何为索引
MySQL官方对索引的定义:索引(index)是帮助MySQL高效获取数据的数据结构,可以简单的理解为快速查找数据结构。索引用于快速找出在某个列中具有某一特定值的行,不使用索引,MySQL必须从第一条开始读完整个表,直到找出相关行。建立列索引,索引在底层对字段中数据进行排序,将会在查询时节省很大一部分时间。所有的列类型(字段类型)都可以设置索引,索引将大大加快查询速度。一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
在数据之外,数据库系统还维护这满足查找特定算法的数据结构,这些数据结构以某种方式引用(指向)数据。这种数据结构就是索引。这样就可以在这些数据结构上实现高级查找算法。
假设在图书馆中查找一本书籍,每本书籍有自己的编号。(Col1为表id,Col2为书记编号)
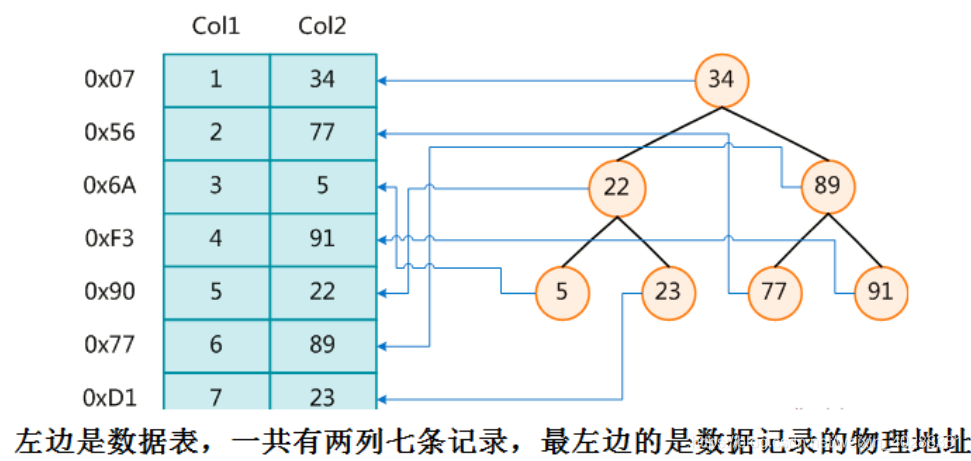
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值(通过索引键值找物理地址指针 key-value)和一个指向对应数据记录物理地址的指针,这样就可以运用二叉在一定的复杂度内获取到相应的数据。我们平常所说的索引,如果没有特别的明指,都是指B树(多路搜索树,并不一定是二叉的)结构组织索引。其中聚集索引,次要索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。除了B+树这种类型的索引,还有哈希索引等(hash index)。
索引分类
MySQL中分为聚集索引和非聚集索引
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。
我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
进一步引申一下,我们可以很容易的理解:每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。(聚集索引规定了数据在表中的物理存储顺序)
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。
我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”(目录和内容没有逻辑上的关系)
非聚集索引
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
- 单值索引,即一个索引只包含单个字段,一个表可以有多个单值索引
- 唯一索引,索引列的值必须唯一,但允许有空值(表中的主键会自动建立唯一索引)
- 复合索引,即一个索引包含多个字段
聚集索引
定义:数据行的物理顺序与列值(一般是主键)的逻辑顺序相同,一个表中只能有一个聚集索引
| 物理地址 | id | username | score |
|---|---|---|---|
| 0x01 | 1 | 小明 | 99 |
| 0x02 | 2 | 小红 | 89 |
| 0x03 | 3 | 小白 | 79 |
| 0x04 | 4 | 小黑 | 69 |
| … | … | … | … |
| 0xff | 256 | 小黄 | 70 |
数据行的物理顺序与列值的顺序相同,如果我们查询id相对靠后的数据,那么这行数据的物理地址在磁盘中的物理地址也会相对靠后。而且由于物理排列方式与聚集索引的顺序相同,也只能建立一个聚集索引(每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。)
索引基本语法
- 创建:
CREATE [UNIQUE] INDEX indexName On mytable(columnName(length)) - 删除:
DROP INDEX [indexName] On mytable - 查看:
SHOW INDEX FROM table_name\G
