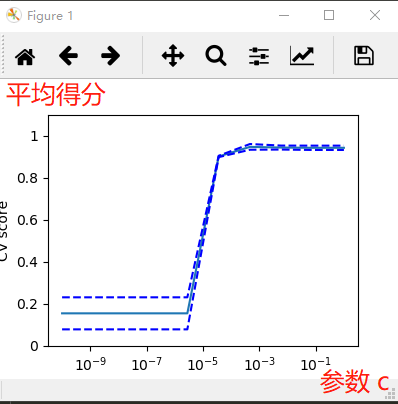
在SVM不同的惩罚参数C下的模型准确率。
import matplotlib.pyplot as plt from sklearn.model_selection import cross_val_score import numpy as np from sklearn import datasets, svm digits = datasets.load_digits() x = digits.data y = digits.target vsc = svm.SVC(kernel='linear') if __name__=='__main__': c_S = np.logspace(-10, 0, 10)#在范围内取是个对数 # print ("length", len(c_S)) scores = list() scores_std = list() for c in c_S: vsc.C = c this_scores = cross_val_score(vsc, x, y, n_jobs=4)#多线程 n_jobs,默认三次交叉验证 scores.append(np.mean(this_scores)) scores_std.append(np.std(this_scores)) plt.figure(1, figsize=(4, 3))#绘图 plt.clf() plt.semilogx(c_S, scores)#划线 plt.semilogx(c_S, np.array(scores)+np.array(scores_std), 'b--') plt.semilogx(c_S, np.array(scores)-np.array(scores_std), 'b--') locs, labels = plt.yticks() plt.yticks(locs, list(map(lambda X: "%g" % X, locs)))#阶段点 plt.ylabel('CV score') plt.xlabel('parameter C') plt.ylim(0, 1.1)#范围 plt.show()
效果: