GAN:生成对抗网络,首先是一个生成模型,区别与之前的辨别模型,对抗体现在生成器与辨别器之间的对抗。
生成器输入的是噪音,通过多层的MLP可以产生图片,将产生的图片和真实图片输入到辨别器,辨别器进行分辨生成的图片是否是真实的图片,如果是输出1,不是输出0。
GAN主要的优化公式:
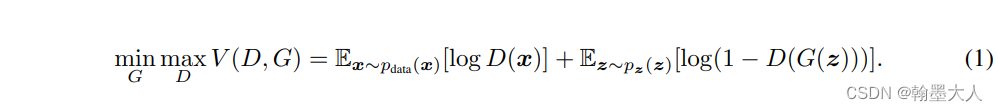
1:固定G,训练D,真实数据x希望被D分为1,生成数据z希望被D分为0。根据log函数性质,如果x被错分为0的话,那么logD(x)就会变为负无穷小。如果生成数据G(z)被错分为1的话,那个log(1-1)也是负无穷小。所以要最大化D。
2:固定D,训练G,第一项没有G,跳过,第二项生成数据G(z)目的是,最理想状态是骗过分辨器D,所以他希望D(G(z))为1,则log0为负无穷小,所以要最大化G。

看一下算法步骤,即如何进行梯度传播。我们可以看到分别对生成器和辨别器进行更新,更新辨别器时同时将真实图片和生成图片输入到辨别器,更新生成器时,将生成的图片输入进去。
1:也就是生成器输入的是噪音,经过多层感知机即linear层后,输入和真实图片大小一样的图片。
2:将真实图片和生成图片共同输入到辨别器进行损失计算。
3:生成器和辨别器各自更新,互不影响。
如何将GAN和CNN结合起来。DCGAN应运而生。
DCGAN将GAN的生成器和辨别器替换为CNN。模型生成器结构:噪声首先经过一个线性层,然后在review为图片,再经过转置卷积进行上采样。
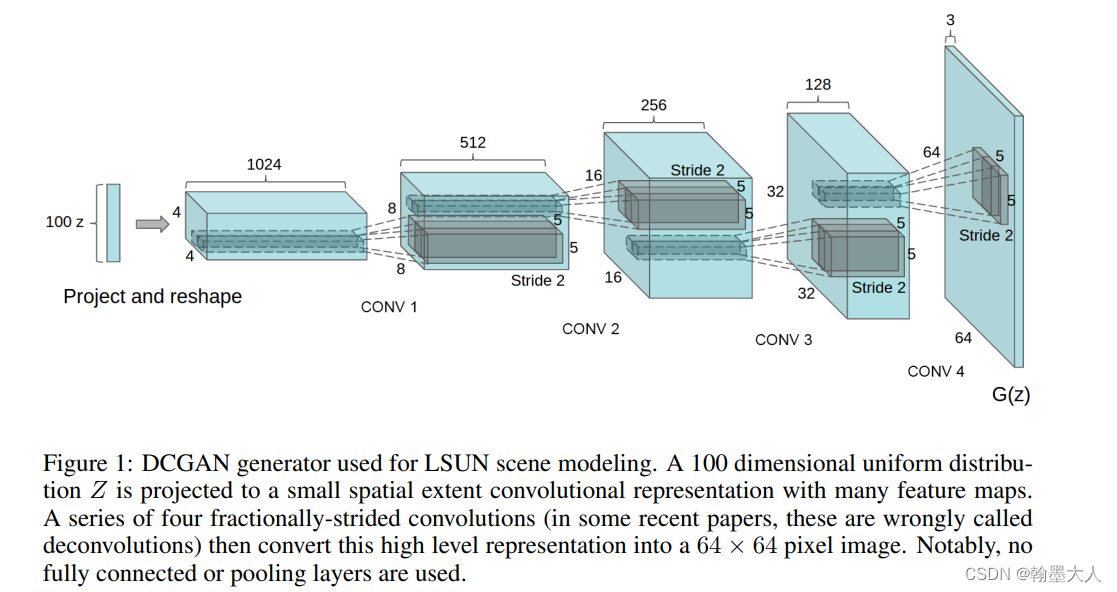
辨别器结构:因为输出的是一个概率,所以最后大小为(Batchsize,1)。生成器产生的图片输入到辨别器然后经过步长为2的卷积进行下采样,不使用池化是因为卷积可以学习如何进行下采样。最后review为2维,经过一个linear层后紧接一个sigmoid获得最终的概率。
且包括一些细节部分:

代码:参考添加链接描述
# -*- coding: utf-8 -*-
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '2'
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
# 加载数据
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
train_ds = torchvision.datasets.MNIST('/home/Projects/ZQB/a/dataset',
train=True,
transform=transform,
download=False)
dataloader = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = nn.Linear(100, 256 * 7 * 7)
self.bn1 = nn.BatchNorm1d(256 * 7 * 7)
self.deconv1 = nn.ConvTranspose2d(256, 128,
kernel_size=(3, 3),
stride=1,
padding=1
) # 得到128*7*7的图像
self.bn2 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64,
kernel_size=(4, 4),
stride=2,
padding=1 # 64*14*14
)
self.bn3 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 1,
kernel_size=(4, 4),
stride=2,
padding=1 # 1*28*28
)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.bn1(x)
x = x.view(-1, 256, 7, 7)
x = F.relu(self.deconv1(x))
x = self.bn2(x)
x = F.relu(self.deconv2(x))
x = self.bn3(x)
x = torch.tanh(self.deconv3(x))
return x
# 定义判别器
# input:1,28,28
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=2) # 第一层不适用bn 64,13,13
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2) # 128,6,6
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128 * 6 * 6, 1) # 输出一个概率值
def forward(self, x):
x = F.dropout2d(F.leaky_relu(self.conv1(x)))
x = F.dropout2d(F.leaky_relu(self.conv2(x))) # (batch, 128,6,6)
x = self.bn(x)
x = x.view(-1, 128 * 6 * 6) # (batch, 128,6,6)---> (batch, 128*6*6)
x = torch.sigmoid(self.fc(x))
return x
# 初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)
# 损失计算函数
loss_function = torch.nn.BCELoss()
# 定义优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-5)
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-4)
test_input = torch.randn(16, 100, device=device)
# 开始训练
D_loss = []
G_loss = []
# 训练循环
for epoch in range(30):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader)
# 对全部的数据集做一次迭代
for i, (img, _) in enumerate(dataloader):
img = img.to(device)
size = img.shape[0] # 返回img的第一维的大小
random_noise = torch.randn(size, 100, device=device)
d_optim.zero_grad() # 将上述步骤的梯度归零
real_output = dis(img) # 对判别器输入真实的图片,real_output是对真实图片的预测结果
d_real_loss = loss_function(real_output,torch.ones_like(real_output, device=device))
d_real_loss.backward() # 求解梯度
# 得到判别器在生成图像上的损失
gen_img = gen(random_noise)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_function(fake_output,torch.zeros_like(fake_output, device=device))
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step() # 优化
# 得到生成器的损失
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_function(fake_output,torch.ones_like(fake_output, device=device))
g_loss.backward()
g_optim.step()
torchvision.utils.save_image(gen_img,fp='/home/Projects/ZQB/a/DCGAN/DCGAN/result/result'+f"image_{
epoch}.png")
print('Epoch:', epoch)
1:最主要看一下三个损失计算:
判别器两个:真实输出,希望判别器判为1,用torch.ones_like,生成的输出即fake输出,希望判别器输出为0,用torch.zeros_like。
d_real_loss = loss_function(real_output,torch.ones_like(real_output, device=device))
d_fake_loss = loss_function(fake_output,torch.zeros_like(fake_output, device=device))
生成器一个:我们希望生成器输出的图片骗过判别器即希望判别器输出为1,torch.ones_like。
g_loss = loss_function(fake_output,torch.ones_like(fake_output, device=device))
2:生成器和判别器采用各自的优化器和各自的反向传播。
3:训练30代后将生成的结果用grid格式保存下来看一下::
epoch1:

epoch15:

epoch30:
