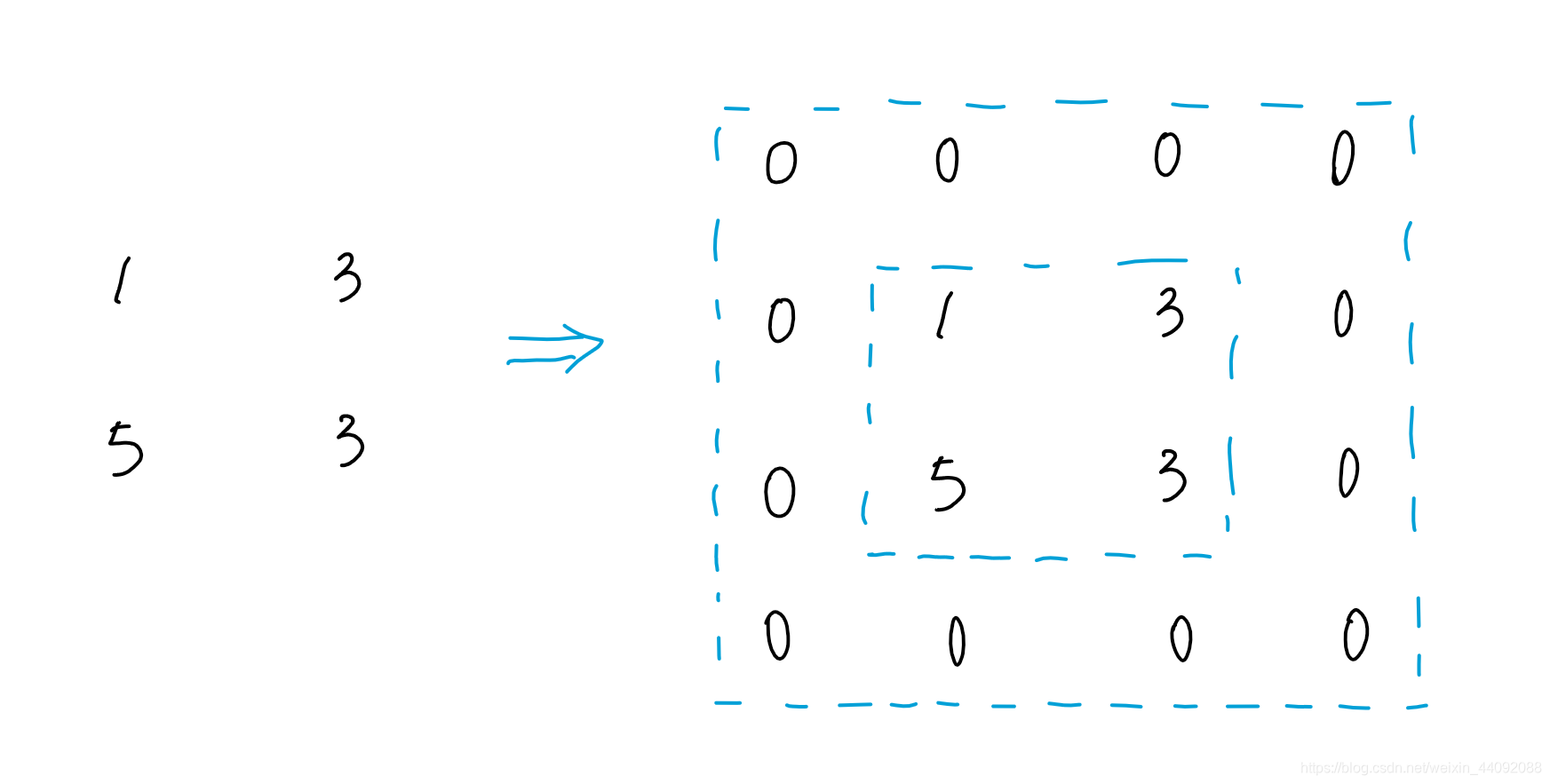
卷积结果尺寸大小
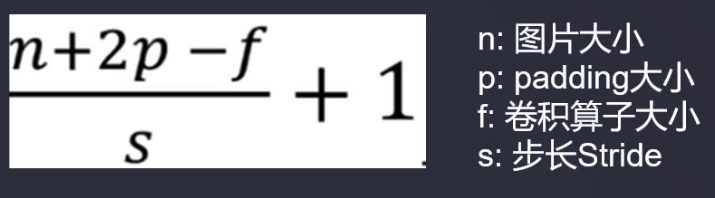
池化层
池化算子结构上和卷积算子一样,不过就只有两种:
取最大值和求加权平均
全连接层
主要做分类器的工作,常见的有 SVM, FCN, 全局池化;
模型的结尾部分,和输出相连。
输出信息为预测的分类,输出模型自己认为可能性最大的分类,比如是一只猫,可能性为88%
