本文分为两个部分:基础知识和正文,其中基础知识包括什么正则表达式以及Beautifulsoup4的使用。
一、正则表达式
正则表达式用于字符串查找、合法性检查以及作为程序员的工具箱使用。
字符串查找:例如在文本中查找一个子字符串‘python’,或者在一串HTML代码中查找URL地址
合法性检查:例如检查在网站上输入的邮箱地址是否正确
程序员的工具箱:正则表达式模式匹配的起源是Unix的命令grep,它会打印出和给定正则表达式批评为的所有输入行
正则表达式含有三种基本操作:
1.连接操作:例如AB,指定语言{AB}表明这是一个由两个字符组成的字符串,由A和B连接而成
2.或操作:用‘|’表示这个操作,表明指定多种可能的匹配,例如:‘A|B|C’,指定语言{A,B,C},连接操作优先于或操作
3.闭包操作:用‘*’表示这个操作,表明前面的字符重复任意次,例如A*B指定的语言由一个A和0个或多个B的字符串,闭包操作优先于连接操作
总的来说,闭包操作>连接操作>或操作,使用括号‘()’可以改变默认的优先级顺序,例如A(AC|BD)D指定语言是{CACD,CBD}.
使用正则表达式的缩略写法,可以使表达式更加简洁,小巧
1.字符集描述符
‘.’点是一个能够表示任意字符的通配符,例如:A.B表明A连接任意字符再连接B
‘^’表示任意非该括号内的字符,例如:[^AEIOU]
‘-’指定范围,例如[A-Z],表明匹配所有大写的26个字母
2.闭包简写
‘+’表示至少复制一次
‘?’表示重复0次或1次
‘{}’花括号内的数字可以指定任意重复的次数,例如:[0-9]{3}匹配任意三位数
3.转义序列
‘\\’表示‘\’
‘\n’表示换行符
‘\t’表示制表符
‘\s’表示任意空白字符
4.预定义字符集
‘\d’ 数字[0-9]
‘\D’ 非数字[^\d]
'\s'空白字符[\t\r\n\f\v]
'\S'非空白字符[^\s]
'\w'单词字符[a-zA-Z0-9]
'\W'非单词字符[^\w]
问答:正则表达式中'[]'和'()'分别表示什么意思?答:[]匹配的是一个字符,()匹配的是一串字符
二、BeautifulSoup4
写来写去还是上一份中文文档最好
三、分析网易云音乐歌单页面源代码
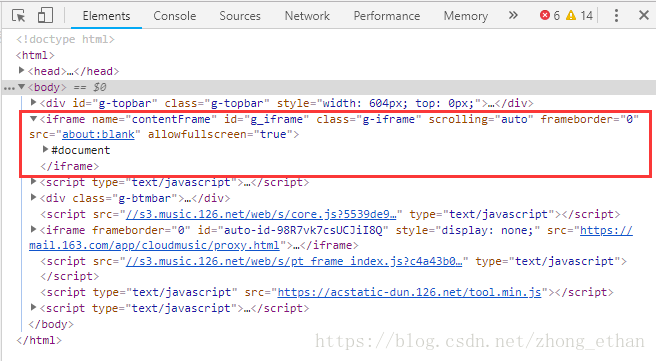
由于我们想要的列表信息在<iframe>内联框架中,使用urllib3或者requests无法爬取到内联框架的内容,因此我们使用selenium获取<iframe>框架的内容
from selenium import webdriver
from bs4 import BeautifulSoup
