1.到caffe的github上去下载训练好的GoogleNet模型
训练好的模型意思的一些参数比如权值和观测值都已经被训练好,都存在这个模型中。
注:deploy文件是模型结构的描述文件。我们用之前第四篇博客模型可视化的方法用draw_net.py将该模型画出来:

网络比较长,层数多,宽度宽,我这里只上传一个小截图,就不把全部图片上传过来,大家有兴趣可以自己看看网络结构图。
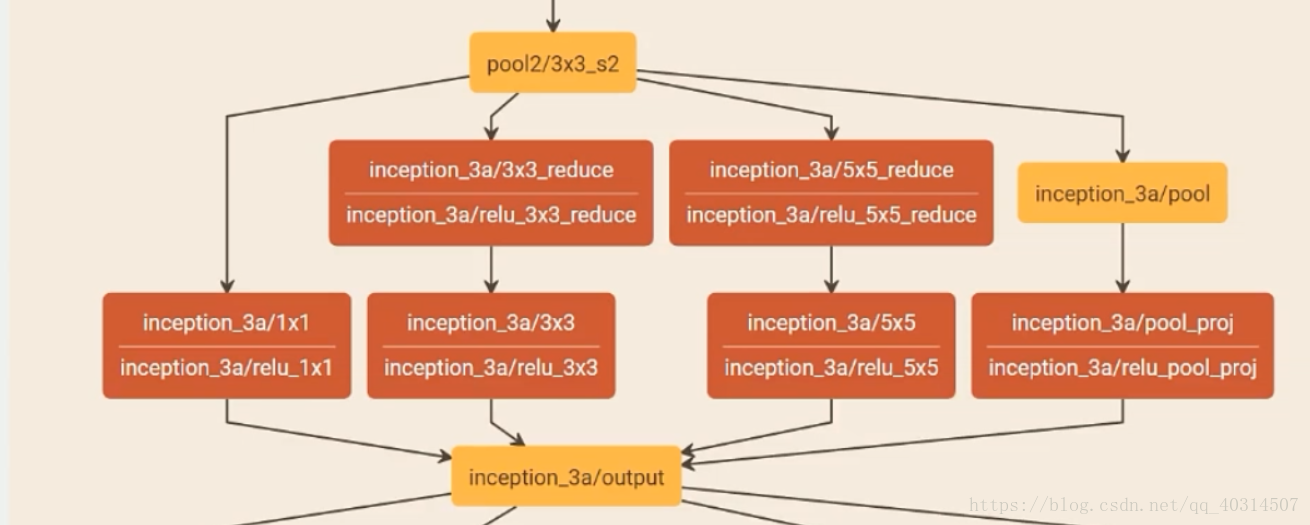
图中Inception结构中,不同大小的卷积核意味着不同大小的感受野,最后的合并意味着不同尺度特征的融合。inception是googleNet网络很有特点的结构。采用1,3,5为卷积核的大小,是因为使用步长为1,pad=0,1,2的方式采样之后得到的特征平面大小相同。因为数据的合并要求图片的大小和纬度必须一样。
整个网络有两千多行代码,我这里把部分需要注释的代码上传:
name: "GoogleNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 224 dim: 224 } } #每一次输入10张图片,3维数据,图片像素为224*224
}
layer {
name: "conv1/7x7_s2"
type: "Convolution"
bottom: "data"
top: "conv1/7x7_s2"
param {
lr_mult: 1
decay_mult: 1 #用来调节权值衰减参数
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 3 #pad就是给图像补零,pad:3就是补3圈。
kernel_size: 7
stride: 2 #步长
weight_filler {
type: "xavier"
std: 0.1 #标准差
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
2.准备要识别的图片

扫描二维码关注公众号,回复:
53776 查看本文章

3.准备synset_words.txt文件
可以在网上下载。synset_word.txt是标签文件,里面有1000行代表有1000种物体、1000种分类。使用googlenet时会返回一个编号,我们可以从此文件夹中找到编号对应的物体。

4.使用python接口调用实现图像识别,程序下载地址:
对上面的图片识别后,最后结果如下:
