影响模型的性能参数,主要有
1)卷积核的大小和步长
2)学习率的大小和策略
3)最优方法
4)正则化因子
5)网络深度
测试网络MobileNet, ALLconv6。测试数据集CHIM-10K,Place20
1)基础网络单元介绍:
a: ALLconv6(6的意思的5个卷积层+一个分类全连接层)

b,MobileNet
MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
MobileNet的性能和VGG16性能相当,但是计算量只有VGG16的1/10,该网络有28层卷积层,包含27个卷积层和1个全连接层,模型速度的提升方法,一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,
1)什么是depthwise convolution和pointwise convolution,
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。图2中更清晰地展示了两种操作。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
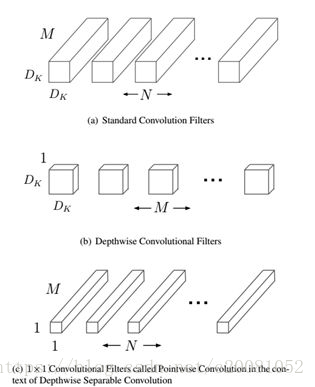
图1 Depthwise separable convolution
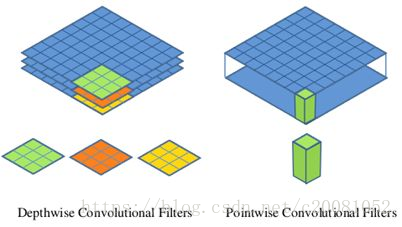
图2 Depthwise convolution和pointwise convolution
使用该卷积类型的,参数量:

前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图3所示。
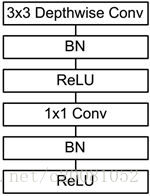
图3 加入BN和ReLU的depthwise separable convolution
2) MobileNet
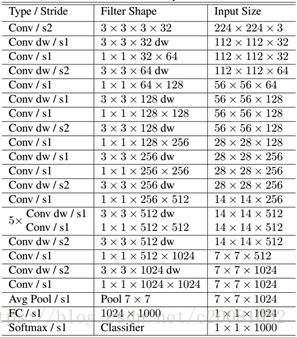
表1 MobileNet的网络结构
MobileNet的网络结构如表所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
如果单独计算depthwiseconvolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1x1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1x1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1x1卷积,除此之外还有就是全连接层占了一部分参数。
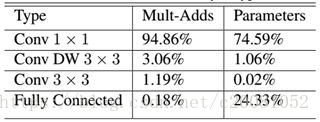
表2 MobileNet网络的计算与参数分布
MobileNet的tensorflow的实现
class MobileNet(object):
def __init__(self, inputs, num_classes=1000, is_training=True,
width_multiplier=1, scope="MobileNet"):
"""
The implement of MobileNet(ref:https://arxiv.org/abs/1704.04861)
:param inputs: 4-D Tensor of [batch_size, height, width, channels]
:param num_classes: number of classes
:param is_training: Boolean, whether or not the model is training
:param width_multiplier: float, controls the size of model
:param scope: Optional scope for variables
"""
self.inputs = inputs
self.num_classes = num_classes
self.is_training = is_training
self.width_multiplier = width_multiplier
# construct model
with tf.variable_scope(scope):
# conv1
net = conv2d(inputs, "conv_1", round(32 * width_multiplier), filter_size=3,
strides=2) # ->[N, 112, 112, 32]
net = tf.nn.relu(bacthnorm(net, "conv_1/bn", is_training=self.is_training))
net = self._depthwise_separable_conv2d(net, 64, self.width_multiplier,
"ds_conv_2") # ->[N, 112, 112, 64]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_3", downsample=True) # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_4") # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_5", downsample=True) # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_6") # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_7", downsample=True) # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_8") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_9") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_10") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_11") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_12") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_13", downsample=True) # ->[N, 7, 7, 1024]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_14") # ->[N, 7, 7, 1024]
net = avg_pool(net, 7, "avg_pool_15")
net = tf.squeeze(net, [1, 2], name="SpatialSqueeze")
self.logits = fc(net, self.num_classes, "fc_16")
self.predictions = tf.nn.softmax(self.logits)
def _depthwise_separable_conv2d(self, inputs, num_filters, width_multiplier,
scope, downsample=False):
"""depthwise separable convolution 2D function"""
num_filters = round(num_filters * width_multiplier)
strides = 2 if downsample else 1
with tf.variable_scope(scope):
# depthwise conv2d
dw_conv = depthwise_conv2d(inputs, "depthwise_conv", strides=strides)
# batchnorm
bn = bacthnorm(dw_conv, "dw_bn", is_training=self.is_training)
# relu
relu = tf.nn.relu(bn)
# pointwise conv2d (1x1)
pw_conv = conv2d(relu, "pointwise_conv", num_filters)
# bn
bn = bacthnorm(pw_conv, "pw_bn", is_training=self.is_training)
return tf.nn.relu(bn)本文简单介绍了Google提出的移动端模型MobileNet,其核心是采用了可分解的depthwise separable convolution,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小。
2)学习率的大小和策略对分类模型的影响
学习率是一个非常重要的参数,学习率的大小、策略和优化方法都会影响到模型的收敛情况。对学习率的影响,采用上述模型 ALLconv6网络进行验证;
常用的较好的学习率策略有Step和Multistep,这两个策略效果差不多。初始学习率给的太小,容易造成SGD法收敛缓慢。刚开始设置学习率最后不要太小,在有三书中初始设置0.001导致刚开始收敛效果慢且不利于优化。
3)正则化因子对分类模型的影响
正则化因子对降低模型的过拟合非常重要,什么是正则化?
a)问题引入

