from selenium import webdriver
import unittest,time
class my_test(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.url = "这里是url"
def test_1(self):
self.driver.get(self.url)
pageensi = self.driver.page_source#这里是爬页面源码的函数
print(pageensi)
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
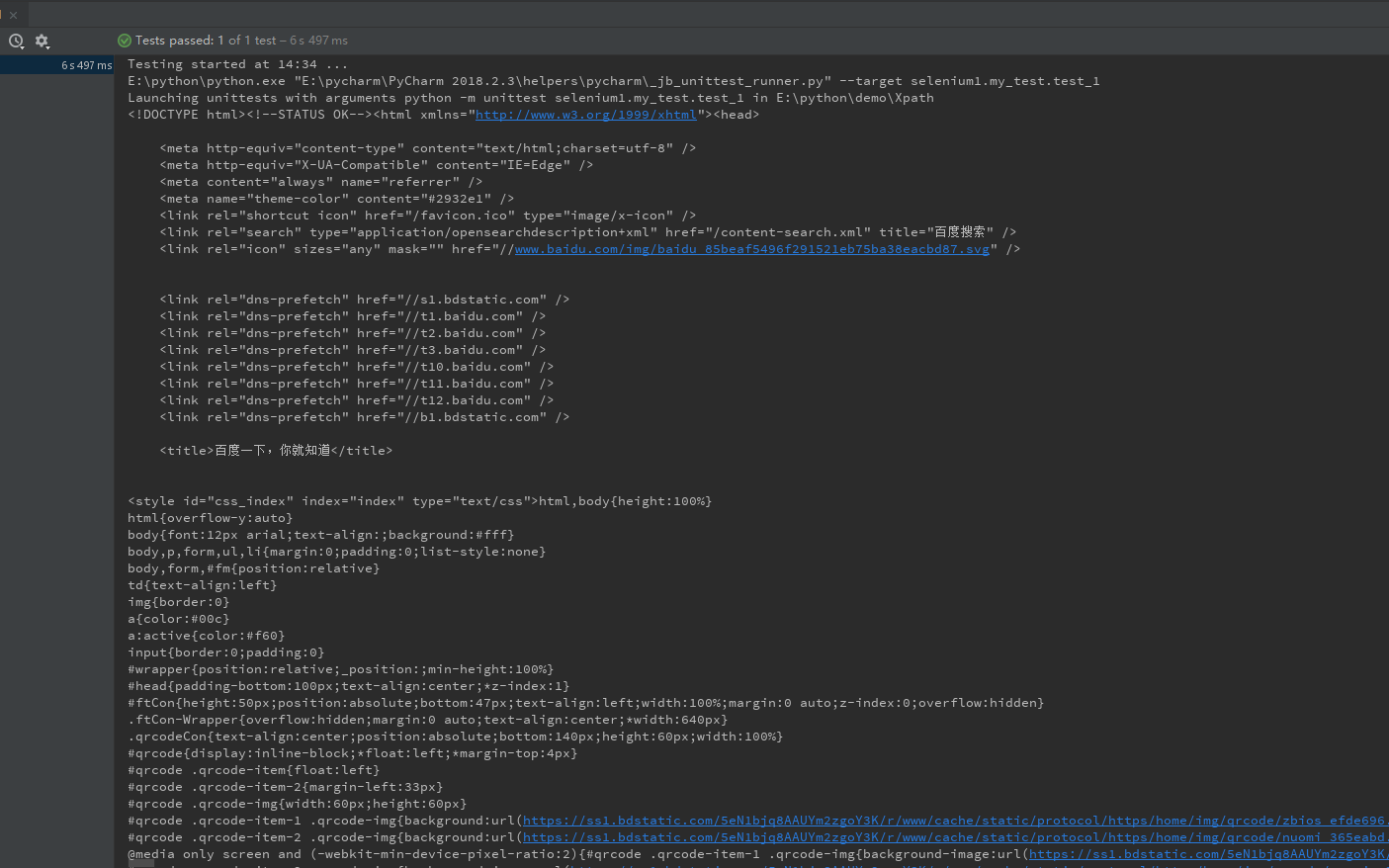
比如爬百度首页的源码,可以把上述代码的url地址换成https://www.baiducom;
再进行执行就可以了。
下图是执行结果