经典卷积神经网络结构
ALEXNET
一炮打响了卷积神经网络的名号
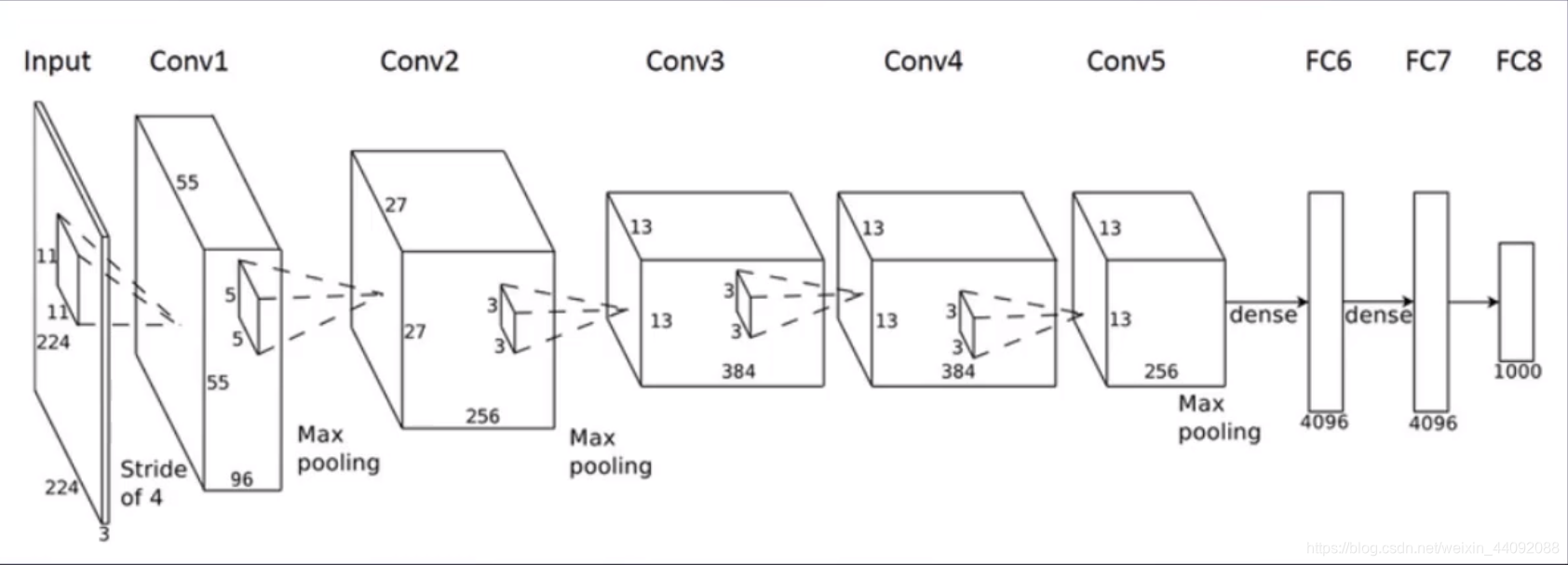


随着隐藏层越来越多,分类准确率反而下降了。这样的现象较多梯度消失或者梯度爆炸,
比如有一个权重参数是 2,迭代10次就是 210= 1024(梯度爆炸),另一个参数很小,为0.5,迭代十次是0.00097(梯度消失)
