NameNode怎样扩展?
首先要明确为什么要扩展NameNode,因为NameNode存储在内存中,而内存容量是有限的,当一台节点NameNode内存满了,不足以存放的时候,就需要扩展,(NameNode管理了很多文件,每个文件下又有很多数据块,数据会膨胀的很厉害,当集群大到一定程度的时候,上亿,上千百亿的时候,内存会达到瓶颈,就需要扩展)。
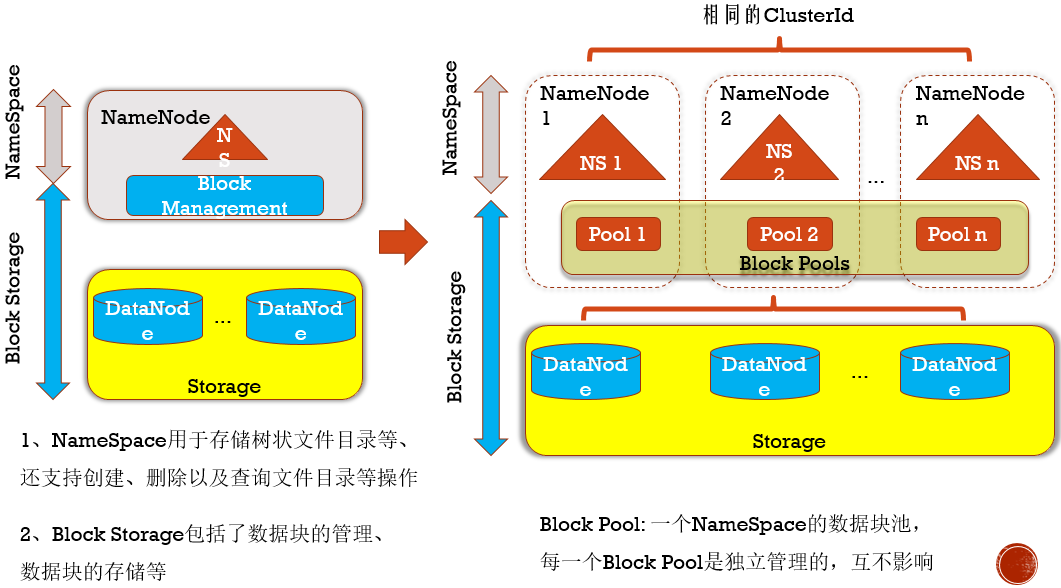
可看视频理解这个NameNode扩展图。
如何配置能达到这种多个NameNode呢?
这里简述在原有master、slave1、slave2的基础上,在slave1上添加NameNode。
- 1、添加配置hdfs-site.xml:
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>master:9999</value>
<description>这里的9999端口要和core-site.xml中的端口保持一致</description>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>slave1:9999</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>slave1:9001</value>
</property>- 2、拷贝hdfs-site.xml到slave1和slave2:
scp hdfs-site.xml hadoop-twq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp hdfs-site.xml hadoop-twq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/ - 3、修改slave1中的core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave1:9999</value>
<description>表示HDFS的基本路径</description>
</property>- 4、在slave1上执行(执行之前先关闭集群stop-dfs.sh):
hdfs namenode -format -clusterId CID-0244d161-82d1-4a98-a9b4-8f29d5ea2c80其中Cluster ID可以通过WebUI查看 - 5、启动集群start-dfs.sh,
jps查看各个节点、访问http://slave1:50070 - 6、问题
这样就造成了一个根目录有数据,一个根目录没有数据,这是我们不能接受的,就好比我要查这个集群还要记住master和slave1上的根目录,查完之后发现一个有数据,一个没数据,即:hadoop fs -ls hdfs://master:9999/和hadoop fs -ls hdfs://slave1:9999/,这样的话,客户还要记住NameNode安装在那台机器上面,这样对客户来说不是很友好,为了解决这个问题,就要引入ViewFS配置。