R-FCN算法详解
R-FCN算法详解:
R-FCN论文名称:R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN论文链接:https://arxiv.org/abs/1605.06409
R-FCN算法简介
文章提出了一个基于区域的全卷积网络,用于准确高效的目标检测。与之前的区域检测算法,例如Fast/
Faster R-CNN相比,之前的目标检测算法都分为两部分:(1)由共享参数的全卷积网络;(2)以及RoI Pooling层之后的带有两个支路的全连接网络,即RoI wise子网络。而RoI wise子网络不共享参数,对于每一个区域都需要重复计算,会花费大量的时间。因此提出了全卷积网络R-FCN,可以共享参数。
R-FCN算法的优点:
- 本文基于这个问题提出了R-FCN算法,使用了position-sensitive score maps层,可以实现:
- 图片分类:平移不变性;
- 目标检测:平移变换性;
将RoI Pooling层插入到两个卷积子网络之间,是为了打破translation invariance。
算法描述
由于R-FCN神经网络是全卷积神经网络,因此可采用最新的ResNet神经网络结构,随着网络层数的增加,检测准确度会随之增加,同时由于共享参数,检测速度也得到大幅度提高。使用101层ResNet神经网络结构在PASCAL VOC2007数据集上进行实验,可得到83.6% mAP的准确度,同时每张图片的测试速度为170ms,比Faster R-CNN快2.5~20倍。
由于之前使用的神经网络结构都是由后接空间池化层的卷积层与全连接层组成的,如AlexNet,,VGG-Nets,都是由两个子网络构成的。但随着ResNet,GoogLeNets的提出,我们可以(1)使用全卷积层结构;(2)同时(最后层)空间池化层被RoI Pooling层替代。
出现的问题:
- 使用全卷积神经网络结构可以共享参数,RoI wise子网络没有隐藏层,即全卷积层结构之后加上RoI Pooling层,然后没有卷积网络,直接接上输出,但这会导致检测准确性升高,但是分类准确性下降。
- 为解决这一方法,Faster R-CNN在卷积层中间加上RoI Pooling层,分成两个全卷积的子网络,这代表会生成一个更深的RoI wise子网络,RoI wise子网络不共享参数,这会导致训练速度会下降。推断针对分类问题,更深的卷积结构对于平移更不敏感。ResNet中插入了RoI Pooling层,这种区域特色操作破坏了平移不变性,针对不同的区域,RoI wise子网络不再具有平移不变性,因此设计了10层的RoI wise子网络来解决这一问题。
| R-CNN | Faster R-CNN | R-FCN | |
|---|---|---|---|
| 共享卷积子网络的深度 | 0 | 91 | 101 |
| RoI-wise子网络的深度 | 101 | 10 | 0 |
造成这一现象的原因:
- 针对分类问题:平移图片内的物体是不合理的,因此,由ImageNet分类的主要结果表明,越具有平移不变性的全卷积层结构越是更应该被应用的。
