
优势:任意给定一段区间[L,R]可以用O(1)的时间算出来
#include <iostream>
#include <string.h>
using namespace std;
typedef unsigned long long ull;
const int N = 1000010;
const int base = 131;
char str[N];
ull h[N];
int main()
{
scanf("%s",str + 1);
//算每个前缀的哈希值
int n = strlen(str + 1);
for(int i = 1;i <= n;i++)
{
h[i] = h[i - 1] * base + str[i] - 'a' + 1;
}
for(int i = 1;i <= n;i++)
{
printf("%llu\n",h[i]);
}
return 0;
}
//abc
//1
//133
//17426
算任意两段的哈希值的代码:
求某两段是不是一样的,分别求hash值判等
#include <iostream>
#include <string.h>
using namespace std;
typedef unsigned long long ull;
const int N = 1000010;
const int base = 131;
char str[N];
ull h[N],p[N];
ull get(int l,int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%s",str + 1);
//算每个前缀的哈希值
int n = strlen(str + 1);
p[0] = 1;
for(int i = 1;i <= n;i++)
{
h[i] = h[i - 1] * base + str[i] - 'a' + 1;
p[i] = p[i - 1] * base;
}
int m;
cin>>m;
while(m--)
{
int l,r;
cin>>l>>r;
cout<<get(l,r)<<endl;
}
return 0;
}
/*
abcabcabc
3
1 3
17426
4 6
17426
7 9
17426
*/
兔子与兔子

由于数据比较大,接收时选择scanf,与上面代码就这不一样。【效率快】
#include <iostream>
#include <string.h>
using namespace std;
typedef unsigned long long ull;
const int N = 1000010;
const int base = 131;
char str[N];
ull h[N],p[N];
ull get(int l,int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%s",str + 1);
//算每个前缀的哈希值
int n = strlen(str + 1);
p[0] = 1;
for(int i = 1;i <= n;i++)
{
h[i] = h[i - 1] * base + str[i] - 'a' + 1;
p[i] = p[i - 1] * base;
}
int m;
cin>>m;
while(m--)
{
int l1,r1,l2,r2;
scanf("%d %d %d %d",&l1,&r1,&l2,&r2);
if(get(l1,r1) == get(l2,r2))
puts("Yes");
else
puts("No");
}
return 0;
}
回文子串的最大长度
上海自来水来自海上
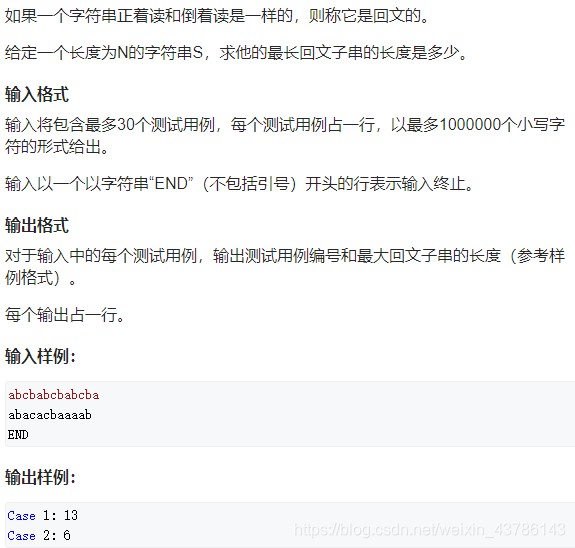
左边的正序 == 右边的逆序
首先,回文串分为两大类:长度是奇数abcba,长度是偶数abba。
①技巧
②枚举中点
③二分半径,一个长度,如果一样就扩大长度,否则缩小长度。
技巧:
abcba --> a#b#c#b#a 奇数个数
abba --> a#b#b#a 也变成奇数个数
s个字母 补上 s-1个字母 变成 2s - 1 (奇数个呗)
#include <iostream>
#include <string.h>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;
const int N = 2000010, base = 131;
char str[N];
ULL hl[N], hr[N], p[N];
ULL get(ULL h[], int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
int T = 1;
while (scanf("%s", str + 1), strcmp(str + 1, "END")) //调用这个函数,判断有没有遇到END,如果有就结束。逗号表达式,用逗号隔开的语句,返回值,只看最后一个语句的返回值 **细节**
{
int n = strlen(str + 1);
for (int i = n * 2; i > 0; i -= 2)
{
str[i] = str[i / 2];
str[i - 1] = 'z' + 1;
}
n *= 2;
p[0] = 1;
for (int i = 1, j = n; i <= n; i ++, j -- )//i,j分别是正序,逆序
{
hl[i] = hl[i - 1] * base + str[i] - 'a' + 1;
hr[i] = hr[i - 1] * base + str[j] - 'a' + 1;
p[i] = p[i - 1] * base;
}
int res = 0;
for (int i = 1; i <= n; i ++ )
{
int l = 0, r = min(i - 1, n - i);
while (l < r)
{
int mid = l + r + 1 >> 1;
if (get(hl, i - mid, i - 1) != get(hr, n - (i + mid) + 1, n - (i + 1) + 1)) r = mid - 1;//注意端点值的确定,自己举俩例子判断找的对不对
else l = mid;
}
if (str[i - l] <= 'z') res = max(res, l + 1);
else res = max(res, l);
}
printf("Case %d: %d\n", T ++, res);
}
return 0;
}
后缀数组


/*
ponoiiipoi
10 i
9 oi
8 poi
7 ipoi
6 iipoi
5 iiipoi
4 oiiipoi
3 noiiipoi
2 onoiiipoi
1 ponoiiipoi
输出字典序最小的……
输出排名为 i 的后缀与排名为 i-1 的后缀,把二者的最长公共前缀的长度记为 Height[i]
*/
#include <iostream>
#include <algorithm>
#include <string.h>
#include <limits.h>
using namespace std;
typedef unsigned long long ULL;
const int N = 300010, base = 131;
int n;
char str[N];
ULL h[N], p[N];
int sa[N];
int get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int get_max_common_prefix(int a, int b)
{
int l = 0, r = min(n - a + 1, n - b + 1);
while (l < r)
{
int mid = l + r + 1 >> 1;
if (get(a, a + mid - 1) != get(b, b + mid - 1)) r = mid - 1;
else l = mid;
}
return l;
}
bool cmp(int a, int b)
{
int l = get_max_common_prefix(a, b);
int av = a + l > n ? INT_MIN : str[a + l];
int bv = b + l > n ? INT_MIN : str[b + l];
return av < bv;
}
int main()
{
scanf("%s", str + 1);
n = strlen(str + 1);
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * base + str[i] - 'a' + 1;
p[i] = p[i - 1] * base;
sa[i] = i;
}
sort(sa + 1, sa + 1 + n, cmp);
for (int i = 1; i <= n; i ++ ) printf("%d ", sa[i] - 1);
puts("");
for (int i = 1; i <= n; i ++ )
if (i == 1) printf("0 ");
else printf("%d ", get_max_common_prefix(sa[i - 1], sa[i]));
puts("");
return 0;
}
