图片到视频肯定是科研发展的方向,可惜需要的资源太多,主要关注动作识别方向
未完成,主要给自己看,
Evolving Space-Time Neural Architectures for Videos
Long-Term Feature Banks for Detailed Video Understanding
[2018-NIPS]Trajectory Convolution for Action Recognition [paper]
之前的工作会把3D卷积分解成空间上的2D卷积和时间轴上的1D卷积。在时间轴上做卷积的时候一个潜在的假设是,不同帧的特征图在同一个空间位置(x,y)的语义是一样的。这是不合理的,因为有些关键的物体或物体部件会运动。所以作者引入了deformable convolution network构造了所谓的轨迹网络。有点意思的是作者又把dfn里的offsets给提出了构造了另类的two-stream架构。下图是框架图,看起来有些费劲

[201809-arxiv] OCNet: Object Context Network for Scene Parsing [paper]
这篇文章的核心思路是用non-local那一套做分割,初略地看了下好像没什么特别大的变化。不过有点意思的是把位置信息也给加进来了,个人之前认为完全放弃位置信息是non-local的一个显然缺点。后面就是配合了分割的两个主流模型PSP和deep lab的ASPP做了实验。
[2018-arxiv] D3D: Distilled 3D Networks for Video Action Recognition
思路很简单,就是希望以RGB输入作为D3D的特征输出与two stream里以flow作为输入的输出去match,具体采用的应该是L2 loss
论文猜测了为什么不直接用预测flow的loss去直接训练网络,一个原因可能是flow的loss可能会被背景像素的loss给dominate,直接去预测可能不太好训练,而利用flow作为输入的网络输出来监督可能更好。

[201812-arxiv] SlowFast Networks for Video Recognition[paper]
估计是CVPR19年的投稿吧。16年有幸听过凌海滨老师在公司的讲座,那时候对于他们用在slam的一个快慢结合的模块印象特别深,可惜悟性不高,没有学习到精髓
[2018-NIPS] A2-Nets: Double Attention Networks[paper]
这篇论文个人很难理解作者对于图1的解释,但是如果按照non-local 或者compact non-local去理解,就会比较通顺。
按照non-local的思路,作者的计算顺序是(C1*THW)*(THW*C2) * (C2*THW)。当我们把后面的先乘,那么就会发现跟non-local基本一样的。只是作者采用了跟compact non-local一样的计算顺序以减少计算量。另外不同的地方是作者对(THW*C2)和(C2*THW)都做了softmax,以符合attention的假设。
不理解的地方还是作者对图1的解释,作者把(C1*THW)*(THW*C2)作为一种全局描述子,但是自己能理解的是C1和C2之间的相关性。有待继续理解

[2018-NIPS] Compact Generalized Non-local Network [paper] [code]
这个工作把non-local推广到了c维度,这样做主要是可以建模不同通道之间任意位置上的关系,但是问题也比较严重,由于模型中c一般都比较大,计算量大大增加,所以作者主要采用了两种思路。第一种比较简单,就是c分成g组,复杂度一下子降低g倍。另外,在计算(CTHW*1)*(1*CTHW)*(CTHW*1)时,如果按照正常的计算顺序是O(CTHW*CTHW)+O(CTHW*CTHW),但是如果先计算后两项,复杂度是O(CTHW)+O (CTHW). 另外如果是RBF的核,利用泰勒展开拟合。
[2018-NIPS] Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks [paper][code]
看模型比论文容易理解, 跟SE同一个作者,思路也是一脉相承

[2018-CVPR] Squeeze-and-Excitation Networks [paper][code]
这篇论文虽然不是主要做video的,但是有些论文跟这个有些关系,因此也放进来了。主要是要在channel上做attention,每一个channel都会学习一个标量去scale原始的特征,这个值跟这个通道上h*w的特征有关,可以看成一种比较简单的gather-exite形式。 只在channel上做了attention,并且global pooling这个操作建模的想象力不太够。

[2018-CVPR] MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition [paper]