当预测函数的项次数过高时,算法为了降低代价,也就是差异,会跑出一条畸形的曲线。
虽然这条畸形的曲线完美的拟合了所有的数据点,但是显然这样一条曲线并不具有可推广性、泛化性。对于以后给出的数据也不能准确的预测。这种情况称为拟合过度。
一般在数据量较小,而特征值较多的情况下,过度拟合发生的概念较高。
什么是正则化?
Regularization,中文翻译过来可以称为正则化,或者是规范化。什么是规则?闭卷考试中不能查书,这就是规则,一个限制。同理,在这里,规则化就是说给损失函数加上一些限制,通过这种规则去规范他们再接下来的循环迭代中,不要自我膨胀。
为什么需要正则化?

我们首先回顾一下模型训练的过程,模型参数的训练实际上就是一个不断迭代,寻找到一个方程 来拟合数据集。然而到这里,我们只知道需要去拟合训练集,但拟合的最佳程度我们并没有讨论过。看看下面回归模型的拟合程度,看看能发现什么。
最左边的图中:拟合程度比较低,显然这样的 并不是我们想求的。连训练集的准确率如此低,那么测试集肯定也不高,也就是模型的泛化能力不高。
最右边的图中:拟合程度非常高,甚至每一个点都能通过 表达,这个
难道就是我们所渴望得到的 吗?并不是!我们的数据集中无法避免的存在着许多噪声,而在理想情况下,我们希望噪声对我们的模型训练的影响为0。而如果模型将训练集中每一个点都精准描述出来,显然包含了许许多多噪声点,在后续的测试集中得到的准确率也不高。另一方面,太过复杂的
直接导致函数形状并不平滑,而会像图中那样拐来拐去,并不能起到预测的作用,“回归”模型也丧失了其预测能力(也就是模型泛化能力),显然这也不是我们想要的。
中间的图中:展现的是最适合的拟合程度, 不过于复杂或过于简单,并且能够直观的预测函数的走向。虽然它在测试集的中准确列不及图三高,但在测试集中我们得到的准确率是最高的,同时泛化能力也是最强的。
同样,在分类模型中也存在过拟合与欠拟合的情况。

总结一下:
1,欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。
2,过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。
3,合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
欠拟合原因:
1,训练样本数量少
2,模型复杂度过低
3,参数还未收敛就停止循环
欠拟合的解决办法:
1,增加样本数量
2,增加模型参数,提高模型复杂度
3,增加循环次数
4,查看是否是学习率过高导致模型无法收敛
过拟合原因:
1,数据噪声太大
2,特征太多
3,模型太复杂
过拟合的解决办法:
1,清洗数据
2,减少模型参数,降低模型复杂度
3,增加惩罚因子(正则化),保留所有的特征,但是减少参数的大小(magnitude)。
通过分析,我们可以看出,正则化是用来防止模型过拟合而采取的手段。我们对代价函数增加一个限制条件,限制其较高次的参数大小不能过大。还是使用回归模型举例子:
正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了,因此,我们对代价函数 进行修改如下:
我们在方程中增加了两个限制条件,分别对 和
进行限制,不能让他们过高。很直观的看出,要想使
最小化,不仅仅需要
足够拟合
,同时还需要减少
和
。
这就是正则化存在的意义,能帮助我们在训练模型的过程中,防止模型过拟合。
b)怎么对模型做正则化?
我们对前面的讨论进行推广。假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。于是,我们分析 线性回归模型 的代价函数和 Logistic回归模型 的代价函数如何修改。


其中 称为正则化参数(Regularization Parameter),当参数越大,则对其惩罚(规范)的力度也就越大,越能起到规范的作用。但是要注意,
并不是越大越好的!如果选择的正则化参数 大,则会把所有的参数都最小化了,导致模型变成 ,造成欠拟合。因此,我们对
的选取需要合理即可。
c)不同的正则项
可能会有小伙伴提出疑问了,为什么正则项带了个平方呢?那我们来分析一下不同次方下的正则项。我们以一次和二次为例,正则项的图分别是一个矩形和圆形,如图:

那这有什么关系呢?我们把代价函数(包括正则项)整个画出来就知道了

可以直观的理解为,我们最小化损失函数就是求蓝圈+红圈的和的最小值,而这个值通在很多情况下是两个曲面相交的地方。
可以看到二次正则项的优势,处处可导,方便计算。

L1正则化和L2正则化在实际应用中的比较
L1在确实需要稀疏化模型的场景下,才能发挥很好的作用并且效果远胜于L2。在模型特征个数远大于训练样本数的情况下,如果我们事先知道模型的特征中只有少量相关特征(即参数值不为0),并且相关特征的个数少于训练样本数,那么L1的效果远好于L2。然而,需要注意的是,当相关特征数远大于训练样本数时,无论是L1还是L2,都无法取得很好的效果。
参考博文:
一篇文章完全搞懂正则化(Regularization)_可爱见见-CSDN博客_正则化
d)正则化因子对分类模型的影响
称为正则化参数(Regularization Parameter),当参数越大,则对其惩罚(规范)的力度也就越大,越能起到规范的作用。但是要注意,
并不是越大越好的!如果选择的正则化参数 大,则会把所有的参数都最小化了,导致模型变成 ,造成欠拟合。因此,我们对
的选取需要合理即可。
3)优化方法对分类模型的影响
优化方法主要是使用什么样的方法利用目标函数的导数通过多次求解无约束最优化的问题。不同优化方法的总结可以看考博文:
在有三的书中,使用实验的方法得到,带动量的SGD方法效果最好,其次是Nesterov,然后是经过调优的Amda,AdaGrad。
4)网络深度对分类模型的影响
a)使用ALLconv网络在数据集CHIM-10k测试深度
使用ALLconv5,ALLconv6,ALLconv7_1,ALLconv7_2ALLconv8_1,ALLconv8_2,
ALLconv8_3做测试,batch_size为16*4,使用四个GPU跑,每个上面batch_size是16;
通过有三书中的实验可以得到如下结论:
1,随着网络的加深,模型的性能会提升,不过提升的幅度会越来越小,逐渐趋近极限,可以根据分类的精度找到网络深度的极值,并不是继续加深网络性能无限提升,网络深度对模型性能的影响是有一个临界点的。
2,在网络的浅层,越使用大的分辨率越有利于提高模型的精度;