步骤如下:

Linux环境基础配置可参照我上一篇博客http://www.cnblogs.com/whcwkw1314/p/8921352.html
一、准备工作
1.目录规划及软件安装
创建目录:在根目录下的opt文件夹中创建4个文件夹
datas放测试数据 softwares放软件安装压缩包 modules软件安装目录 tools开发IDE以及工具

查看是否创建成功

上传软件:
这里我用了linux自带的上传下载软件
$ sudo yum install -y lrzsz 其中 rz: 上传文件 sz: 表示下载
在softwares文件夹下上传hadoop2.x版本的压缩包 jdk在上篇博客中已经安装完毕

给该压缩包添加执行权限

解压到指定目录modules

解压完毕后查看hadoop-2.7.3文件夹属性

更改所属用户及用户组为当前用户, 使之后的操作更加安全 ,root用户下的误操作可能会造成很大影响

配置*-env.sh环境变量文件 hadoop-env.sh yarn-env.sh mapred-env.sh
进入解压后的hadoop-2.7.3中的/etc/hadoop 可以看到这三个文件以及后面要配置的一些配置文件

这里我用nodepad++连接虚拟机进行更改配置操作 直观方便
首先更改hadoop-env.sh

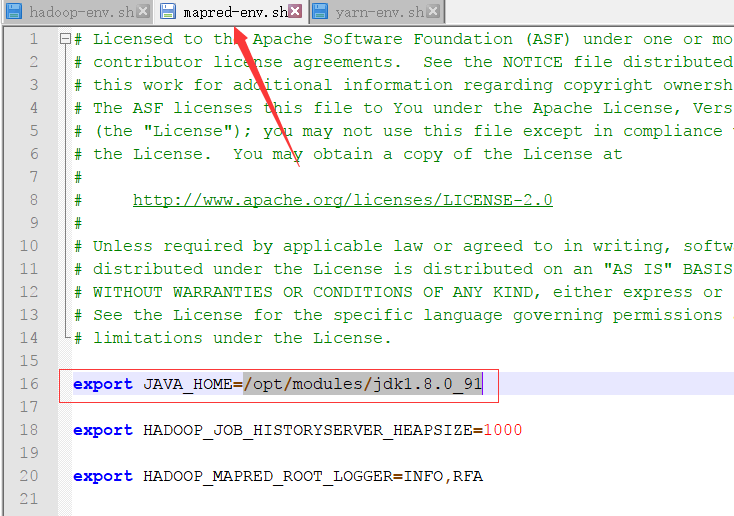
将JAVA_HOME路径更改为之前安装JDK的路径
export JAVA_HOME=/opt/modules/jdk1.8.0_91
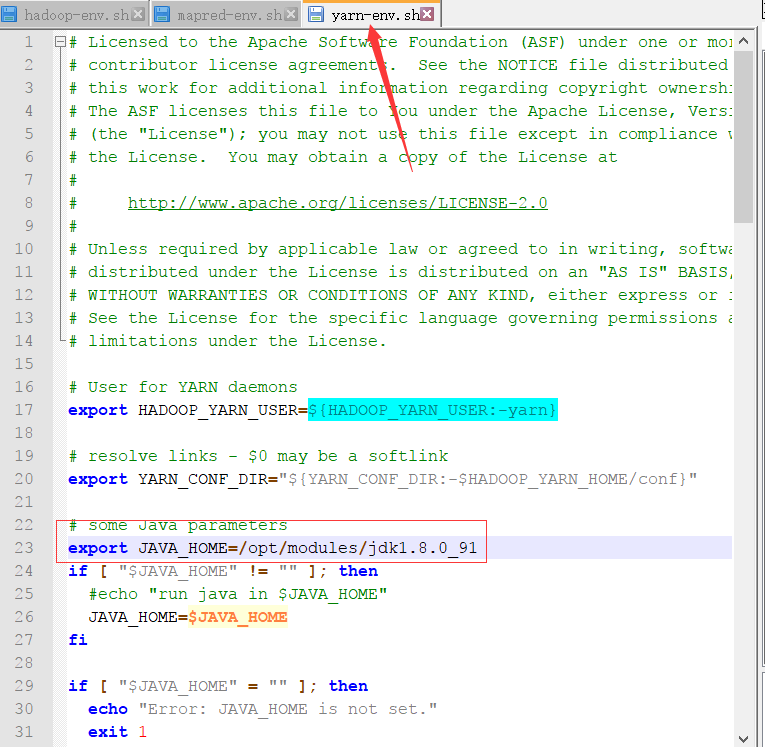
然后更改完yarn-env.sh mapred-env.sh 这2文件
赋予这三个文件执行权限

