HDFS分布式存储系统笔记整理
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
HDFS的优点(设计思想)
1.高容错性
HDFS 认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
数据自动保存多个节点;
备份丢失后,自动恢复。
2.海量数据的存储
适合上T 级别的大文件或者一堆大数据文件的存储(不适合大量小文件的存储)
3.文件分块存储
HDFS 将一个完整的大文件平均分块(通常每块128M)存储到不同计算机上,这样读取文件可以同时从多个主机取不同区块的文件。
4.移动计算
在数据存储的地方进行计算,而不是把数据拉取到计算的地方,降低了成本,提高了性能!
5.流式数据访问
一次写入,并行读取。不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
6.可构建在廉价的机器上
通过多副本提高可靠性,提供了容错和恢复机制。HDFS 可以应用在普通PC 机上,这种机制能够让一些公司用几十台廉价的计算机就可以撑起一个大数据集群
HDFS是一个主从结构,一个HDFS集群由一个名字节点(NameNode)和多个数据节点(DataNode)组成。
NameNode
作用
- 掌控全局,管理datanode以及元数据
- 接收客户端读写服务
- 收集datanode汇报的block列表信息
- namenode保存的metadata信息包括: 文件大小,上传时间(客户端请求)权限(依据linux系统的用户系统的默认权限),blockid(namenode自己分配),block副本的位置(datanode上报),Datanode的心跳信息、文件的属主,
- 接收client的读请求返回地址
文件含义
editls :任何对文件系统数据产生的操作,都会被保存!
fsimage:文件系统元数据的一个永久性的检查点,包括数据块到文件的映射、文件的属性等
SecondaryNameNode
作用:
01、 分担namenode的负载
DataNode
1.作用
01.真实数据的存储管理
02.一次写入,多次读取(不修改)
03.文件由数据块组成,block块大小默认是128MB
04.将数据块尽量散布到各个节点
2.文件解析
blokckid:HDFS的数据块,保存具体的二进制数据
数据块的属性信息:版本信息、类型信息
3、默认的副本的个数是3,
4、备份机制
1、第一个block存储在负载不是很高的一台服务器上
2、第一个备份的block存储在与第一个block不同的机架随机一条服务器上
3、第二个备份在与第一个备份相同的机架随机一台服务器上
Client向datanode写数据的详细流程
Namenode给client一批地址以后,datanode之间会形成pipeline管道
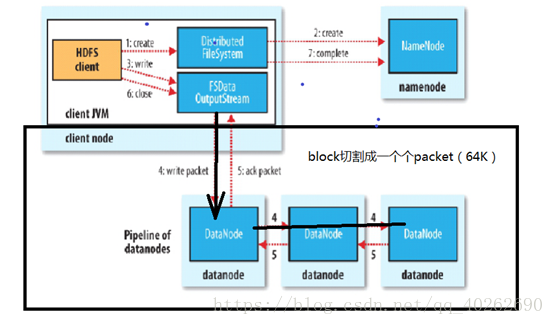
为什么node01为服务器namedate节点呢?
因为在node01节点上启动了一个namenode进程
存储在内存中的namenode数据不稳定,故需要将namedate元数据持久化到磁盘上
持久化过程:
01.SecondaryNameNode节点会定期和NameNode通信,请求其停止使用edits,暂时将新的写操作到一个新的文件edit.new上来,这个操作是瞬间完成的。
02.SecondaryNameNode从NameNode上获取到fsImage和edits文件并下载到本地目录
03.将下载下来的fsImage 和edits加载到内存中这个过程就是fsImage和edits的合并(checkpoint)
04.合并成功之后,将新的fsImage文件发送NameNode上。
05.SecondaryNamenode 会将新接收到的fsImage替换掉旧的,同时将edit.new替换edits,这样edits就会变小。
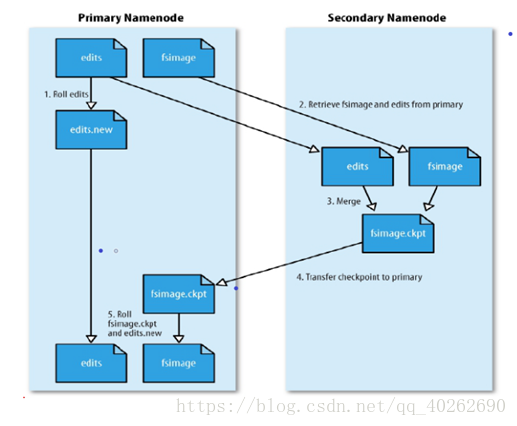
合并机制:
1、 超过3600秒,进行合并
2、 Edits文件超过64M,进行合并
注:并不是所有的元数据都会持久化,block位置信息不会被持久化,在HDFS集群启动之时,所有的datanode都会想namenode汇报当前节点的block信息
并不是Namenode不执行持久化,在服务器启动的时候,若edits里面还有数据,会进行数据持久化
安全模式:
1、 加载fismage,加载到内存中
2、 如果edits文件不为空,namenode自己合并
3、 检查datanode的健康状况
4、 若有datanode无法使用,指挥制作备份
处安全模式的过程中,不可以读取文件内容,若fsimage加载到内存中,可以查看文件目录,但是无法读取
HDFS集群不允许修改、文件一旦上传成功不能修改block块的大小,防止集群泛洪
HDFS存储流程;
1、 上传一个大文件,计算大文件的block数量,大文件大小/128M(默认)=blok个数
2、 Client向namenode汇报
(1) 当前大文件的block数
(2) 当前大文件属于谁,以及权限
(3) 上传时间
for(Block block:blocks(大文件切割出来的所有block)){
3、 client切割出来一个block
4、 请求block块的id号以及地址
5、 因为namenode能够掌控全局,管理所有的datanode,所以他会将负载不高的datanode地址返回给client
6、 Client拿地址后,找到datanode去上传数据
7、 Datanode将block存储完毕后,会向nodename汇报当前的存储情况
}