path='/User/nakau/Download/chromedriver'
url='https://music.163.com/#/playlist?id=90771773'
driver=webdriver.Chrome(path)
driver.get(url)
driver.switch_to.frame('g_frame')
# 如果报错missing value值,则将Chrome与Chromedriver更新到最新
soup=BeautifulSoup(driver.page_source, 'lxml')在爬取的页面右击可以查看网页框架源代码,分析发现,只要将原URL中的‘/#’去掉,就可以爬取到<iframe>框架的内容,然而此种方式只能得到歌曲名称列表,无法得到完整的HTML内容
from bs4 import BeautifulSoup
import requests
url='https://music.163.com/#/playlist?id=90771773'
url=url.replace('/#','')
html=requests.get(url)
soup=BeautifulSoup(html,'lxml')通过比较,发现使用requests的包解析速度比selenium快很多。
得到soup后我们就可以开心的我们想要的任何内容了
# 以下使用selenium方式获取到的soup
import re
# 获取用户名
string=soup.title.string
obj=re.compile('.*喜欢的音乐')
username=obj.findall(string)[0] #obj.findall 获取到的是一个list,此处获取list中的元素值
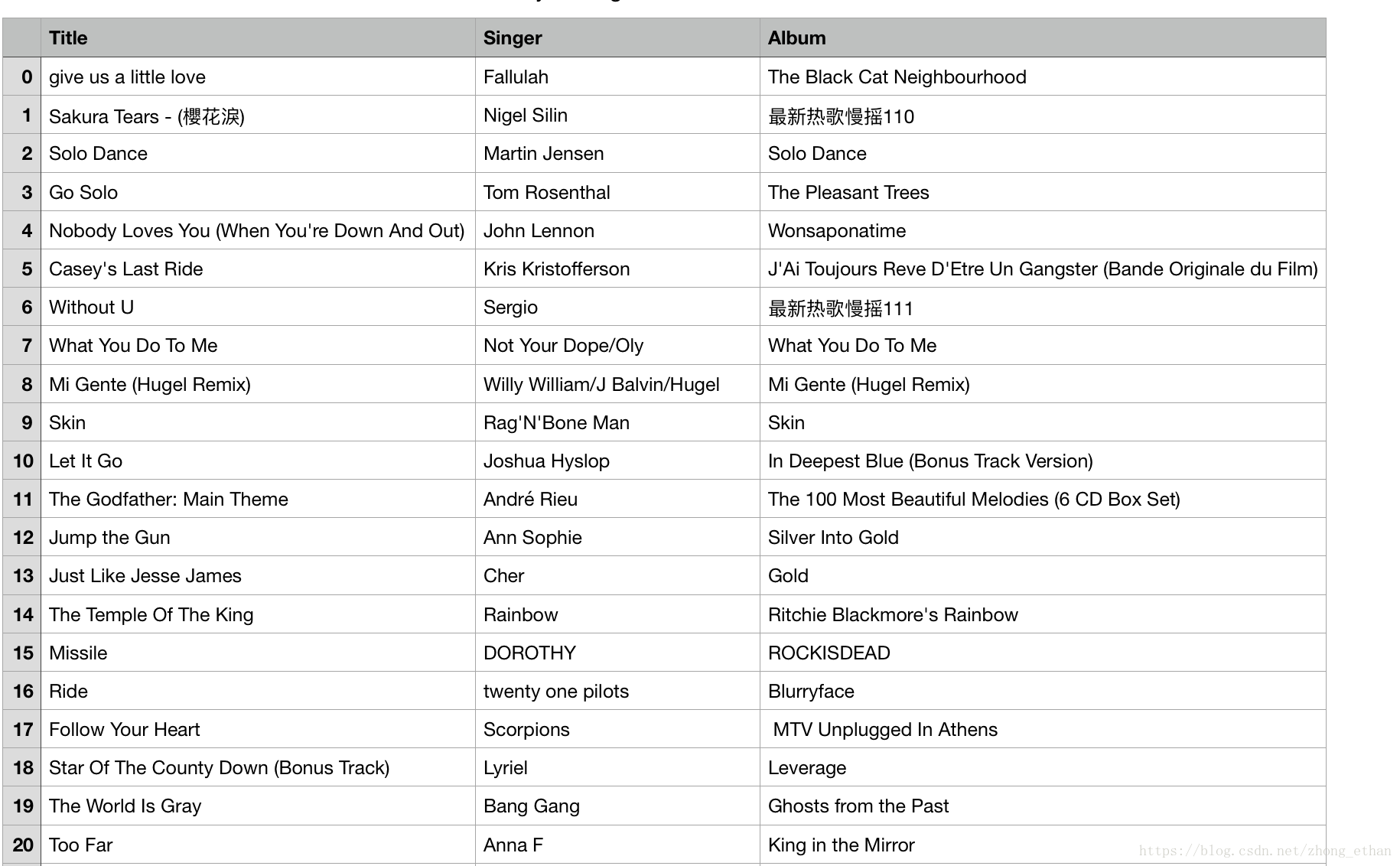
# 获取歌单列表包含歌曲名称,歌曲作者,歌曲专辑
trlist=soup.tbody.find_all('tr')
songlist=[]
for each in trlist:
aux=[]
aux.append(each.find('b')['title'].replace('\xa0',' ')
temp=each.find_all('div','text')
aux.append(temp[0].span['title'].replace('\xa0',' ')
aux.append(temp[1].a['title'].replace('\xa0',' ')
songlist.append(aux)
#导出为CSV文件
songlist.to_csv('%s.csv' % username)至此,我们可以得到一份如下的歌单列表