二、HDFS安装
首先配置HDFS环境
1.创建临时数据存储目录(在hadoop-2.7.3当前目录下创建data文件夹内含tmpData文件夹) ./表示在当前目录下

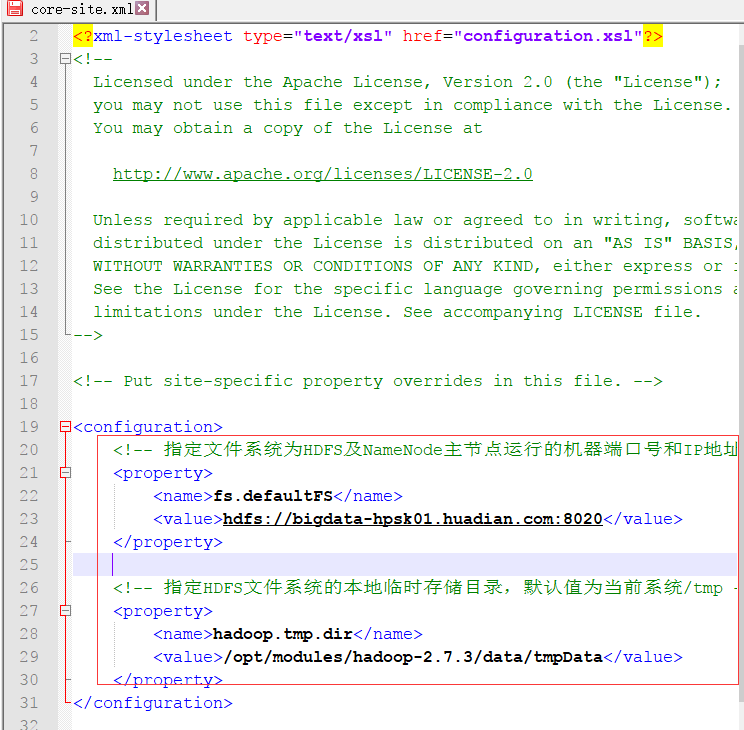
2.配置core-site.xml文件
3.配置hdfs-site.xml

4.配置slaves文件:指定DataNode运行在哪些机器上
此文件中一行表示一个主机名称,会在此主机上运行DataNode

下一步启动服务
对于HDFS文件系统来说 第一次要格式化系统
可以在下面的目录中看到 namenode -format命令是用来格式化HDFS文件系统的

若初始化没有报错即成功。

启动HDFS服务 主节点和从节点

然后验证是否成功
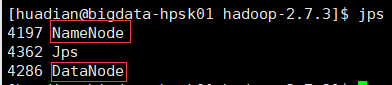
第一种方式:查看进程 命令行输入jps 出现NameNode DataNode即成功
第二种方式:通过web ui界面查看 http://bigdata-hpsk01.huadian.com:50070 这里通过主机名访问确保在本地hosts文件中配置了映射。(我在上篇博客中已经配置好了映射)
出现如下界面即成功
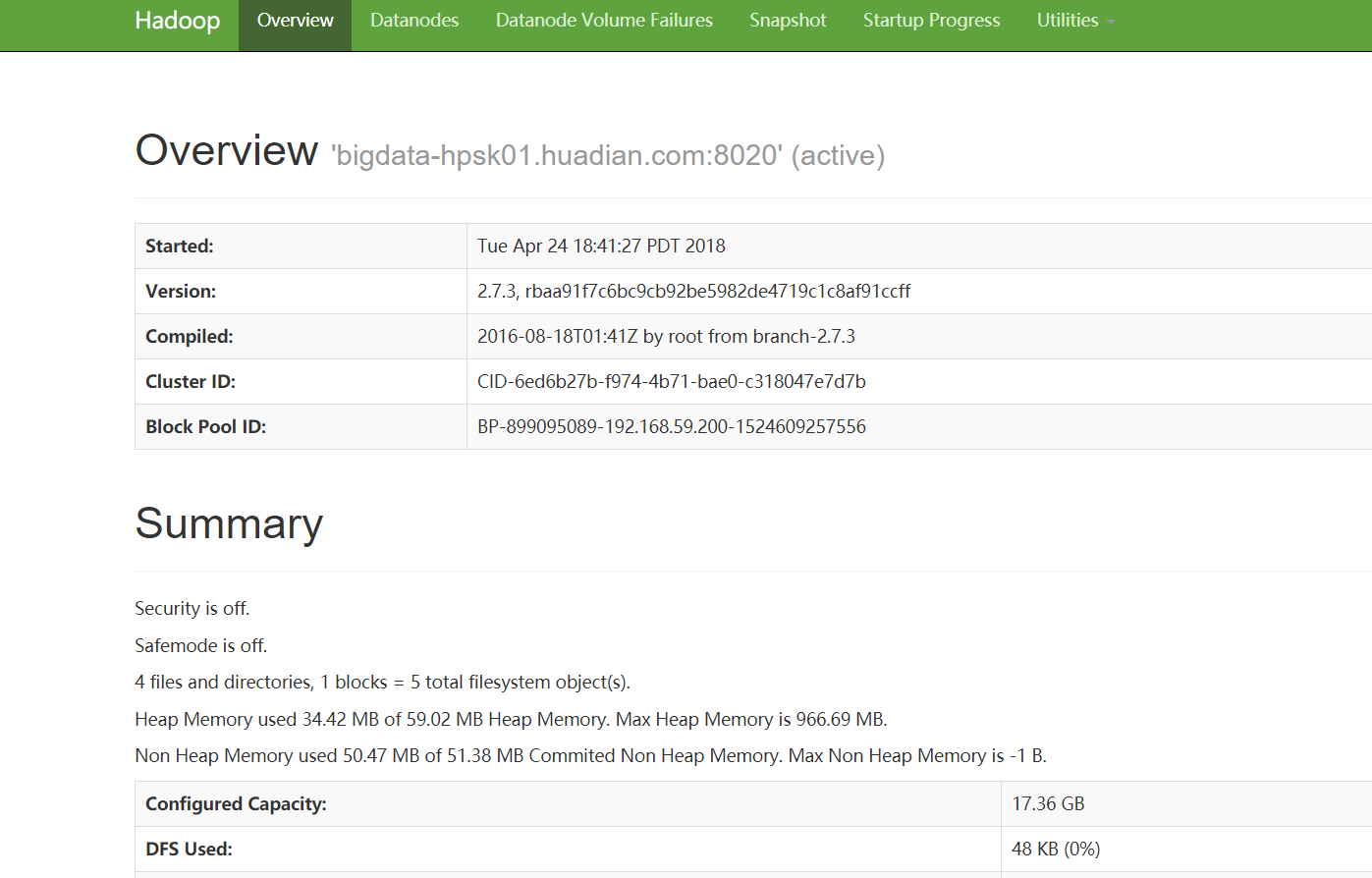
测试HDFS
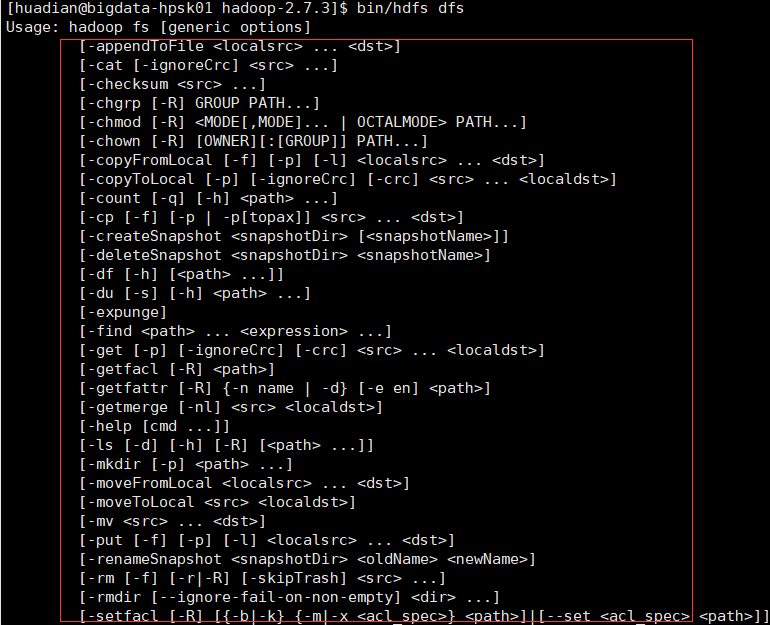
1.查看帮助文档
$ bin/hdfs dfs
可以看到对HDFS操作的命令
2.创建目录
$ bin/hdfs dfs -mkdir -p /datas/tmp
3.上传文件
$ bin/hdfs dfs -put etc/hadoop/core-site.xml /datas/tmp
4.列举目录文件
$ bin/hdfs dfs -ls /datas/tmp