[2018-CVPR] A Closer Look at Spatiotemporal Convolutions for Action Recognition [paper]
经验: 底层捕捉temporal或者运动信息,高层捕捉空间信息
这个经验有点反直觉,另外跟其他一些论文的做法也有矛盾的地方
论文本质上好像跟P3D没啥区别,但是效果要比P3D好很多,原因在哪?(还未理解)
[2018-CVPR ] Compressed Video Action Recognition [paper]
利用PI帧做动作识别
1 知识点 I帧是关键帧,P帧是类似于补偿帧或变化帧,还有零个或多个b帧(双向变化帧),最后还有个残差帧
I-frames are regular images and compressed as such. P-frames reference the previous frames and encode only the ‘change’.
2 由于P帧有可能依赖于P帧,所以作者把变化全部累加起来,让P帧只依赖于I帧

3 最后训练一个模型

问题:如果一个视频有多个I帧,那么怎么处理?
[2018-arxiv] Temporal Shift Module for Efficient Video Understanding [paper]
韩老师怎么进军视频领域了, 这篇文章简单有趣

[2018-ECCV] ECO: Efficient Convolutional Network for Online Video Understanding [paper][code]
这么直观的想法为什么到18年才被人发现,可能我错过了一些细节。不过这里N也是固定的,固定的N感觉还是有些遗憾的

[2018-CVPR] Non-local Neural Networks [paper][code]
其实我对该论文的做法是抱保留态度的,虽然他的出发点我是十分赞同的。该工作主要是想利用空间和时间上全局的信息来辅助视频或图片上的理解任务,这个是很合理的出发点,所以像作者提到之前的global mean什么的方法(虽然我没看),或者是分割里面比较新的论文Context Encoding for Semantic Segmentation加个全局分类损失,我都非常理解。但是作者采用是这么一个策略,以图片为例,如果是传统的方法,对于一个特征图,每个像素点的值都是卷积堆叠的结果,获取的信息跟感受野有关,因此称之为local也是合理的。作者想为每个点增加全局信息,采用的其实就是一个有权重的累加,计算的公式跟全局的卷积有点小类似,如下面的公式,x是特征图,i,j等就是坐标,f是相似性的函数,g是一个转化,比如1*1的卷积,学术上称之为embedding,
权重是两个特征值的相似性。两个点的特征越相似,那么权重越大,如下面的公式。但是这样就完全抛弃空间或时间的关系,这是很不合理的,如果两个像素点的特征相似但是隔的很远,他们的关系会有那么强么?
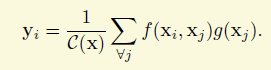
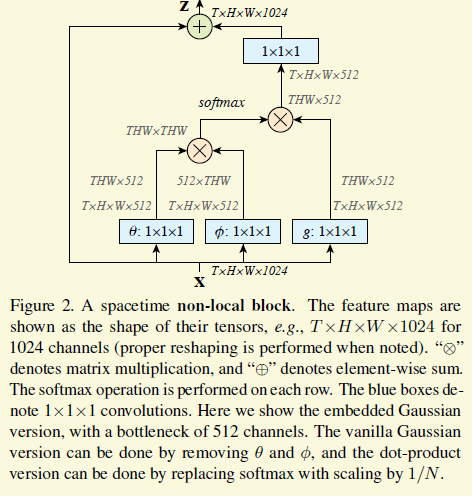
接下来作者就把这个公式完美地用一个新的cnn building block实现了出来。首先需要定义上面的g和h. g论文里就用1*1的卷积了,f是一个embeded guassian,如下图,不难理解

最后就成了这样,θ和φ就是f里面的embedding,特征用512维表示,减少计算,下图最左边的矩阵乘法就是上面公式3的右上部分,softmax把公式3的指数跟归一化包办了,还是比较优美的。
[201712-arxiv] On the Integration of Optical Flow and Action Recognition [paper]
这篇论文做了几组对照试验来探索到底是什么原因使得光流能提高动作识别的性能。前两组试验还挺有意思的,shuffle flow性能降的不是特别多(是不是由于现在的数据库时间很短,flow都类似),shuffle image性能降的特别多

[2017-ICCV] Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks [paper][code]
P3D
[2017-CVPR ] Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset [paper][code]
I3D
[2016-ECCV] Temporal segment networks for action recognition in videos[paper]
看文章都不理解Consensus到底是个什么函数也是醉了,平均还是什么

[2014-NIPS]Two-Stream Convolutional Networks for Action Recognition in Videos[paper]
two-stream