使用ALTER命令:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。ALTER TABLE tbl_name ADD UNIQUE index_name (column_list)这条语句创建索引的值必须是唯一的(除了NULL,NULL可以出现多次)ALTER TABLE tbl_name ADD INDEX index_name (column_list)添加普通索引,索引值可出现多次ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)该语句指定了索引为FULLTEXT,用于全文索引
#单值索引
create index idx_student_name on student(name);//在student表的name字段创建索引-->单值索引,只在一个字段建立一个索引
#复合索引
create index idx_student_nameId on student(name,id);//在student表的name和id字段创建索引-->复合索引
索引结构
- BTree索引
- Hash索引
- full-text索引
- R-Tree索引
BTree检索原理
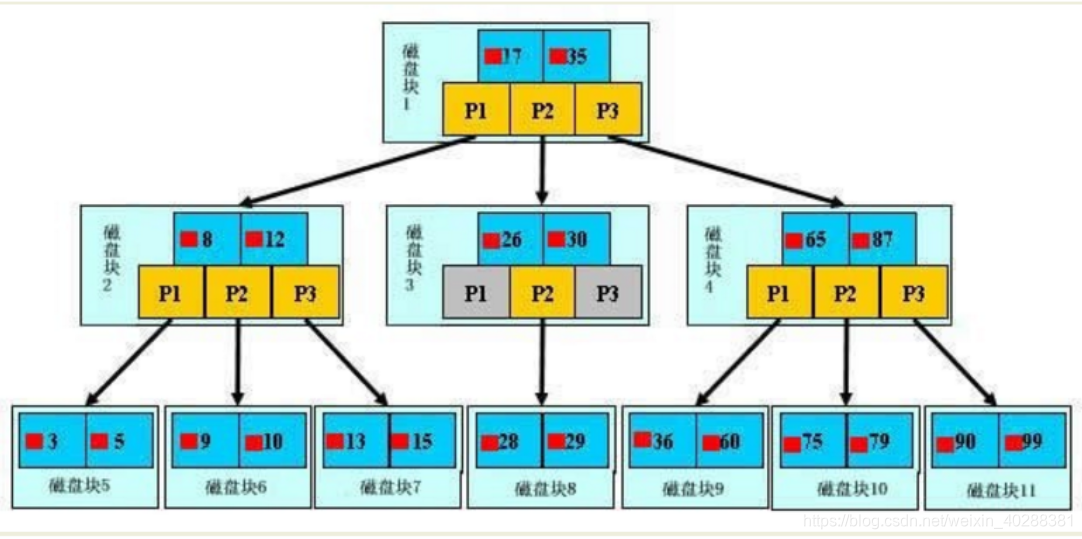
初始化介绍
一棵B+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色)和指针(黄色)
如磁盘块1包含的数据项17和35,包含指针P1,P2,P3
P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块
真实的数据存在于叶子节点即3,5,9,10,13,15,…99(聚簇索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块)
非叶子节点不存储真实数据,只存储指引搜索方向的数据项,如17和35并真实存在数据表中
查找过程
如果要查找数据项29,那么会首先把磁盘块1由磁盘加载到内存,此时发生一次IO;在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存中进行二分查找的时间非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,此时发生第二次IO;29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘到内存,发生第三次IO,同时内存中做二分查找到29,结束查询,总计三次IO
真实情况是:3层的B+树可以表示上百万的数据,如果没有索引,每个数据项都要发生一次IO,总共需要上百万的IO,相比三次,显然成本非常高。
索引缺点
- 创建索引和维护索引要耗费时间
- 索引也占用空间,实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录。
- 当对表中的数据进行增加,删除,修改时,索引也需要动态的维护,降低了数据的维护速度
- 在参数较少的字段上不建议使用索引,比如性别,只有男/女。在一个字段上不同值较多可以建立索引
为什么状态少的字段不适合建索引
当我们构建非聚集索引之后:
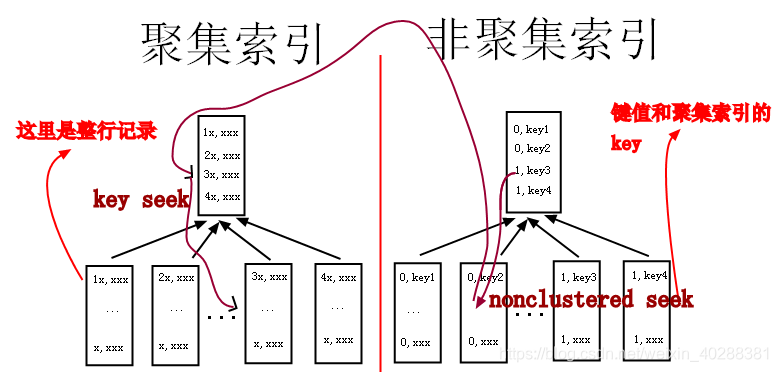
非聚集索引的叶节点存储的不是真实的数据,而是真实数据的指针。每当我们利用非聚集索引寻找数据,都会找到非聚集索引的叶节点,然后再用指针去聚集索引下找到真实的数据。简单来说,我们每次使用非聚集索引获取数据,都会在B树中来回"折腾"。因此我们应该减少获取次数。如果一个字段中重复性数据过多,就需要多次获取造成性能下降,比如student表中gender字段都为男,此时为该gender建立非聚集索引。这样只要我们查询时使用到了gender=男这一condition,就会重复折腾个(字段为男的个数)。我们想要做到折腾的少,就必须在高唯一性的字段上建立索引,这样的话在非聚集索引B树中符合的数据相对较少,就减少了"折腾"的次数。
索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99.一个索引的选择性越接近1,这个索引的效率就越高。