5. 查看文件的内容
$ bin/hdfs dfs -text /datas/tmp/core-site.xml

最后我们去webui界面看看HDFS文件系统里面是否有了这些内容
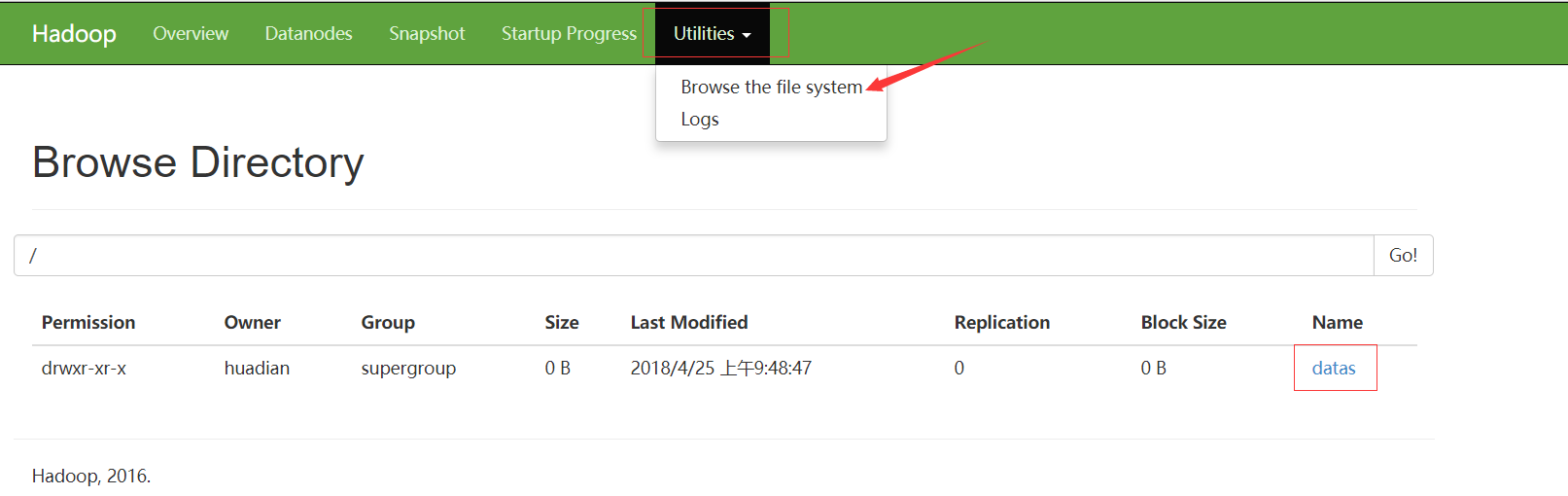
datas文件夹里面有tmp文件夹

