多篇论文已提出使用深层网络来定位专门类别或者未知类别的bounding box。在OverFeat中,利用全连接层来预测单个物体定位任务的box坐标。这一全连接层随后发展为检测多重特定类别物体的卷积层。Multibox方法中,从一个最后一层为用于R-CNN目标检测的全连接层,同时预测多种box的网络中生成region proposal。
卷积的计算共享也引人注意。OverFeat从图像金字塔中计算特征。Adaptively-sized pooling(SPP)和Fast-RCNN也有类似的共享特征图的做法。
在此背景下,作者提出Faster R-CNN。
RPN网络接受图片作为输入,输出一系列矩形带有objectness score的proposal。作者的最终目标是与Fast R-CNN目标检测网络共享计算,因此假设Faster R-CNN与其同有一些列卷积层。实验中使用ZF和VGG。
为了生成候选区域,在最后一层共有的卷积层上使用滑动一个小型网络。该网络与一个n*n空间窗口全连接,以特征图作为输入。每一个滑动窗口映射到1个低维向量中(对于ZF是256d,对于VGG是512d)。该向量流入到2个全连接层中,一个用于分类,一个用于边框回归。

在其他人笔记上https://blog.csdn.net/hunterlew/article/details/71075925借用的图(ZF模型):
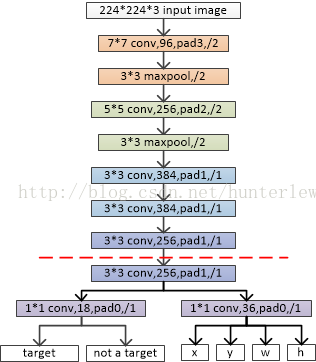
其中,虚线以上是ZF网络最后一层卷积层前的结构,虚线以下是RPN网络特有的结构。
在每个滑动窗口的位置,同时预测k个候选区域。比如每个位置有k个anchor box,那么分类层对于是否有物体的概率有2k个score,而回归层有4k个输出。作者使用3种scale,3种宽高比,k=9。如果输入特征图是W*H,则共有WHk个anchor box。对于方法中的anchor box和其相关候选区域的计算函数有一个很重要的特性,即平移不变性。
关于平移不变性见https://blog.csdn.net/voxel_grid/article/details/79275637
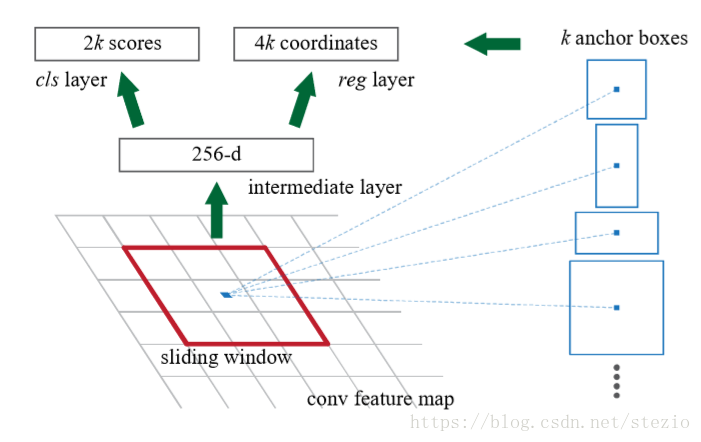
与之相比,MultiBox使用k-means方法来生成800的anchor box,并且它们不具有平移不变性,即如果转变了图像中的物体,候选区域也应该随之改变,相同的函数应该能够预测出任一位置的候选区域。而且,因为MultiBox anchor不具有尺度不变性,它需要(4+1)*800维度的输出层,然而我们的方法只需要一个(4+2)*9维度的输出层,因而参数大大减少,因此降低了在小数据集上过拟合的风险。
这里的multibox源自论文:
D.Erhan,C.Szegedy,A.Toshev,andD.Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.
C. Szegedy, S. Reed, D. Erhan, and D. Anguelov. Scalable, high-quality object detection. arXiv:1412.1441v2, 2015.
好像是比较老的方法?暂时没有去看原来的论文,因此不太了解所谓的“不具有尺度不变性”。这里吐槽一下百度,搜MultiBox出来的全是在此之后才发表的SSD论文。。。
对于Loss Function:
对每个anchor分配一个标签{1,0}。对于一个ground truth box拥有最高交并比的anchor或者与任意ground-truth box交并比都高于0.7的anchor,添加正样本标签。值得注意的是,一个ground-truth box可能指派正样本到多个anchor上。 如果一个anchor与所有ground truth box交并比低于0.3,则标为负样本。非正非负的anchor不参与训练。
Loss Function定义如下:

其中,
i为一个anchor在一个minibatch中的序号。
是anchor i是一个物体的可能性。
是ground truth 标签,1和0代表anchor的正和负。
是一个代表预测bounding box 的4参数坐标的向量。
是与一个正anchor相联系的ground truth box座标向量。
是两个类的log loss。
是回归loss,
,R为Robust Loss Function(Smooth L1)
表示回归loss只在正anchor(
)中激活
两项分别用和
归一化,加上平衡权重
在回归方面,定义4种参数如下:

x,y为box中心,w,h为宽高。x,,
分别代表predicted box,anchor box和ground truth box。这可以被认为是bounding box从一个anchor box回归到ground truth box的过程。
考虑到不同的尺寸,需要学习k个regressor,每一个对应一个大小和一个宽高比,k个regressor之间不共享权重。如此便能对固定尺寸大小的特征预测不同尺寸的box。
作者使用“image-centric”来训练网络(源自R. Girshick. Fast R-CNN. arXiv:1504.08083, 2015)。如果对所有anchor box进行损失函数计算,则会向负样本偏移因为它们占主导地位(数量多?)。因此在一个图像中随机选取256个anchor为一个minibatch,使正负anchor比例为最多至1:1。如果图像中正样本少于128,则用负样本填充这个minibatch。(这边看不懂,正样本都不足一半了还添加负样本???)
作者从均值为0,标准差为0.01的高斯分布中提取权重来初始化新的网络层,对于其他的层(共享层)按照标准惯例根据ImageNet预训练出的模型初始化。
对于RPN和Faster RCNN共享的网络,作者采取了4个步骤训练:
1) 单独训练RPN网络,网络参数由预训练模型载入;
2) 单独训练Fast-RCNN网络,将第一步RPN的输出候选区域作为检测网络的输入。具体而言,RPN输出一个候选框,通过候选框截取原图像,并将截取后的图像通过几次conv-pool,然后再通过roi-pooling和fc再输出两条支路,一条是目标分类softmax,另一条是box回归。截止到现在,两个网络并没有共享参数,只是分开训练了;
3) 再次训练RPN,此时固定网络公共部分的参数,只更新RPN独有部分的参数;
4) 那RPN的结果再次微调Fast-RCNN网络,固定网络公共部分的参数,只更新Fast-RCNN独有部分的参数。
在训练时,对于跨越了边界的anchor直接舍弃,不参与损失函数的计算。对于一张典型的1000*600的图,一般会有20k个anchor,舍弃后大概剩下6k个。然而在测试时,我们对整张图片仍使用完整的卷积RPN,对于生成的跨边境边框,加以裁剪至图片边缘。为了减少冗余,基于cls score采用非极大值抑制(NMS),设置高于阈值0.7的被剔除,大致剩下2k个proposal。实验证明,NMS不会降低检测准确率,但是实质上会减少proposal数量。NMS之后,使用top-N的proposal。
部分笔记参考于https://blog.csdn.net/hunterlew/article/details/71075925
还看到一篇写的挺好的https://blog.csdn.net/qq_17448289/article/details/52871461
这篇也挺好的 https://blog.csdn.net/WoPawn/article/details/52223282