多元线性回归,与单元线性回归相比,所比较的参数更多
附上公式: 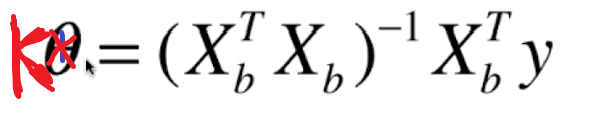
线性的表达式:y = k + k1x1 + k2x2 + k3x3 +…
x_predict:我们要预测的数据集
K:我们所求的参数k的所有元素的集合即向量
y_predict:我们所要求的预测结果
就是我们预测的结果:y_predict = x_predict.dot(K) 即两个向量的乘法,乘起来刚好是线性的表达式有不有
Jupyter Notebook
导入相应的库
import numpy as np
from sklearn import datasets //sklearn数据集
from sklearn.model_selection import train_test_split //分割训练和测试集
//这里采用波士顿房产来进行玩
boston = datasets.load_boston()
boston.keys()
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
X = boston.data
Y = boston.target
Y
X = X[Y < 50]
Y = Y[Y < 50]
X_train,X_test,Y_train,Y_test = train_test_split(X,Y)
X_train.shape
(367, 13)
多元线性回归的
此时我们应该对X_train进行一下操作,把第一列加上个全一的
X_train = np.hstack([np.ones((len(X_train),1)),X_train])
X_train.shape
(367, 14)
X_train[:10,:]
array([[1.00000e+00, 6.89900e-02, 0.00000e+00, 2.56500e+01, 0.00000e+00,
5.81000e-01, 5.87000e+00, 6.97000e+01, 2.25770e+00, 2.00000e+00,
1.88000e+02, 1.91000e+01, 3.89150e+02, 1.43700e+01],
[1.00000e+00, 6.39312e+00, 0.00000e+00, 1.81000e+01, 0.00000e+00,
5.84000e-01, 6.16200e+00, 9.74000e+01, 2.20600e+00, 2.40000e+01,
6.66000e+02, 2.02000e+01, 3.02760e+02, 2.41000e+01],
[1.00000e+00, 1.25179e+00, 0.00000e+00, 8.14000e+00, 0.00000e+00,
5.38000e-01, 5.57000e+00, 9.81000e+01, 3.79790e+00, 4.00000e+00,
3.07000e+02, 2.10000e+01, 3.76570e+02, 2.10200e+01],
[1.00000e+00, 4.52700e-02, 0.00000e+00, 1.19300e+01, 0.00000e+00,
5.73000e-01, 6.12000e+00, 7.67000e+01, 2.28750e+00, 1.00000e+00,
2.73000e+02, 2.10000e+01, 3.96900e+02, 9.08000e+00],
[1.00000e+00, 4.41700e-02, 7.00000e+01, 2.24000e+00, 0.00000e+00,
4.00000e-01, 6.87100e+00, 4.74000e+01, 7.82780e+00, 5.00000e+00,
3.58000e+02, 1.48000e+01, 3.90860e+02, 6.07000e+00],
[1.00000e+00, 9.60400e-02, 4.00000e+01, 6.41000e+00, 0.00000e+00,
4.47000e-01, 6.85400e+00, 4.28000e+01, 4.26730e+00, 4.00000e+00,
2.54000e+02, 1.76000e+01, 3.96900e+02, 2.98000e+00],
[1.00000e+00, 4.83567e+00, 0.00000e+00, 1.81000e+01, 0.00000e+00,
5.83000e-01, 5.90500e+00, 5.32000e+01, 3.15230e+00, 2.40000e+01,
6.66000e+02, 2.02000e+01, 3.88220e+02, 1.14500e+01],
[1.00000e+00, 8.37000e-02, 4.50000e+01, 3.44000e+00, 0.00000e+00,
4.37000e-01, 7.18500e+00, 3.89000e+01, 4.56670e+00, 5.00000e+00,
3.98000e+02, 1.52000e+01, 3.96900e+02, 5.39000e+00],
[1.00000e+00, 1.20830e-01, 0.00000e+00, 2.89000e+00, 0.00000e+00,
4.45000e-01, 8.06900e+00, 7.60000e+01, 3.49520e+00, 2.00000e+00,
2.76000e+02, 1.80000e+01, 3.96900e+02, 4.21000e+00],
[1.00000e+00, 1.31100e-02, 9.00000e+01, 1.22000e+00, 0.00000e+00,
4.03000e-01, 7.24900e+00, 2.19000e+01, 8.69660e+00, 5.00000e+00,
2.26000e+02, 1.79000e+01, 3.95930e+02, 4.81000e+00]])
//对应上面求K的公式
K= np.linalg.inv(X_train.T.dot(X_train)).dot(X_train.T).dot(Y_train)
coef = K[:1] #截距
coef
array([32.94768575])
传进X_test预测
X_test = np.hstack([np.ones((len(X_test),1)),X_test])
y_predict = X_test.dot(K)
//用R square来进行测试呀
from sklearn.metrics import r2_score
r2_score(Y_test,y_predict)
0.7227007236489184
至此,完成啦,兄弟。。```