然后我们上传了core-site.xml文件

测试成功~
三、YARN安装
配置YARN集群
对于分布式资源管理和任务调度框架来说:
在YARN上面运行多种应用的程序
- MapReduce
并行数据处理框架
- Spark
基于内存分布式计算框架
- Storm/Flink
实时流式计算框架
- Tez
分析数据,速度MapReduce快
主节点:
ResourceManager
从节点:
NodeManagers
配置yarn-site.xml文件
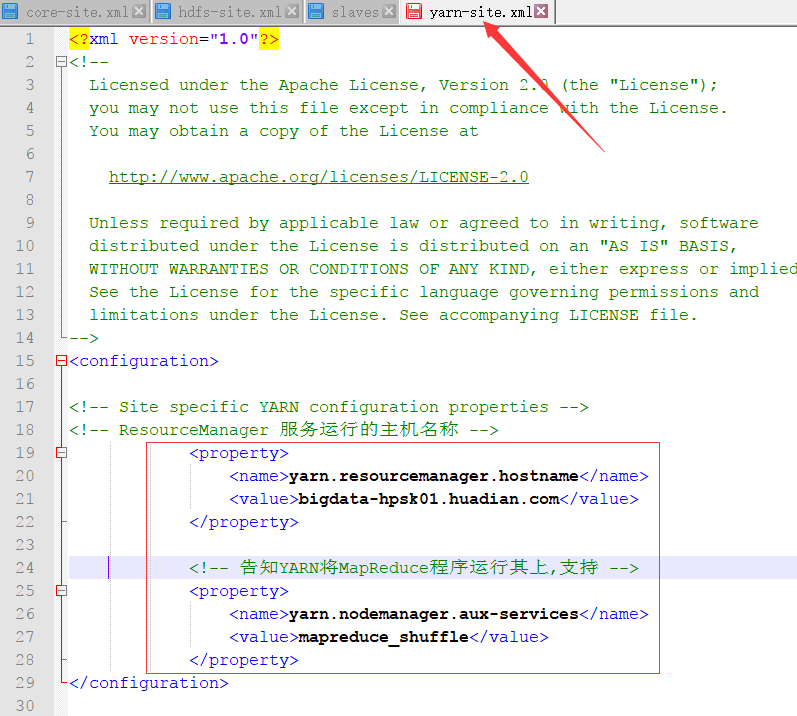
配置slaves文件
指定NodeManager运行的主机名称,由于NodeManager与DataNode同属一台机器,前面已经配置完成。
启动服务
RM 主节点:
$ sbin/yarn-daemon.sh start resourcemanager
NM 从节点:
$ sbin/yarn-daemon.sh start nodemanager
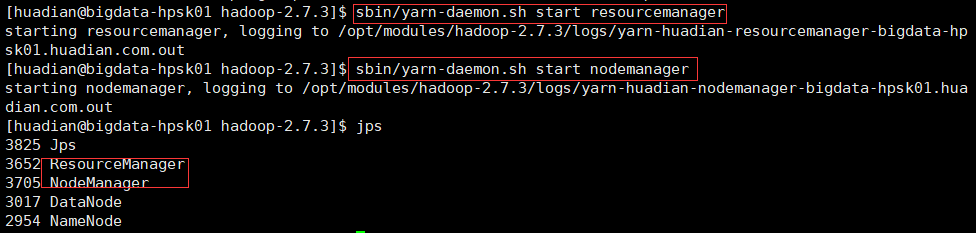
输入jps可以看到已经启动成功了,也可查看所有与java相关的进程 ps -ef|grep java
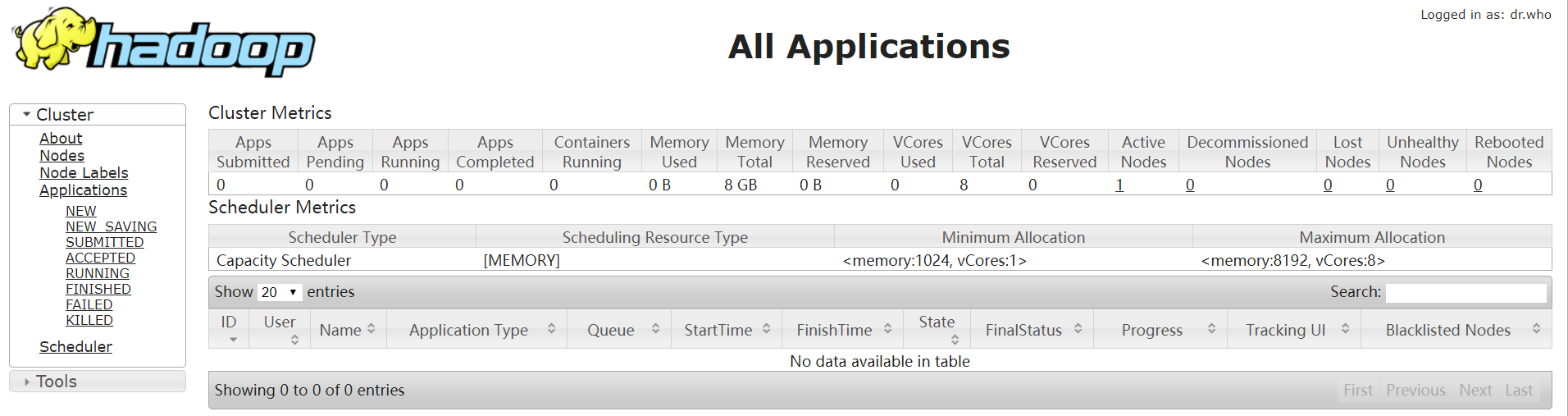
最后通过web ui 界面来验证 出现如下界面OK
四、运行MapReduce
MapReduce: 并行计算框架(Hadoop 2.x)
思想:分而治之
核心:
Map: 分
并行处理数据,将数据分割,一部分一部分的处理
Reduce: 合
将Map处理的数据结果进行合并,包含一些业务逻辑在里面
大数据计算框架中经典案例(下面我们来运行这个案例):
词频统计(WordCount)
统计某个文件中单词的出现次数
1.配置MapReduce相关属性:
进入hadoop-2.7.3下的etc/hadoop 拷贝该目录下的MapReduce模板配置文件
$ cd etc/hadoop/
$ cp mapred-site.xml.template mapred-site.xml

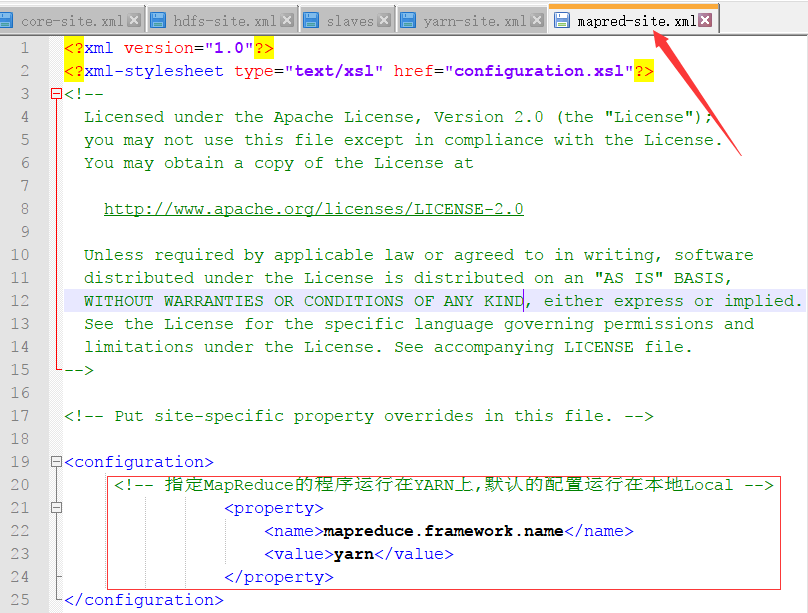
然后修改mapred-site.xml文件,指定MapReduce的程序运行在YARN上
2.提交MapReduce程序,到YARN上运行
- 准备测试数据 在cd到预先创建的/opt/datas文件夹(用来存放测试数据)中创建一个测试数据文件wc.input

编辑数据文件并保存:
在HDFS文件系统中递归创建/user/huadian/mapreduce/wordcount/input文件夹 bin/hdfs dfs命令要在hadoop-2.7.3目录下操作
$ bin/hdfs dfs -mkdir -p /user/huadian/mapreduce/wordcount/input
把我们的测试数据文件放到input目录下
$ bin/hdfs dfs -put /opt/datas/wc.input /user/huadian/mapreduce/wordcount/input

