版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011815404/article/details/87923765
【问题形式】
- 文本(Text):长度为 n 的数组 T[1..n]
- 模式(Pattern):一个长度为 m 且 m≤n 的数组 P[1..m]
- 有效位移/匹配点(Valid Shift):0≤s≤n-m,且 T[s+1..s+m] = P[1..m],即对 1≤j≤m,有 T[s+j] = P[j],则模式 P 在文本 T 中出现且有效位移为 s,且称 s 是匹配点
匹配问题,就是找出文本中所有的匹配点。
例如:在文本 T=abcabaabcabac 中找出模式 P=abaa 的所有出现
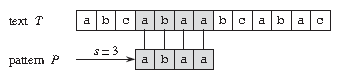
如上图,该模式在此文本中仅出现一次,在位移 s=3 处,即 s=3 是一个匹配点
【算法】
解决字符串匹配的算法有许多,包括:朴素算法(Naive Algorithm)、Rabin-Karp 算法、有限自动机算法(Finite Automation)、 KMP 算法(Knuth-Morris-Pratt Algorithm)、Boyer-Moore 算法、Simon 算法、Colussi 算法、Galil-Giancarlo 算法、Apostolico-Crochemore 算法、Horspool 算法和 Sunday 算法等等。
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)、匹配(Matching),所以算法的总时间复杂度为预处理和匹配的时间复杂度的总和。
下图为常见字符串匹配算法的时间复杂度
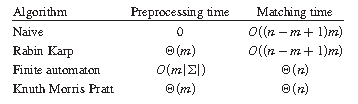
- 朴素的字符串匹配算法(Naive String Matching Algorithm):点击这里
- KMP 算法(Knuth-Morris-Pratt Algorithm):点击这里
- Boyer-Moore 字符串匹配算法:点击这里