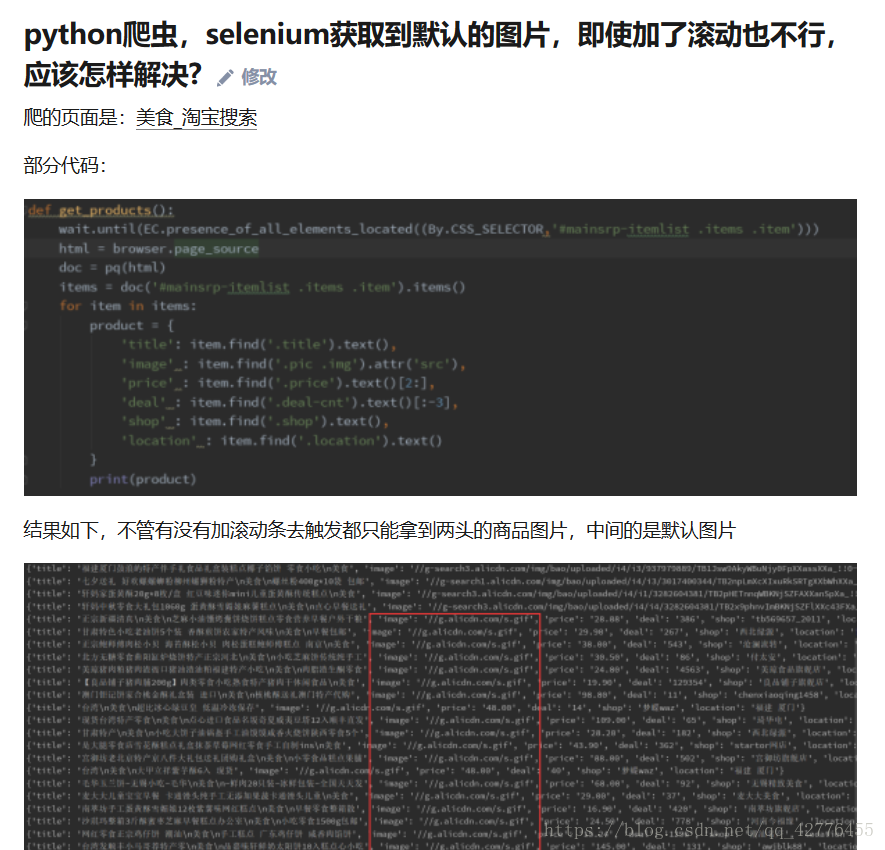
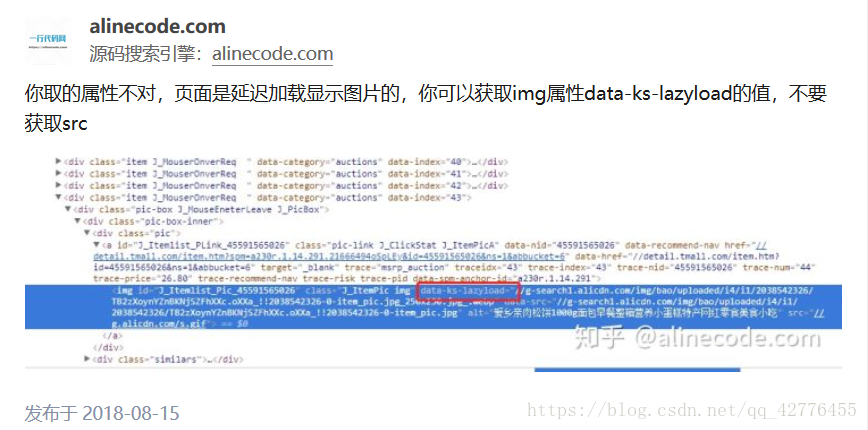
版权声明:请多指教。 https://blog.csdn.net/qq_42776455/article/details/81808640
自动化测试工具selenium的使用
教材参考:《Python 3网络爬虫开发实战》崔庆才。需要资料的同学评论私聊获取。
用selenium获取淘宝美食信息
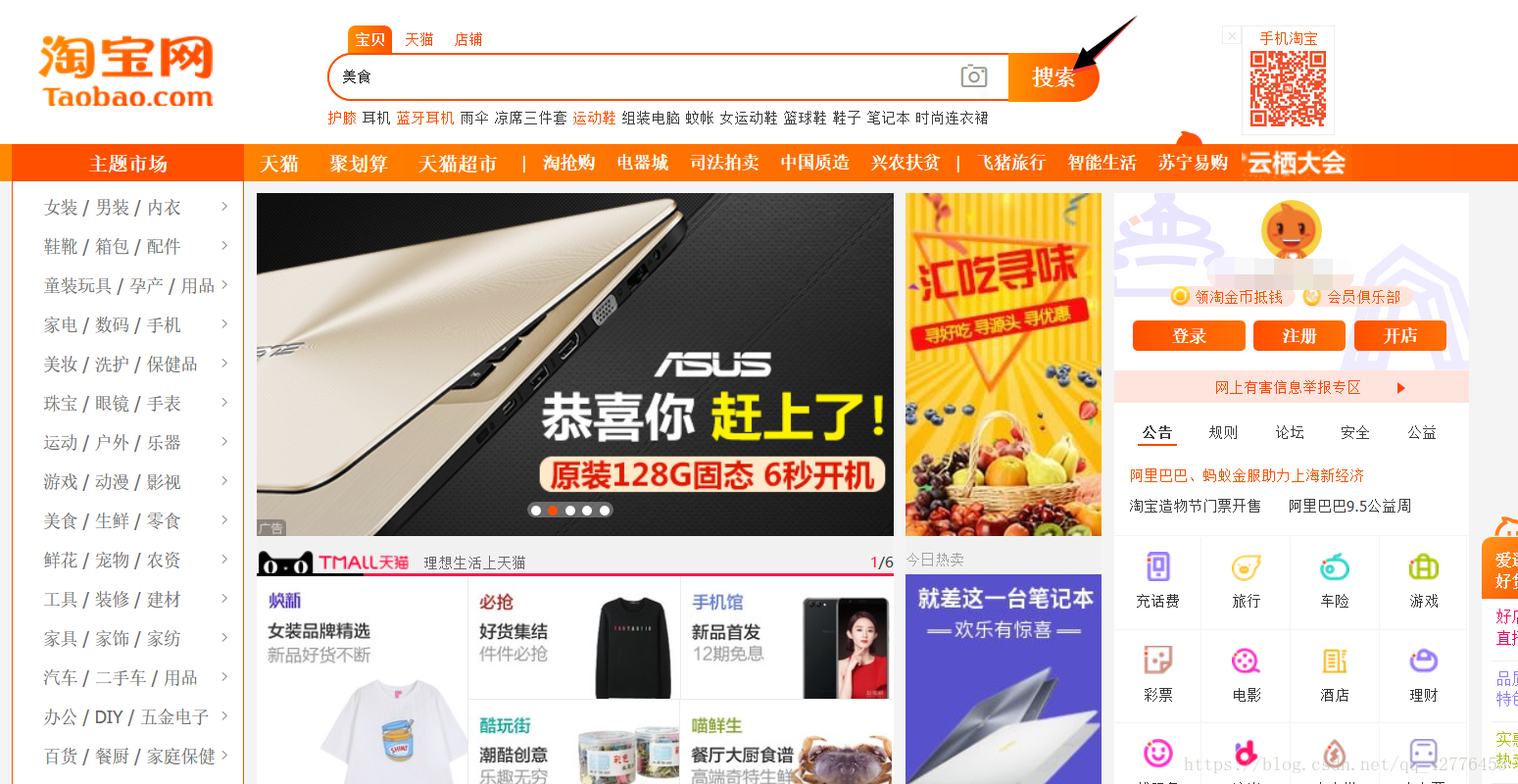
搜索美食信息
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from config import *
from pyquery import PyQuery as pq
import pymongo
import time
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
def search():
try:
browser.get('https://www.taobao.com')
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
input.clear()
input.send_keys('美食')
submit.click()
total = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))[0]
#print(total,total.text)
return total.text
except TimeoutError:
return search()自动翻页处理
def next_page(page_num):`这里写代码片`
try:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page_num)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_num)))
get_products(page_num)
except TimeoutError:
next_page(page_num)获取产品信息并保存到mongodb
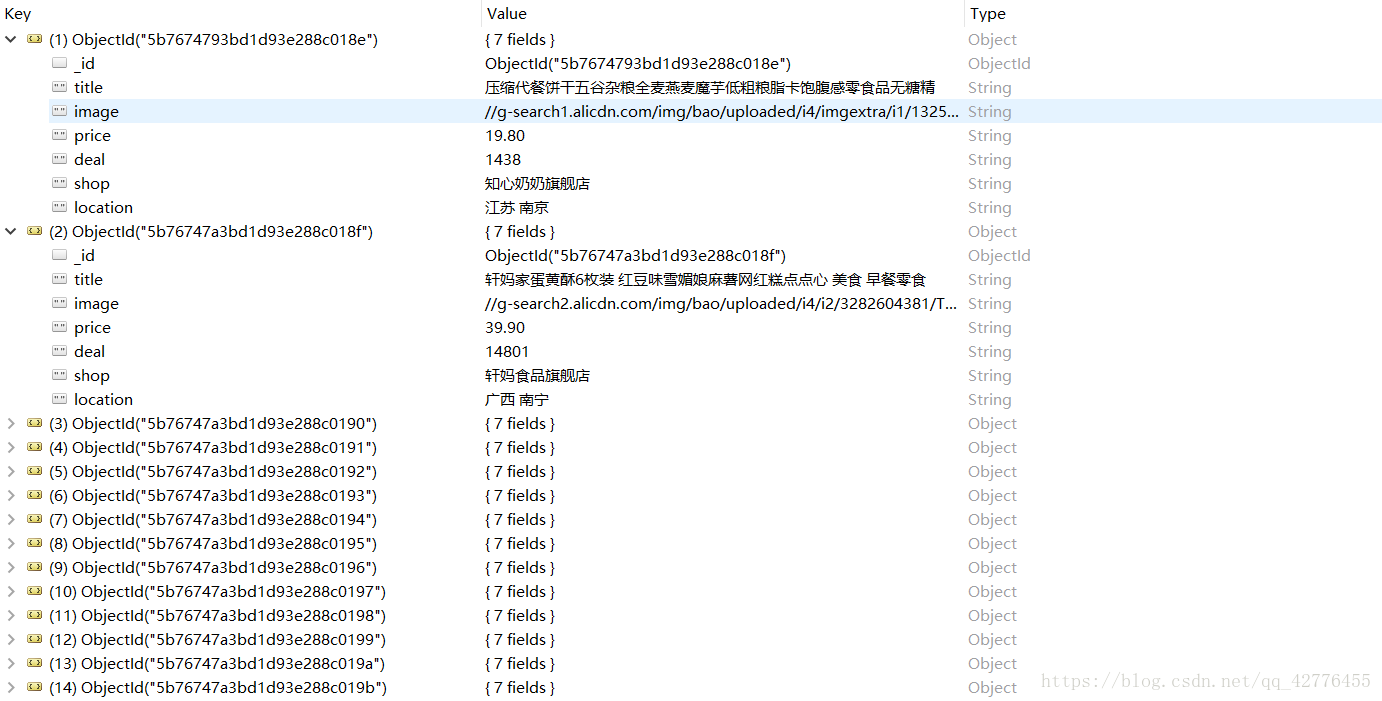
获取美食信息包括(商家,商品,销售量,简介,商铺名)
def get_products(page_num):
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'title': item.find('.title').text(),
'image' : item.find('.pic .img').attr('data-src'),
'price' : item.find('.price').text()[2:],
