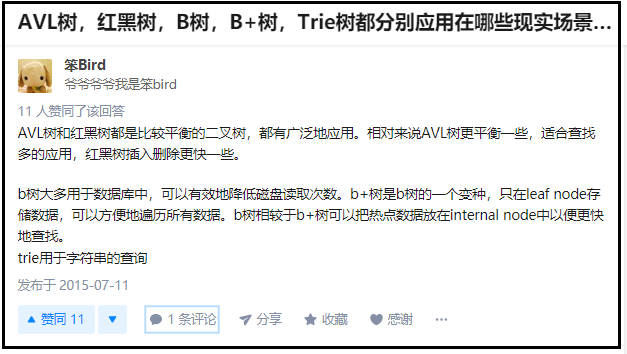
很重要。

1. 很多逻辑结构就是树,比如文件目录
2. 树具有递归性,许多算法都是递归完成的。(递归到左/右子树,并以抵达叶子节点为递归终止条件)
3. “查找树”的应用:
不是:因为数据本身的逻辑结构是这样!
而仅仅:是一种组织数据、便于高效查找/增加/删除(O(lgn)复杂度)的方式。
根据具体的情况 (如:查找的次数远大于增删的次数 ; 数据量很大,需要多次从磁盘读取数据到内存),去选用合适的查找树。
扫描二维码关注公众号,回复:
5243276 查看本文章

二叉查找树(Binary Search Tree):
主要是用树结构来保存排序好的数据,使得查找/增加/删除 (定位到一个数据)时自然符合“二分查找”, 其时间复杂度为 O(lgn)
● 一般的二叉查找树(BST)
弊端: 左右子树不平衡,可能一些深度比较深,而查找的效率正比于树的深度
平衡的二叉查找树: 维基百科:平衡树
● AVL 树:
实现:在每次插入/删除节点后进行banlance()调整,保持任一节点的左右子树的深度差不超过1
● 伸展树(Splay Tree):
使得经常查找的结点深度较小,从而降低均摊复杂度。
在均摊O(log n)的时间内完成基于伸展(Splay)操作的插入、查找、修改和删除操作 (注意:即使是查找,也会引起树结构的调整)
● 红黑树 (Red Black Tree)
二叉的限制太强,数据量很大时树的深度势必仍然过高。 所以引入B树,由于可以组织的数据量变大、可以减少IO读取。