3.提交运行
这里我们用官方自带MapReduce程序JAR包 路径如下:
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-
examples-2.7.3.jar wordcountUsage: wordcount <in> [<in>...] <out>
参数说明:
<in> -> 表示的MapReduce程序要处理的数据所在的位置
<out> -> 表示的MapReduc处理的数据结果存储的位置,此路径不能存在。
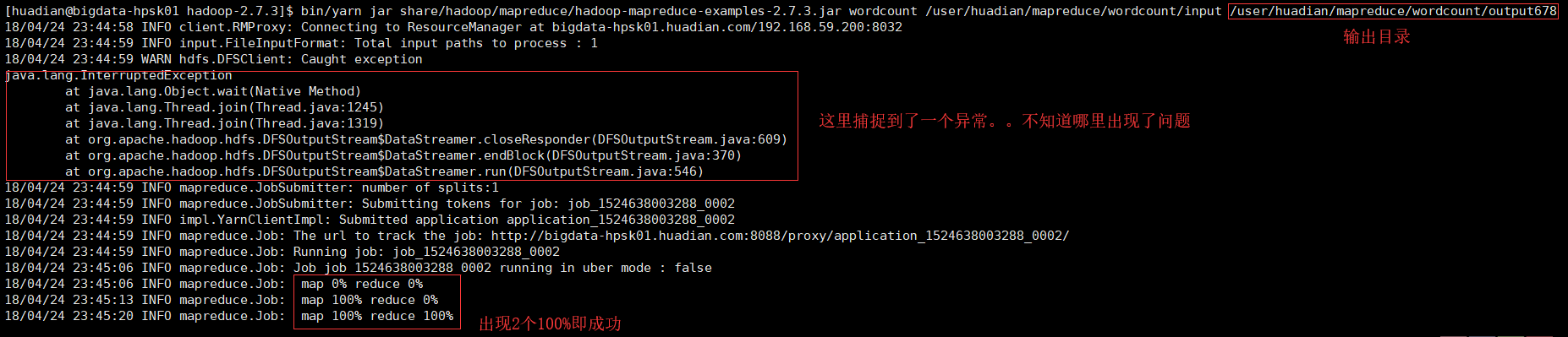
查看结果


最后启动一下日志服务
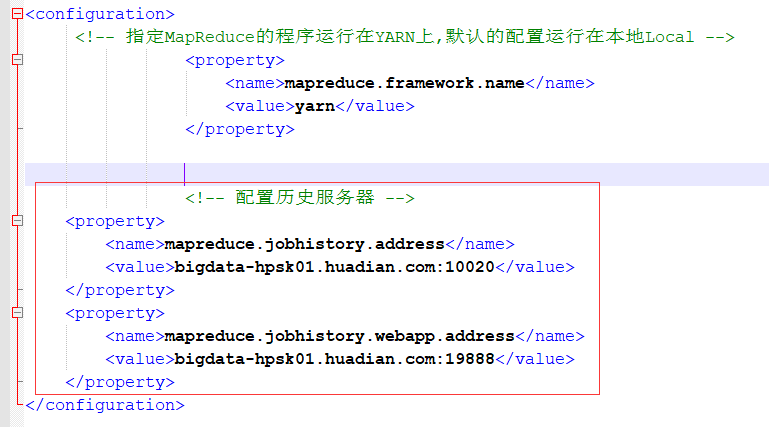
配置mapred-site.xml:
<!-- 配置历史服务器 --> <property> <name>mapreduce.jobhistory.address</name> <value>bigdata-hpsk01.huadian.com:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>bigdata-hpsk01.huadian.com:19888</value> </property>
启动服务:
$ sbin/mr-jobhistory-daemon.sh start historyserver
日志聚集功能:
当MapReduce程序在YARN上运行完成以后,将产生的日志文件上传到HDFS的目录中,以便后续监控查看
配置yarn-site.xml:
<!-- 配置YARN日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
重启YARN和JobHistoryServer服务
为了重新读取配置属性
OK~