HA 和 Federation
HDFS 1.x 中,由于 NameNode 单点故障和内存受限,在 HDFS 2.x 中,提出了 HA 高可用来解决 NameNode 单点故障和 Federation 联邦机制解决内存受限问题。
HA
在 HDFS 1.x 中只有一个 NameNode 来管理整个集群的元数据信息,一旦 NameNode 挂掉后,整个集群将处于不可用状态,因此为了解决 NameNode 单点故障问题,在 HDFS 2.x 中使用两个 NameNode 来解决,一个 NameNode 是 active 状态,来对外提供服务,另一个 NameNode 是 standby 状态,同步主 NameNode 的元数据信息,这就是 HA (高可用)模型,一旦主 NameNode(active) 挂掉后,备用的 NameNode(standby) 就能立刻切换成主 NameNode,从而继续保证整个集群仍能继续对外提供服务。
但是主 NameNode 挂掉之后,备用的 NameNode 如何能立刻切换成主 NameNode 呢?(要保证和主 NameNode 挂掉之前的状态一样)这就是 HA 要解决的核心问题:如何使两个 NameNode 内存中的元数据信息一致。

在讨论备用 NameNode 如何同步元数据之前,我们先将 NameNode 中管理的元数据信息分成两类,一类是静态的元数据,包括目录树结构、文件大小,文件属主、权限、创建日期等,这些元数据信息是由 Client 和主 NameNode 交互产生的;另一类是动态的元数据,是由 DataNode 通过心跳机制汇报给 NameNode Block 的位置信息,NameNode 本身并不存储 Block 的位置信息(不记录到日志),只是管理。因此,备用的 NameNode 只需同步主 NameNode 的静态元数据信息,而动态的元数据信息由 DataNode 同时向两个 NameNode 通过心跳机制汇报 Block 的位置信息即可。
如何同步主 NameNode 的静态元数据信息呢?
由于主 NameNode 的静态元数据信息是由 Client 和主 NameNode 交互产生的,在 Client 和主 NameNode 发送请求时,主 NameNode 会将这些数据先写到 edits 日志中,然后再返回给 Client 执行结果,因此有以下几种同步数据的方式:
1、使用同步阻塞,主 NameNode 将数据写到 edits 中,然后和备 NameNode 建立 Socket 连接,将数据同步给备用的 NameNode,备 NameNode 执行成功后,再将结果返回给主 NameNode,主 NameNode 再将结果返回给 Client。但是这样做虽然保证了两个 NameNode 的数据一致性,但在同步数据的这段过程中,主 NameNode 一直处于阻塞状态,此时不可对外提供服务,只有等到备 NameNode 将数据同步完成后,将结果返回给 Client 之后,主 NameNode 才可以继续对外提供服务,因此破坏了可用性。
2、使用异步阻塞,主 NameNode 将数据写到 edits 中后,直接将结果返回给 Client,备 NameNode 之后再同步数据并将结果返回给主 NameNode。但是这样会使数据不一致,一旦主 NameNode 挂掉后,数据还没有同步,此时数据将不一致。
3、准备一个 JournalNode 集群,主 NameNode 将数据直接写到 JN(JournalNode)中,由 JN保存 edits 信息,standby 从 JN 中同步元数据信息。一旦主 NameNode 挂掉,只要最终 standby 从 JN 中同步完所有元数据信息,standby 就可以成为主 NameNode。注意这里 standby 是最终一致性而不是强一致性;JN 还可以用 NFS(Network FileSystem)来代替,只不过要解决 NFS 的单点故障。
active 挂掉后两种切换选择:
1、手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合。
2、自动切换:基于 Zookeeper 实现。
基于 Zookeeper 自动切换方案
ZKFC(ZooKeeper Failover Controller):监控 NameNode 健康状态,并向 Zookeeper 注册 NameNode,NameNode 挂掉后,ZKFC 为 NameNode 竞争锁,获得 ZKFC 锁的 NameNode 变为 active。
Federation
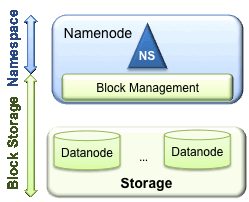
HDFS 有两个主要层:
-
命名空间(Namespace)
由目录,文件和块组成。它支持所有与命名空间相关的文件系统操作,例如创建,删除,修改和列出文件和目录。一个 NameNode 管理一个 Namespace。 -
块存储服务,包括两部分:
1、块管理(在 NameNode 中执行)
通过处理注册和定期心跳来提供 DataNode 集群中的结点数量。
管理 Block 的位置信息。
支持块相关操作,如创建,删除,修改和获取块位置。
管理副本放置,如果 Block 的副本数低于设定值,复制 Block,如果副本数多余就删除多余的块。2、存储 - 由 Datanodes 通过在本地文件系统上存储块并允许 读/写 访问来提供。

在 HDFS 1.x 中只有一个 NameNode 来管理整个 DataNode 集群的元数据信息,有可能会导致 NameNode 内存使用过高,因此,在 HDFS 2.x 中诞生了 Federation 联邦机制来解决单个 NameNode 内存受限的问题。
如上图所示,Federation 使用多个 NameNode 来共享集群中的所有 DataNode,每个 NameNode 管理一个 Namespace,一个 Namespace 对应一个块池(Block Pool),Block Pool 是同一个 Namespace 下的 Block 的集合,每个 Block Pool 都是独立管理的,DataNodes 存储集群中所有块池的块。
由以上可以得出:
元数据的存储与管理被分到了多个 NameNode 上,而真实数据的存储还是共用的。
所有 NameNode 是共享集群中所有的 DataNode 的,它们还是在同一个集群内的,也就是说它们的 Cluster ID 是一样的;但每个 NameNode 是独立的,它们都有各自的 Namespace,有各自的 Block Pool,每个 Block Pool ID是不同的。
Federation 的好处:
能把单个 NameNode 的负载分散到多个节点中,在 HDFS 数据规模较大的时候不会也降低 HDFS 的性能。
可以通过多个 Namespace/NameNode 来隔离不同类型的应用,把不同类型应用的 HDFS 元数据的存储和管理分派到不同 NameNode 中。