不合适的激活函数或者过大的初始权重也可以导致梯度消失。
提醒一下,这两者的产生原因并不一致。
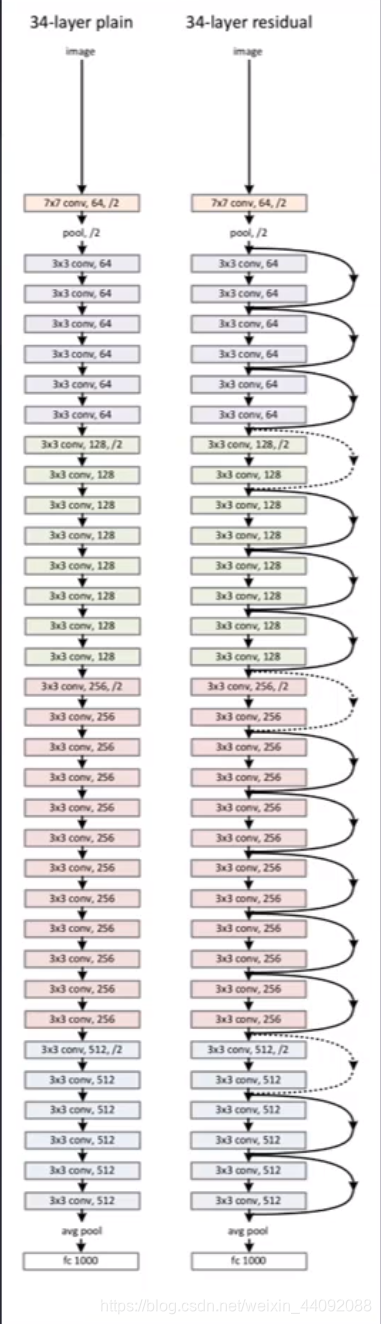
ResNet
即为残差神经网络,专门解决之前受到的梯度消失和梯度爆炸的困扰而诞生的模型。
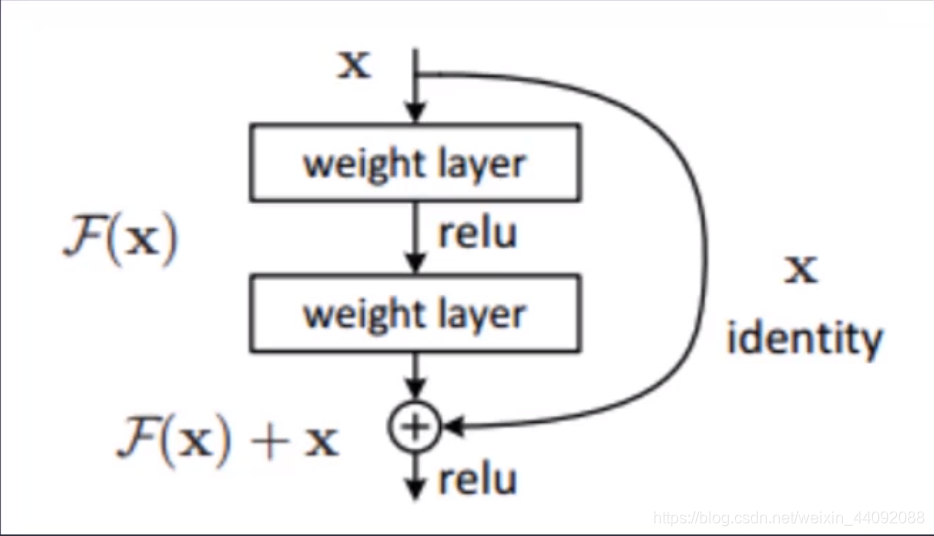
主要创新是将原始输入数据和经过变换的数据叠加在一起,继续传递下去,可以很好地纠正梯度消失和梯度下降
