python爬取喜马拉雅FM音频文件喜马拉雅一说春秋随便从喜马拉雅网站找的
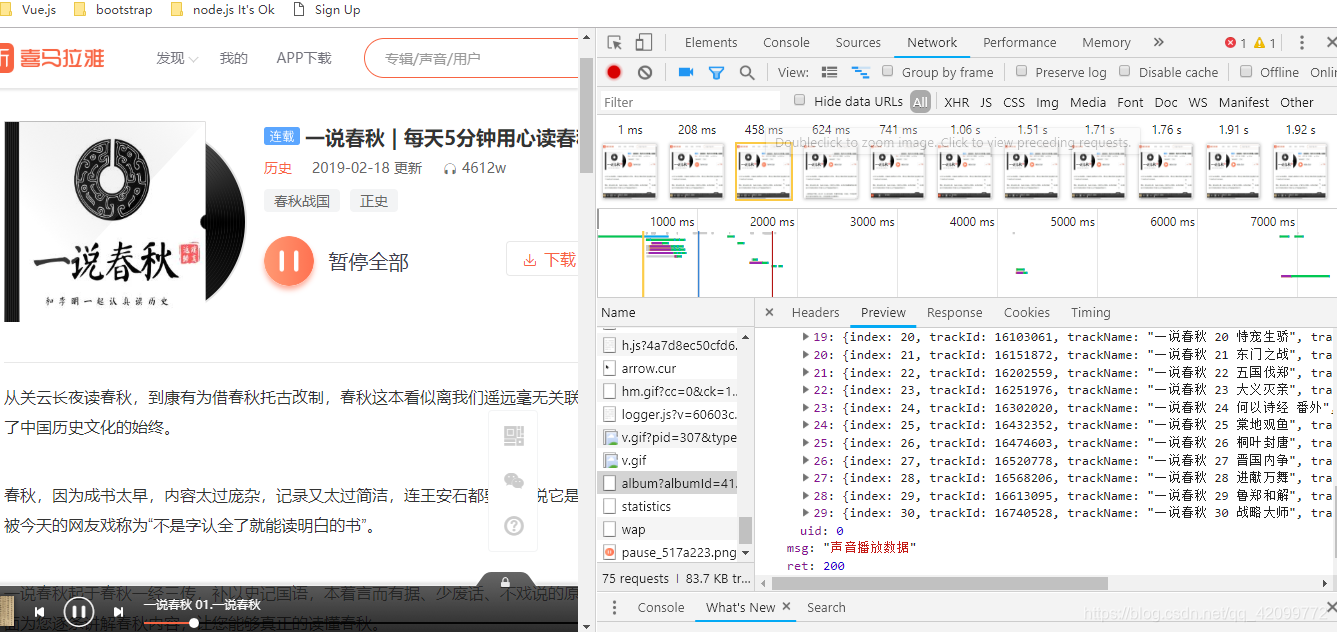
此时打开开发者选项,点开network查看你会发现并没有存放json文件也就找不到音频文件,此时你打开音频开关,点击播放全部你会发现多了一个album开头的你打开之后就会发现这个文件就是存放音频文件的json文件。
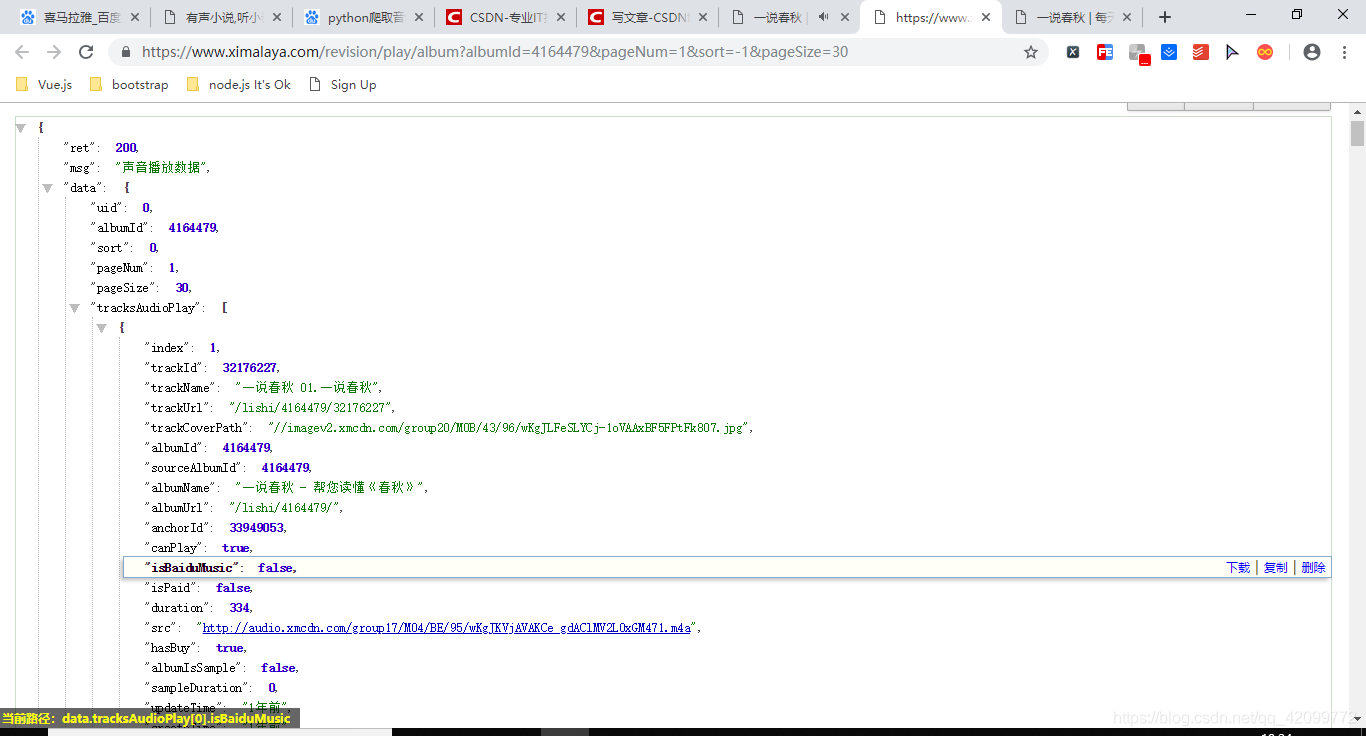
这时候你会发现里面的src是一个m4a的链接,打开之后就会发现这就是我们要找的音频文件,下面这是代码。
import requests
import json
import jsonpath
index=1
for i in range(1,26):
jsonUrl='https://www.ximalaya.com/revision/play/album?albumId=4164479&pageNum=%d&sort=-1&pageSize=60'%i
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}#设置请求头
# url='https://www.ximalaya.com/revision/play/album?albumId=4164479&pageNum=1&sort=-1&pageSize=60'
response=requests.get(jsonUrl,headers=header)
response.encoding='utf-8'
html=response.text
html=json.loads(html)