- 目标检测问题:目标定位需要平移变换性。一个边界框内目标的平移能够带来描述边界框覆盖目标的overlaps更有意义的结果。
改进的方法:
position-sensitive score maps:
使用R-FCN算法,使用共享参数的全卷积神经网络,在FCN中包含平移变换性,建造了一个position-sensitive score maps,通过使用一系列的特色卷积层作为FCN的输出。每一个打分映射对于每一个相对空间位置(如:目标的左侧)编码位置信息。在FCN的顶部,加入了一个position-sensitive RoI Pooling层从这些映射中领导信息,没有卷积层和全连接层跟着,全部结构都是端到端的,所有的层都是共享参数的卷积层,目标检测要求编码空间信息。
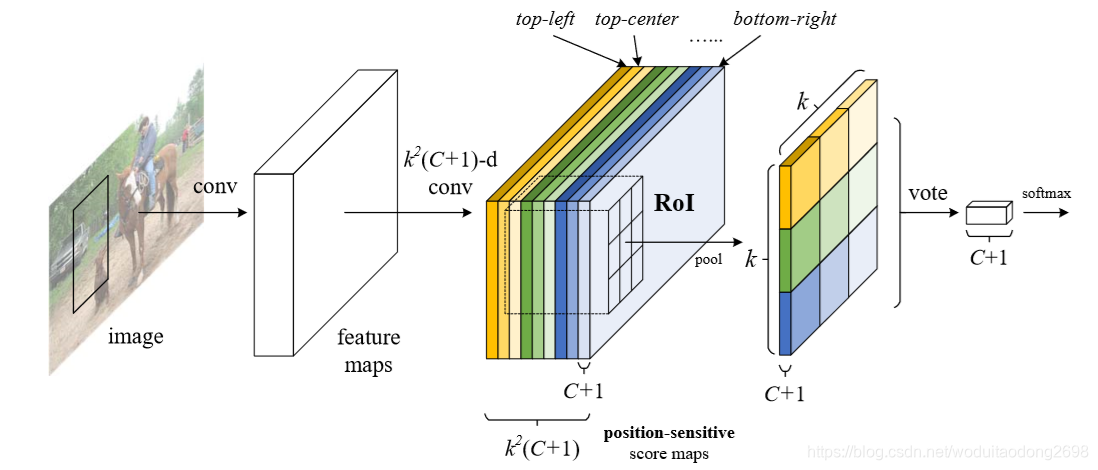
算法实现
使用了RPN的候选区域提取方法,通过共享的卷积层得到特征映射,然后经过一个全卷积的结构得到候选区域,与之前的Faster RCNN相同。之前的卷积层均相同,得到特征映射后,最后接的一层卷积层采用kk(C+1)-d的卷积核,会生成kk个position-sensitive score maps,C代表目标类别数,1代表背景,kk代表k*k spatial grid,每一层都与位置相关。从上至下,从左至右的顺序排列。
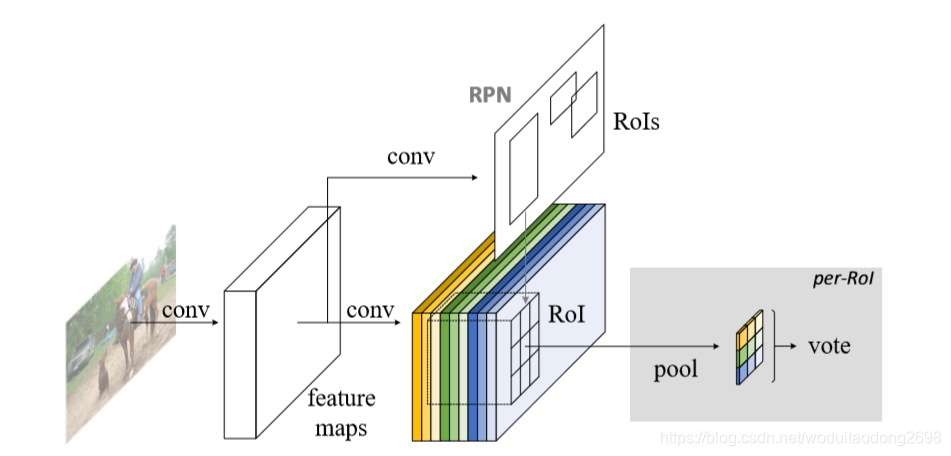
Position-sensitive score maps & Position-sensitive RoI pooling
分类:kk(C+1)-d卷积层
we divide each RoI rectangle into k×k bins by a regular grid.
For an RoI rectangleofasize w×h,abinisofasize≈ (w/k) × (h/k) .
the last convolutional layer is constructed to produce k2 score maps for each category.
Inside the (i,j)-th bin (0 ≤ i,j ≤ k−1), we define a position-sensitive RoI pooling operation that pools only over the (i,j)-th score map:
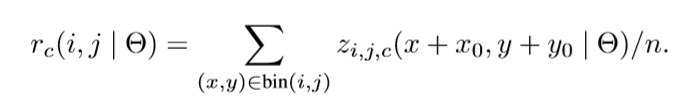
Here rc(i,j) is the pooled response in the (i,j)-th bin for the c-th category,
z(i,j,c) is one score map out of the k2(C + 1) score maps,
(x0,y0) denotes the top-left corner of an RoI,
n is the number of pixels in the bin,
and Θ denotes all learnable parameters of the network.
