原理:
生成式对抗网络(generative adversarial network, GAN)是生成模型中的一种,可以自动学习原始图像的数据分布,而不需要提前假设原始数据属于哪种分布,只是不知道参数。GAN基于博弈论场景,由生成器网络和判别器网络构成,生成器网络用来从随机噪声数据中生成近似真实数据分布的样本,供判别器网络使用;判别器网络对真实数据和由生成器网络得到的假数据进行判别;生成器网络希望自己得到的数据可以以假乱真,使得判别器网络可以判定为真,而判别器网络希望可以准确分出真实数据,使得生成器网络得到的数据判定为假,两者博弈,不断改进自己的网络,直到判别器分不出是真实数据还是假的数据为止。结构如下图所示。

目标函数:
生成器G的目的是将随机噪声z生成一个和真实数据分布差不多的真实分布
,参数
为网络的参数,我们希望找的
使得
和
类似。我们从真实数据分布中采样m个点:
,计算概率
,则m个样本的似然函数为:
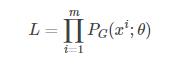
则我们的目标是找到最大化似然函数。

多减去一个常数项对结果没有影响,因此可得:

计算如下:
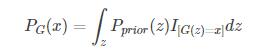

生成器G是给定先验,希望得到
,判别器D衡量
和
之间的差距,取代上述推导的最大似然估计。
定义目标函数为:
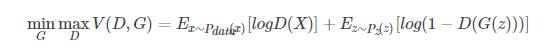
首先优化D,与生成器网络无关,G(z)相当于是假样本,第一项表示对于真实数据的判别结果,应该越接近1越好,第二项中D(G(z))表示判别器对生成器生成的数据的判别结果,应该越小越好,越接近0越好,为了统一式子,将其用1减,因此对于D来说,两者合起来越大越好;
然后优化G,与真样本无关,希望噪声数据通过生成器,然后再通过判别器后生成为1,所以D(G(z))越大越好,因此1-D(G(z))越小越好。
训练过程:

用一张图说明如下:

黑色点状线表示真实数据的分布,绿色线表示生成模型G的分布,蓝色线表示判别模型D的分布。
(a) 为初始状态;
(b) 表示先训练判别模型,保持生成模型不动,使得判别模型可以准确判断是真实数据还是噪声产生的数据
(c) 表示判别模型训练好了,保持其不动,训练生成模型,使得生成模型和真实数据的分布混淆程度更高
(d) 表示多次迭代后,判别模型已经分不出来真实数据还是生成模型产生的数据,达到要求
生成模型和判别模型是独立的,需要交替迭代训练。首先训练判别器网络:对于噪声数据,我们定义其标签为0,对于真样本,定义其标签为1,则判别器网络变为了监督二分类问题;然后训练生成器网络:因为生成器网络输出正确与否只能通过判别器网络的输出看到,因此要保证判别器网络参数不更新。对生成的假样本,我们定义它的标签为1,而判别器网络会判定它接近于0,因此产生误差,回传误差使得生成器生成的样本和真实数据非常相似;有了生成器网络,我们对之前的噪声数据生成新的假样本,此假样本和真实数据更加相似;有了新的假样本重复上述过程。
DCGAN实践:
生成器和判别器都用CNN实现,具体代码如下:
"""
This is a straightforward Python implementation of a generative adversarial network.
The code is drawn directly from the O'Reilly interactive tutorial on GANs
(https://www.oreilly.com/learning/generative-adversarial-networks-for-beginners).
A version of this model with explanatory notes is also available on GitHub
at https://github.com/jonbruner/generative-adversarial-networks.
This script requires TensorFlow and its dependencies in order to run. Please see
the readme for guidance on installing TensorFlow.
This script won't print summary statistics in the terminal during training;
track progress and see sample images in TensorBoard.
"""
import tensorflow as tf
import numpy as np
import datetime
import pdb
import matplotlib.pyplot as plt
# Load MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/")
#pdb.set_trace()
# Define the discriminator network
def discriminator(images, reuse_variables=None):
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables) as scope:
# First convolutional and pool layers
# This finds 32 different 5 x 5 pixel features
d_w1 = tf.get_variable('d_w1', [5, 5, 1, 32], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b1 = tf.get_variable('d_b1', [32], initializer=tf.constant_initializer(0))
d1 = tf.nn.conv2d(input=images, filter=d_w1, strides=[1, 1, 1, 1], padding='SAME')
d1 = d1 + d_b1
d1 = tf.nn.relu(d1)
d1 = tf.nn.avg_pool(d1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# Second convolutional and pool layers
# This finds 64 different 5 x 5 pixel features
d_w2 = tf.get_variable('d_w2', [5, 5, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b2 = tf.get_variable('d_b2', [64], initializer=tf.constant_initializer(0))
d2 = tf.nn.conv2d(input=d1, filter=d_w2, strides=[1, 1, 1, 1], padding='SAME')
d2 = d2 + d_b2
d2 = tf.nn.relu(d2)
d2 = tf.nn.avg_pool(d2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# First fully connected layer
d_w3 = tf.get_variable('d_w3', [7 * 7 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b3 = tf.get_variable('d_b3', [1024], initializer=tf.constant_initializer(0))
d3 = tf.reshape(d2, [-1, 7 * 7 * 64])
d3 = tf.matmul(d3, d_w3)
d3 = d3 + d_b3
d3 = tf.nn.relu(d3)
# Second fully connected layer
d_w4 = tf.get_variable('d_w4', [1024, 1], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b4 = tf.get_variable('d_b4', [1], initializer=tf.constant_initializer(0))
d4 = tf.matmul(d3, d_w4) + d_b4
# d4 contains unscaled values
return d4
# Define the generator network
def generator(z, batch_size, z_dim):
g_w1 = tf.get_variable('g_w1', [z_dim, 3136], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b1 = tf.get_variable('g_b1', [3136], initializer=tf.truncated_normal_initializer(stddev=0.02))
g1 = tf.matmul(z, g_w1) + g_b1
g1 = tf.reshape(g1, [-1, 56, 56, 1])
g1 = tf.contrib.layers.batch_norm(g1, epsilon=1e-5, scope='g_b1')
g1 = tf.nn.relu(g1)
# Generate 50 features
g_w2 = tf.get_variable('g_w2', [3, 3, 1, z_dim/2], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b2 = tf.get_variable('g_b2', [z_dim/2], initializer=tf.truncated_normal_initializer(stddev=0.02))
g2 = tf.nn.conv2d(g1, g_w2, strides=[1, 2, 2, 1], padding='SAME')
g2 = g2 + g_b2
g2 = tf.contrib.layers.batch_norm(g2, epsilon=1e-5, scope='g_b2')
g2 = tf.nn.relu(g2)
g2 = tf.image.resize_images(g2, [56, 56])
# Generate 25 features
g_w3 = tf.get_variable('g_w3', [3, 3, z_dim/2, z_dim/4], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b3 = tf.get_variable('g_b3', [z_dim/4], initializer=tf.truncated_normal_initializer(stddev=0.02))
g3 = tf.nn.conv2d(g2, g_w3, strides=[1, 2, 2, 1], padding='SAME')
g3 = g3 + g_b3
g3 = tf.contrib.layers.batch_norm(g3, epsilon=1e-5, scope='g_b3')
g3 = tf.nn.relu(g3)
g3 = tf.image.resize_images(g3, [56, 56])
# Final convolution with one output channel
g_w4 = tf.get_variable('g_w4', [1, 1, z_dim/4, 1], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b4 = tf.get_variable('g_b4', [1], initializer=tf.truncated_normal_initializer(stddev=0.02))
g4 = tf.nn.conv2d(g3, g_w4, strides=[1, 2, 2, 1], padding='SAME')
g4 = g4 + g_b4
g4 = tf.sigmoid(g4)
# Dimensions of g4: batch_size x 28 x 28 x 1
return g4
z_dimensions = 100
batch_size = 50
with tf.name_scope('input'):
with tf.name_scope('input_fake'):
z_placeholder = tf.placeholder(tf.float32, [None, z_dimensions], name='z_placeholder')
# z_placeholder is for feeding input noise to the generator
with tf.name_scope('input_real'):
x_placeholder = tf.placeholder(tf.float32, shape=[None, 28, 28, 1], name='x_placeholder')
# x_placeholder is for feeding input images to the discriminator
with tf.name_scope('generator'):
Gz = generator(z_placeholder, batch_size, z_dimensions)
# Gz holds the generated images
with tf.name_scope('discriminator'):
with tf.name_scope('discriminator_Dx'):
Dx = discriminator(x_placeholder)
# Dx will hold discriminator prediction probabilities
# for the real MNIST images
with tf.name_scope('discriminator_Dg'):
Dg = discriminator(Gz, reuse_variables=True)
# Dg will hold discriminator prediction probabilities for generated images
# Define losses
with tf.name_scope('loss'):
with tf.name_scope('discriminator_loss'):
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dx, labels=tf.ones_like(Dx)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, labels=tf.zeros_like(Dg)))
with tf.name_scope('generator_loss'):
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, labels=tf.ones_like(Dg)))
# Define variable lists
tvars = tf.trainable_variables() #获取网络全部可训练参数
d_vars = [var for var in tvars if 'd_' in var.name] #判别器的参数
g_vars = [var for var in tvars if 'g_' in var.name] #生成器的参数
# Define the optimizers
# Train the discriminator
with tf.name_scope('optimizers'):
with tf.name_scope('optimizers_discriminator'):
d_trainer_fake = tf.train.AdamOptimizer(0.0003).minimize(d_loss_fake, var_list=d_vars)
d_trainer_real = tf.train.AdamOptimizer(0.0003).minimize(d_loss_real, var_list=d_vars)
with tf.name_scope('optimizers_generator'):
g_trainer = tf.train.AdamOptimizer(0.0001).minimize(g_loss, var_list=g_vars)
# From this point forward, reuse variables
tf.get_variable_scope().reuse_variables()
sess = tf.Session()
# Send summary statistics to TensorBoard
tf.summary.scalar('Generator_loss', g_loss)
tf.summary.scalar('Discriminator_loss_real', d_loss_real)
tf.summary.scalar('Discriminator_loss_fake', d_loss_fake)
images_for_tensorboard = generator(z_placeholder, batch_size, z_dimensions)
tf.summary.image('Generated_images', images_for_tensorboard, 5)
merged = tf.summary.merge_all()
logdir = "tensorboard/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") + "/"
writer = tf.summary.FileWriter(logdir, sess.graph)
sess.run(tf.global_variables_initializer())
# Pre-train discriminator
#for i in range(300):
with tf.name_scope('pre-train_discriminator'):
for i in range(100):
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
real_image_batch = mnist.train.next_batch(batch_size)[0].reshape([batch_size, 28, 28, 1])
_, __, dLossReal, dLossFake = sess.run([d_trainer_real, d_trainer_fake, d_loss_real, d_loss_fake],
{x_placeholder: real_image_batch, z_placeholder: z_batch})
with tf.name_scope('Train_generator_discriminator'):
for i in range(10000):
real_image_batch = mnist.train.next_batch(batch_size)[0].reshape([batch_size, 28, 28, 1])
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
# Train discriminator on both real and fake images
_, __, dLossReal, dLossFake = sess.run([d_trainer_real, d_trainer_fake, d_loss_real, d_loss_fake],
{x_placeholder: real_image_batch, z_placeholder: z_batch})
# Train generator
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
_ = sess.run(g_trainer, feed_dict={z_placeholder: z_batch})
if i % 10 == 0:
# Update TensorBoard with summary statistics
z_batch = np.random.normal(0, 1, size=[batch_size, z_dimensions])
summary = sess.run(merged, {z_placeholder: z_batch, x_placeholder: real_image_batch})
writer.add_summary(summary, i)
if i % 100 == 0:
# Every 100 iterations, show a generated image
print("Iteration:", i, "at", datetime.datetime.now())
z_batch = np.random.normal(0, 1, size=[1, z_dimensions])
generated_images = generator(z_placeholder, 1, z_dimensions)
images = sess.run(generated_images, {z_placeholder: z_batch})
plt.imshow(images[0].reshape([28, 28]), cmap='Greys')
plt.show()
# Show discriminator's estimate
im = images[0].reshape([1, 28, 28, 1])
result = discriminator(x_placeholder)
estimate = sess.run(result, {x_placeholder: im})
print("Estimate:", estimate)
# Optionally, uncomment the following lines to update the checkpoint files attached to the tutorial.
# saver = tf.train.Saver()
# saver.save(sess, 'pretrained-model/pretrained_gan.ckpt')