'deal' : item.find('.deal-cnt').text()[:-3],
'shop' : item.find('.shop').text(),
'location' : item.find('.location').text()
}
save_to_mongo(product)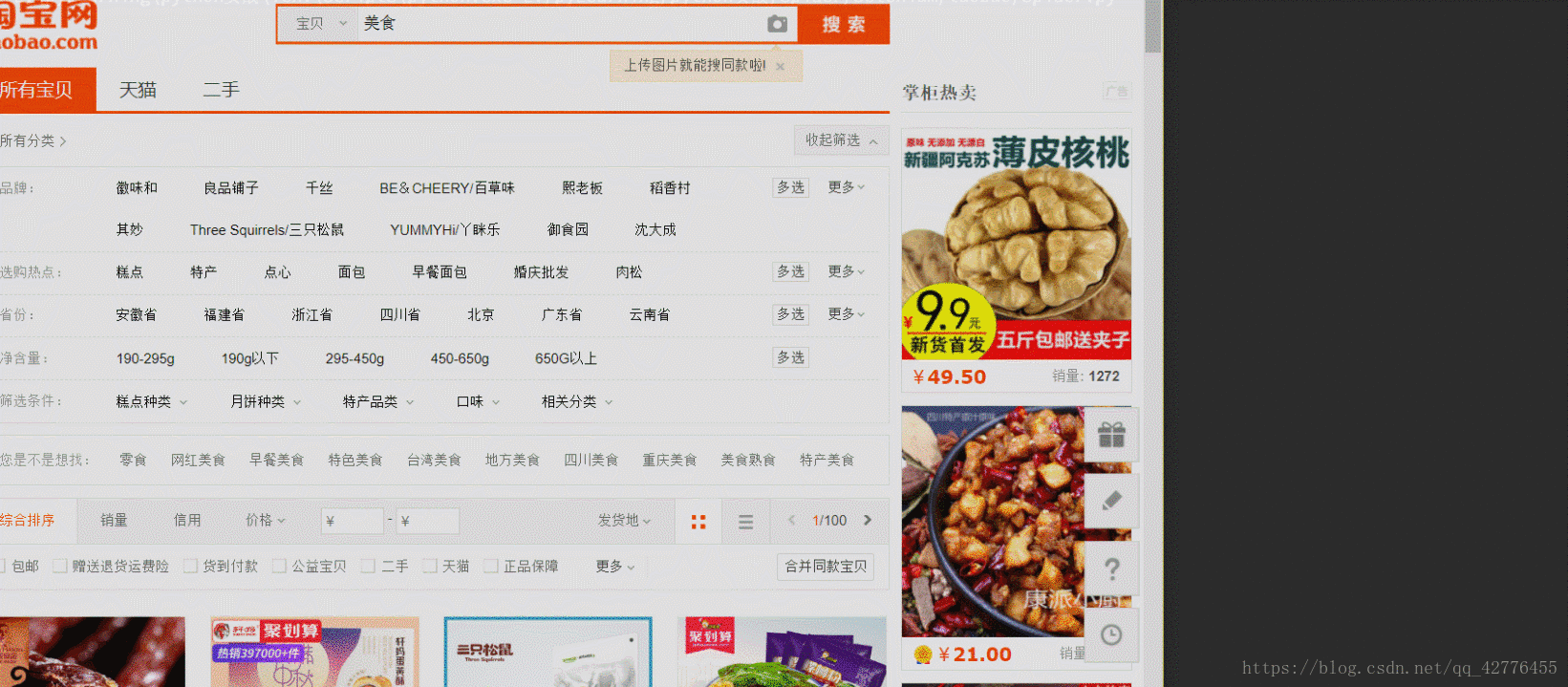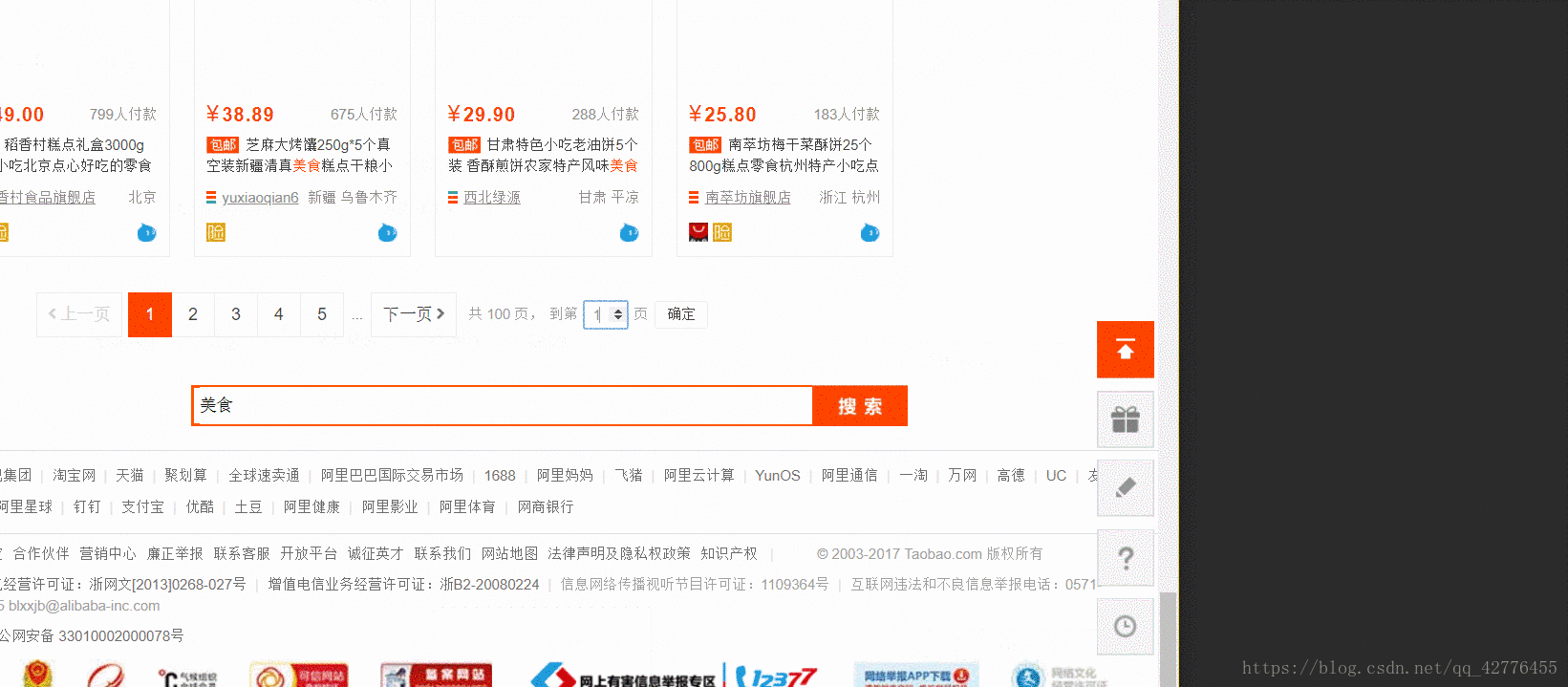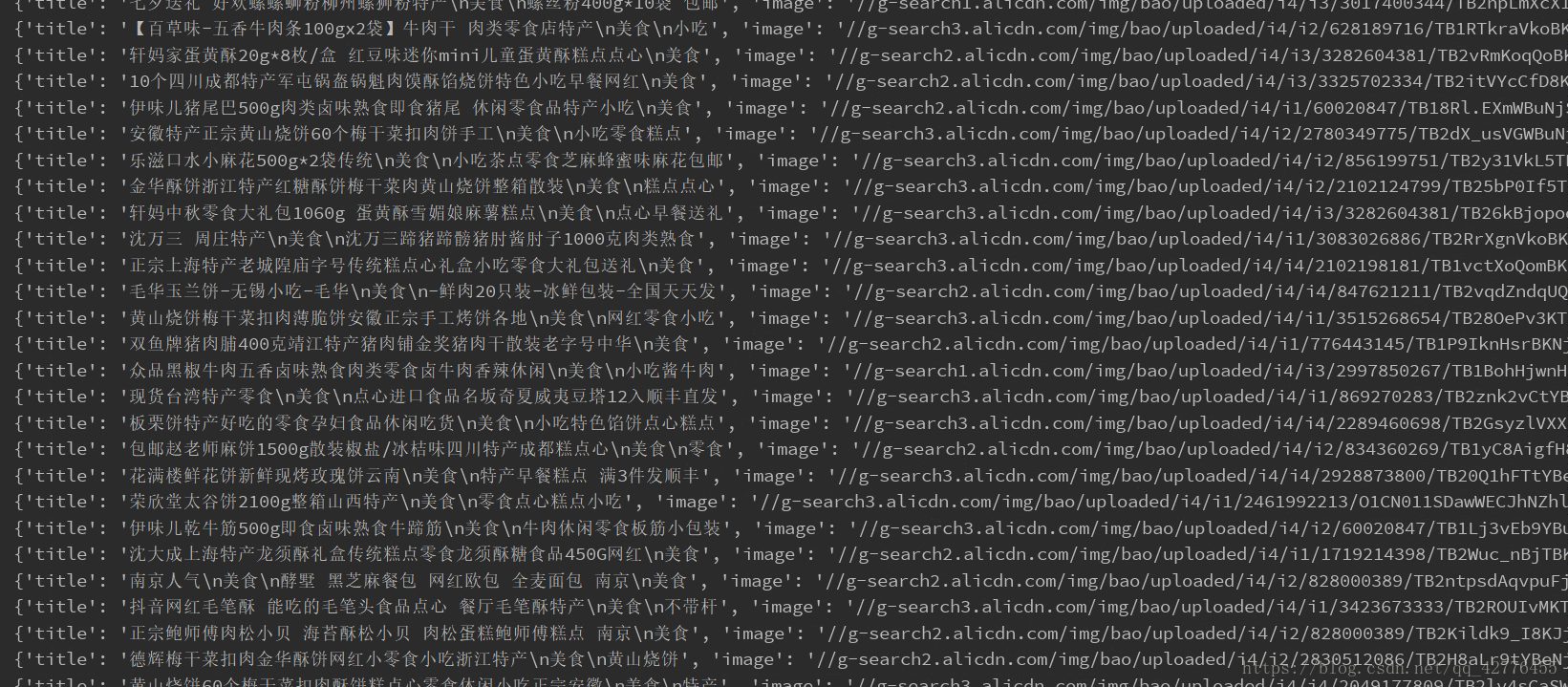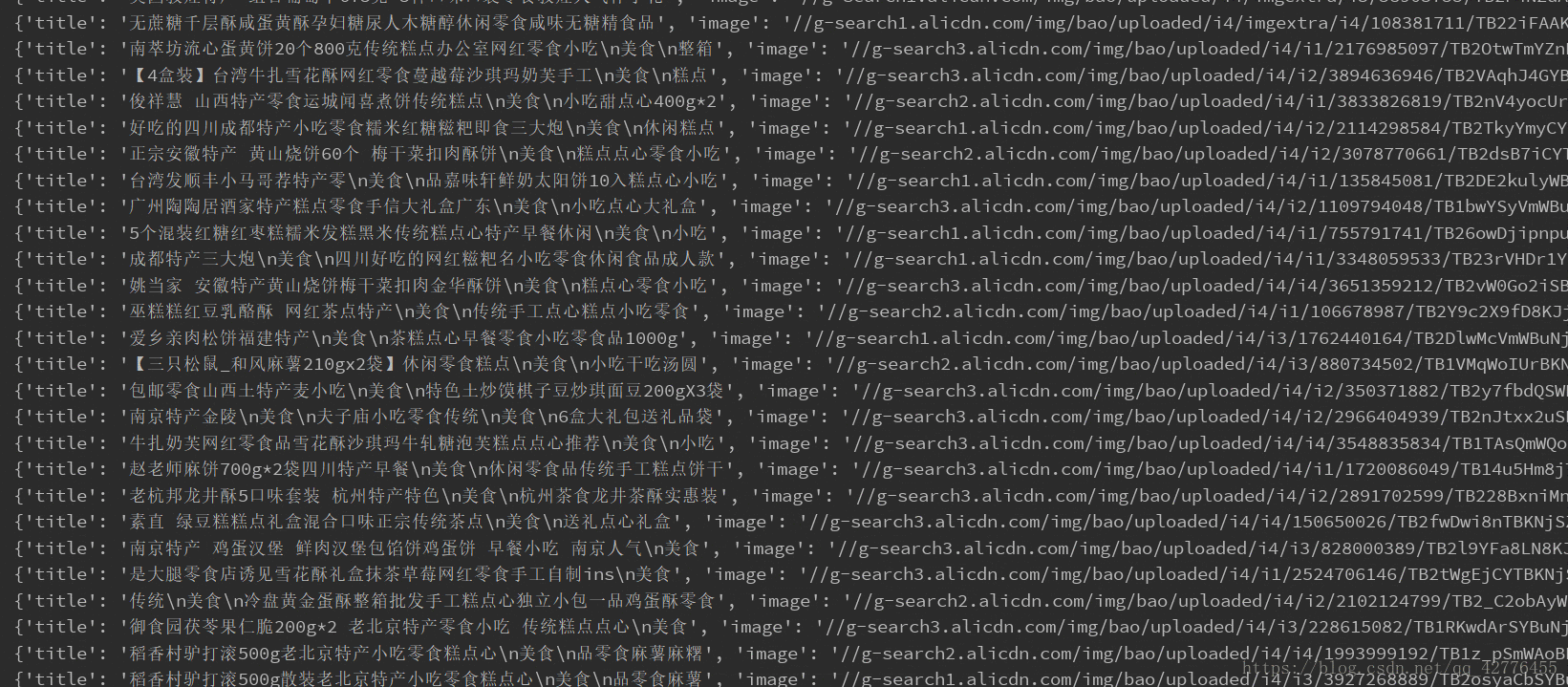
保存到mongodb
def save_to_mongo(product):
try:
if db[MONGO_TABLE].insert(product):
print('储存到mongodb成功',product)
except Exception:
print('储存到mongodb异常',product)
# main函数
def main():
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(1,total+1):
next_page(i)
time.sleep(3)
# 主程序
if __name__ == '__main__':
main()