kk(C+1)-d卷积层用于分类,对于每一个RoI生成(C+1)-d的向量,Position-sensitive RoI pooling相当于平均卷积,最后用softmax层对C个类别进行分类。
定位:4k*k-d卷积层
4kk-d卷积层用于边界框回归,对于每一个RoI生成4kk-d的向量,然后通过平均投票得到一个4-d的向量,4个参数代表边界框的4个值,t = (tx, ty, tw, th)。对于类别数确定的目标检测,会输出4kkC-d层。
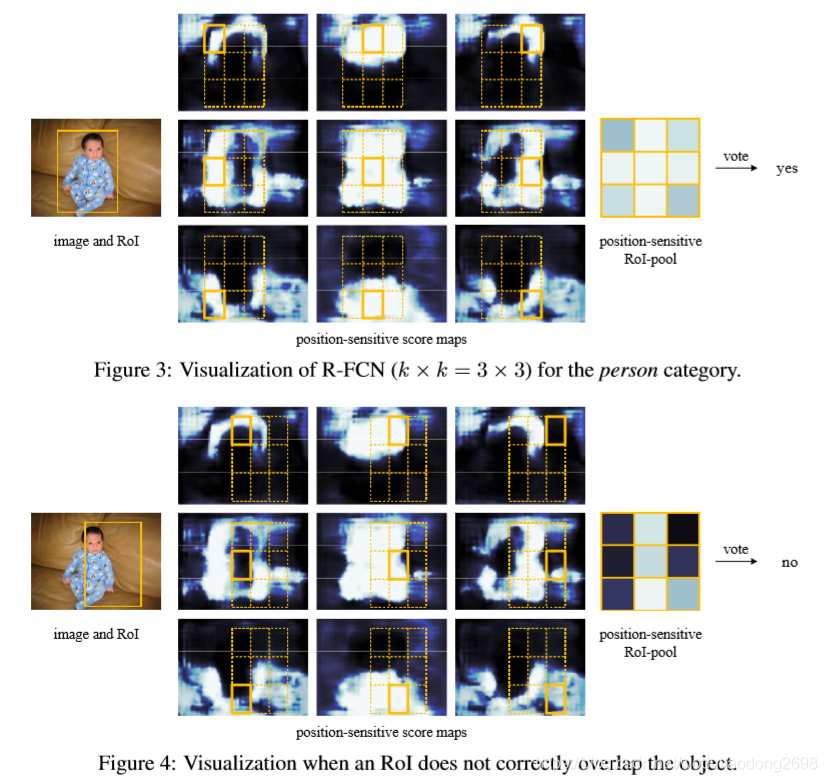
训练
损失函数
分类:使用交叉熵损失函数:
定位:IoU > 0.5为正样本,IoU < 0.5为负样本。
OHEM
所有的可以学习的层都是卷积层,使用 Online Hard Example Mining (OHEM) ,几乎不会增加训练时间。假定每张图片有N个proposals,一个直接的方法是,我们计算所有N个proposals的损失。然后我们对所有ROI按照损失进行排序。然后挑选B个具有最高损失的ROI。
参数
选用权重下降率为0.0005,momentum为0.9,输入是单一尺寸的图片(短边为600 pixel),每一张图片选取128个RoI用于反向传播,微调的学习率为0.001用于20k个mini-batch,然后0.0001用于10k个mini-batch,并且在RPN与R-FCN之间的四个步骤交替进行。之后使用阈值为0.3的非极大值抑值。
使用k=7,训练结果:
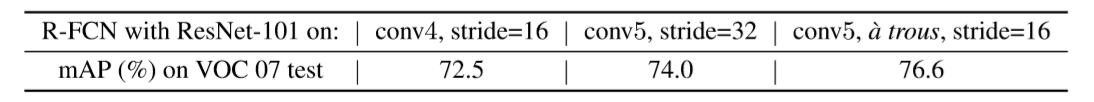
实验结果
- 比较不同的k值;
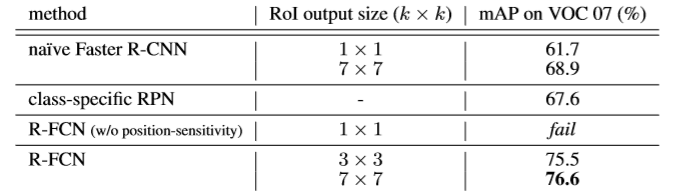
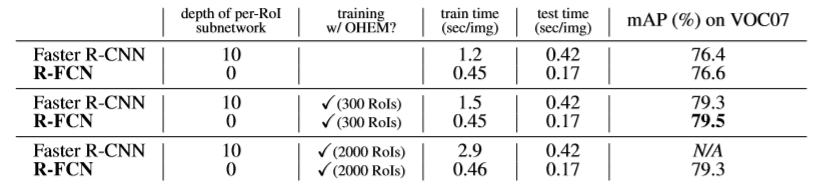
- 比较Faster R-CNN与R-FCN,同时比较不同的RoIs;
- 比较不同训练集(07 trainval and 12 trainval) 以及多尺寸训练;
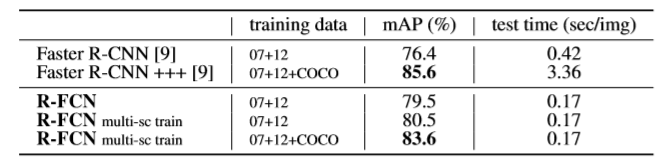
- 比较不同训练集(07 trainval+test and 12 trainval)
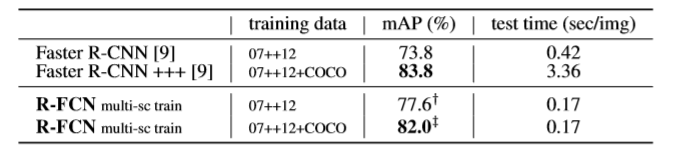
- 比较不同的神经网络深度;

- 比较不同的候选区域提取方法。