# print(html)
m4a=jsonpath.jsonpath(html,'$..src')# print(m4a)
count=(index-1)*30+1
index=index+1
for i in m4a:
root='E:/python/'
path=i.split('/')[-1]
with open(root+path,'wb') as f:
r=requests.get(i)
f.write(r.content)
print('第'+str(count)+'条数据')
count=count+1
print('爬取成功')
# print()
注意事项
- 首先开始爬取时,先获取所有的json数据,看能不能爬取成功,可是怎么输出
response.text都显示空,纠结了后就也搜,突然想到自己语法没有错误。应该能输出的,这时想到应该,设置一个请求头,这可能是被对方发现是爬虫,被限制了。header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}于是设置了请求头这次json文件就全部显示了,任你处理了。- 翻页就是看url的规律,发现https://www.ximalaya.com/revision/play/album?albumId=4164479&pageNum=1&sort=-1&pageSize=30 这里改变pageNum=2再次请求,发现是从31开始的,那么pageNum控制是哪一页,查看页数到25页,于是利用for循环,再请求循环的每一个url,就能请求每一页了。
- 像图片,视频,音频存在文件中都是以二进制形式存储的。r.content就是变为二进制的形式,而r.text时Unicode的形式,这是运行,一会你就会发现E盘装不下了。