grep
grep基础用法
文件中搜索特定字符串
grep 'query' file或者
cat file | grep 'query'查询包含特定字符串的文件
sudo grep -r 字符串 目录同时,find也可以实现该功能,详见xargs
搜索时增加行数
grep -n 'query' file搜索时忽略大小写
grep -i 'query' file搜索字符串,同时加上字符串前1行和后5行
grep -B 1 -A 5 'query' file搜索时排除存在某个字符串的行
grep -v 'exceptQuery' filegrep的基础正则
搜索包含字母数字的字符串
grep [a-zA-Z0-9] file反选,不包含字母数字字符串的行
grep [^a-zA-Z0-9] file反选,行头字母不包含字母数字字符串的行
grep ^[^a-zA-Z0-9] file^ 符号,在字符集合符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义
查询行首是a的字符串
grep '^a' file去除空白行
grep -v '^$' filecat file | grep -v '^$'需要注意的是,如果要去除空白行,而且命令行中如果包含awk,那么awk应该放在grep后面
去除注释
grep -v '^#'查询行尾是z的字符串
grep 'z$' file匹配任何字符个重复字符的字符串
grep '.*' file匹配m到n个重复字符的字符串
grep 'o\{2,5\}' fileegrep,grep的扩展型正则
去除空白行和注释
egrep -v '^$|^#' file在上一节我们要去除空白行与行首为 # 的行列,使用的是两次grep,那么如果用egrep就可以简化了。
当然,egrep也可以写成grep -E,上面的公式可以写作
grep -E -v '^$|^#' file支持正常的正则写法
| RE 字符 | 意义与范例 |
| + | 意义:重复'一个或一个以上'的前一个 RE 字符 范例:搜索 (god) (good) (goood)... 等等的字符串。 那个 o+ 代表'一个以上的 o '所以,底下的执行成果会将第 1, 9, 13 行列出来。 egrep -n 'go+d' file |
| ? | 意义:'零个或一个'的前一个 RE 字符 范例:搜索 (gd) (god) 这两个字符串。 那个 o? 代表'空的或 1 个 o '所以,上面的执行成果会将第 13, 14 行列出来。 有没有发现到,这两个案例( 'go+d' 与 'go?d' )的结果集合与 'go*d' 相同? 想想看,这是为什么喔! ^_^ egrep -n 'go?d' file |
| | | 意义:用或( or )的方式找出数个字串 范例:搜寻 gd 或 good 这两个字串,注意,是『或』! 所以,第 1,9,14 这三行都可以被打印出来喔! 那如果还想要找出 dog 呢? egrep -n 'gd|good' file |
| () | 意义:找出'群组'字符串 范例:搜寻 (glad) 或 (good) 这两个字符串,因为 g 与 d 是重复的,所以, 我就可以将 la 与 oo 列于 ( ) 当中,并以 | 来分隔开来,就可以啦! egrep -n 'g(la|oo)d' file |
| ()+ | 意义:多个重复群组的判别 范例:将'AxyzxyzxyzxyzC'用 echo 叫出,然后再使用如下的方法搜寻一下! echo 'AxyzxyzxyzxyzC' egrep 'A(xyz)+C'上面的例子意思是说,我要找开头是 A 结尾是 C ,中间有一个以上的 “xyz” 字串的意思~ |
sed
sed一般用于处理文本的行,比如对输出文本的特定行执行打印、删除、更新等操作
sed [-nefr] [動作]
選項與參數:
-n :使用安靜(silent)模式。在一般 sed 的用法中,所有來自 STDIN 的資料一般都會被列出到螢幕上。
但如果加上 -n 參數後,則只有經過 sed 特殊處理的那一行(或者動作)才會被列出來。
-e :直接在指令列模式上進行 sed 的動作編輯;
-f :直接將 sed 的動作寫在一個檔案內, -f filename 則可以執行 filename 內的 sed 動作;
-r :sed 的動作支援的是延伸型正規表示法的語法。(預設是基礎正規表示法語法)
-i :直接修改讀取的檔案內容,而不是由螢幕輸出。
動作說明: [n1[,n2]]function
n1, n2 :不見得會存在,一般代表『選擇進行動作的行數』,舉例來說,如果我的動作
是需要在 10 到 20 行之間進行的,則『 10,20[動作行為] 』
function 有底下這些咚咚:
a :新增, a 的後面可以接字串,而這些字串會在新的一行出現(目前的下一行)~
c :取代, c 的後面可以接字串,這些字串可以取代 n1,n2 之間的行!
d :刪除,因為是刪除啊,所以 d 後面通常不接任何咚咚;
i :插入, i 的後面可以接字串,而這些字串會在新的一行出現(目前的上一行);
p :列印,亦即將某個選擇的資料印出。通常 p 會與參數 sed -n 一起運作~
s :取代,可以直接進行取代的工作哩!通常這個 s 的動作可以搭配正規表示法!
查询file文件中第5到第10行
如果不用sed,就要通过'head -n 20 | tail -n 10』之类的方法来处理。
其中-n是是安静模式,p和-n配合着用,就可以取出特定行
cat file | sed -n '5,10p'删除1-5行
cat file | sed '1,5d'字符串替换
cat file | sed 's/要被取代的字串/新的字串/g'取出ifconfig中IP地址
ifconfig | sed -n '2p' | sed 's/^.*inet //g' | sed 's/ *netmask.*$//g'指定行添加/删除/修改文本
有如下文件,希望仅在源文件基础上调整后输出,而不修改源文件