以后的神经网络又可以很长很长了

Inception
卷积算子的大小是人为规定的,这就很让人犯难了,到底选 11, 33, 还是5*5呢,
干脆我全都要了,不做选择题,这就是本模型的主要创新:
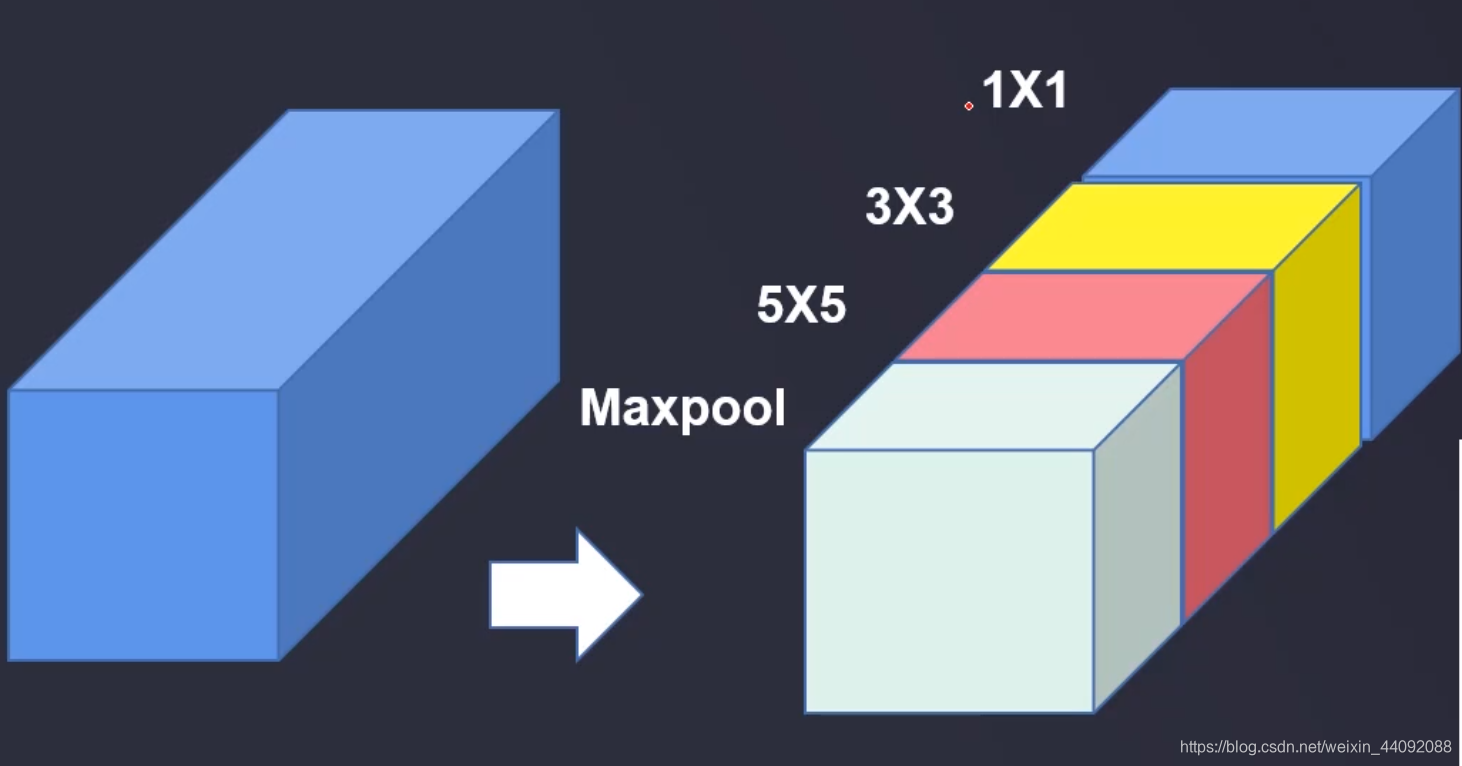
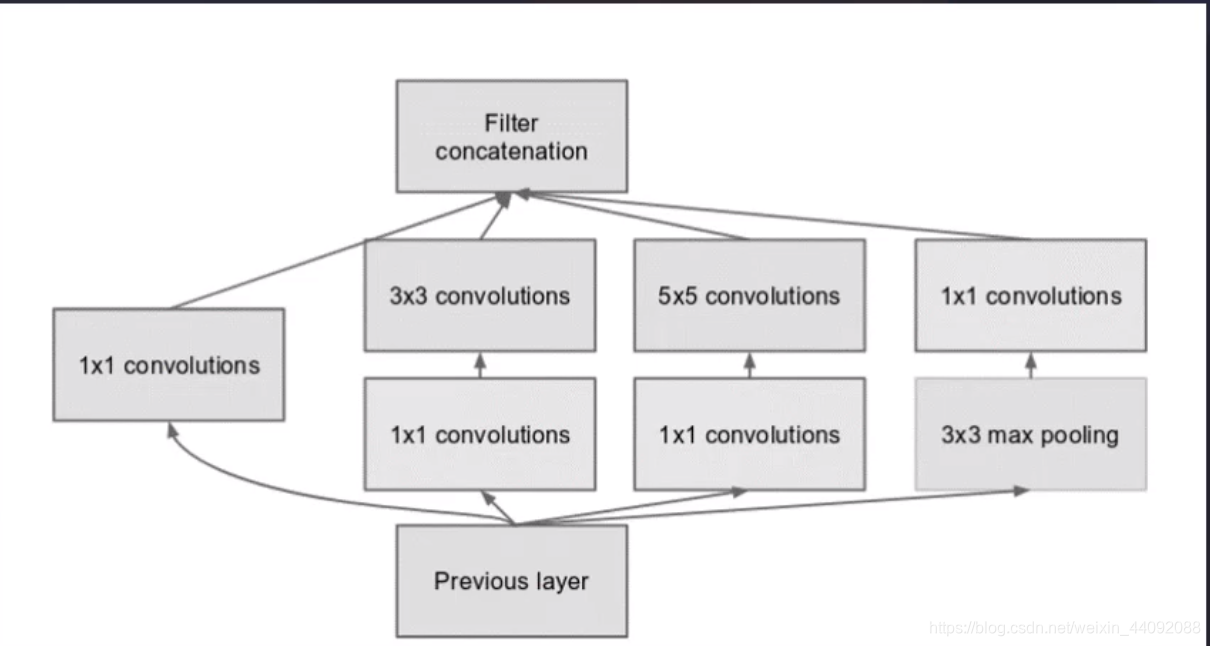
应该选择什么样的算子大小也交给模型自己训练吧!