在第三行前加上new line
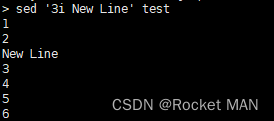
在第三行后加上New Line
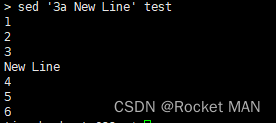
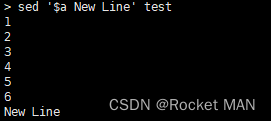
在最后一行加上New Line
指定行添加文本(修改源文件)
如果需要修改源文件,而不是输出内容,可以在上面的每个公式中新增 -i,例如,在最后一行添加New Line
sed -i '$a New Line' testawk
awk 可以处理文件,也可以读取来自前个指令的 standard output。它 是'以行为一次处理的单位', 而'以字段为最小的处理单位'
awk '条件类型1{动作1} 条件类型2{动作2} ...' file整个 awk 的处理流程是:
- 读入第一行,并将第一行的资料填入 $0, $1, $2.... 等变量当中;
- 依据 “条件类型” 的限制,判断是否需要进行后面的 “动作”;
- 做完所有的动作与条件类型;
- 若还有后续的'行'的数据,则重复上面 1~3 的步骤,直到所有的资料都读完为止。
取出登录日中中最后5行,只列出登录账号(第一栏)和IP(第三栏),中间用tab键隔开
last -n 5 |awk '{print $1 "\t" $3}'上面因为不论哪一行都要处理,因此,就不需要有 “条件类型” 的限制 。另外$1代表第一栏,$3代表第三栏,$0代表整行。
awk的运算符
| 运算单元 | 代表意义 |
| > | 大于 |
| < | 小于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| == | 等于 |
| != | 不等于 |
查询passwd中,第三栏小于 10 以下的数据,并且仅列出账号与第三栏
$ vim /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t " $3}'结果
root:x:0:0:root:/root:/bin/bash
daemon 1
bin 2
sys 3
我们可以看到第一行没有正确的显示出来, 这是因为我们读入第一行的时候,那些变量 $1, $2... 默认还是以空白键为分隔,虽然我们定义了 FS=“:” 了, 但是却仅能在第二行后才开始生效。
我们可以利用 BEGIN 这个关键词预先设定 awk 的变数
cat /etc/passwd | awk 'BEGIN{FS=":"} $3<10 {print $1 "\t " $3}'diff
diff 主要是以『行』为单位比对
diff [-bBi] from-file to-file-b :忽略一行當中,僅有多個空白的差異(例如 "about me" 與 "about me" 視為相同 -B :忽略空白行的差異。 -i :忽略大小寫的不同。
cut
cut命令与awk命令类似,都是‘以行为一次处理的单位',而'以字段为最小的处理单位'
cut -d'分隔字元' -f fields-d :後面接分隔字元。與 -f 一起使用; -f :依據 -d 的分隔字元將一段訊息分割成為數段,用 -f 取出第幾段的意思; -c :以字元 (characters) 的單位取出固定字元區間;
获取PATH当中第三和第五个环境变量
echo ${PATH} | cut -d ':' -f 3,5
/usr/local/git/bin:/usr/local/bin同样的效果使用awk这样实现
echo ${PATH} | awk 'BEGIN{FS=":"} {print $3 ":" $5}'
/usr/local/git/bin:/usr/local/binsort排序
sort [-fbMnrtuk] [file or stdin]-f :忽略大小寫的差異,例如 A 與 a 視為編碼相同; -b :忽略最前面的空白字元部分; -M :以月份的名字來排序,例如 JAN, DEC 等等的排序方法; -n :使用『純數字』進行排序(預設是以文字型態來排序的); -r :反向排序; -u :就是 uniq ,相同的資料中,僅出現一行代表; -t :分隔符號,預設是用 [tab] 鍵來分隔; -k :以那個區間 (field) 來進行排序的意思排序的字符与语系的编码有关,因此, 如果您需要排序时,建议使用 LANG=C 来让语系统一,数据排序比较好一些
排序字母
cat /etc/passwd | sort以‘:’为分隔符,以passwd第六列‘用户目录’排序
cat /etc/passwd | sort -t ':' -k 3以‘:’为分隔符,以passwd第三列组ID排序
此处需要加上-n,否则会讲数字当做字符串排序
cat /etc/passwd | sort -t ':' -k 3 -nuniq
uniq用于去重
uniq [-ic]選項與參數: -i :忽略大小寫字元的不同; -c :進行計數
查询所有登录用户及登录次数
last | cut -d ' ' -f1 | sort | uniq -c注意:这里要记住,需要先sort排序后才能排序
例如有如下文件,想要统计各个数字出现的次数

如果执去除sort,显示结果如下

只有经过sort排序后的结果才能正常显示

wc
查询文档有多少字,多少行、多少字符
wc [-lwm] -l :列出行; -w :列出多少字(英文单字); -m :多少字元;
查询 passwd文件的行、字数、字元数
cat /etc/passwd | wc
57 73 2872查询近三个月活跃人数
lastlog -t 90 | wc -l
13xargs
很多指令不支持管线命令,我们可以通过 xargs 给该指令引入 standard input
查询所有目录名为A下的所有文件
例如,某个目录test结构如下
.test
├── 1
│ ├── A
│ │ └── file1
│ └── B
│ └── file1
└── 2
├── A
│ └── file1
└── B
└── file1
需要查询所有目录为A的目录下包含的文件,那么就可以在test的上层目录这样查询
sudo find test -maxdepth 2 -type d -name A| xargs lstest/1/A:
file1test/2/A:
file1
ls不能获取管道命令的standard input,如果没有xargs,那么ls前的输入将失效,相当于只执行了ls命令
查询包含某个字符串的所有文件
只知道字符串,想要搜素字符串所在文件,除了grep里面介绍的grep -r方法外,还可以使用find+xargs查询
sudo find 目录 -type f | xargs grep 字符串鸟哥私房菜 - 第十一章、正规表示法与文件格式化处理 (vbird.org)